Largura de Banda da Memória e Térmicas Impulsionam o Desempenho Real de Laptops com AI
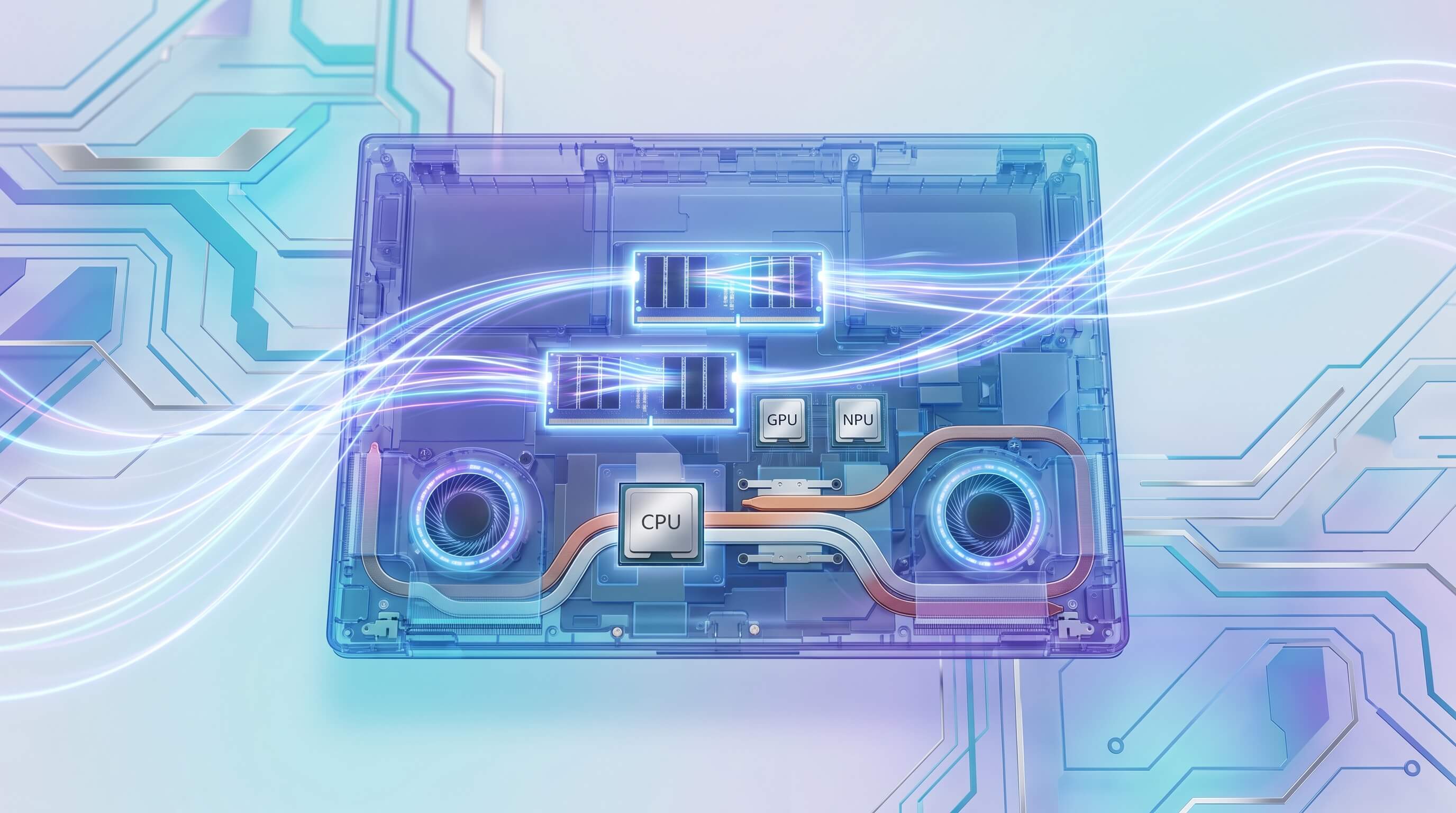
O marketing em torno dos laptops com AI em 2024 e 2025 enfatiza fortemente as Unidades de Processamento Neural (NPUs) e suas classificações de Tera Operations Per Second (TOPS). Com o advento dos PCs Copilot+ exigindo um mínimo de 40 TOPS, os consumidores são levados a acreditar que um alto número de NPU se traduz diretamente em capacidades robustas de AI local. No entanto, esse foco obscurece os verdadeiros gargalos arquitetônicos que ditam o desempenho prático para a execução de grandes modelos de linguagem (LLMs) ou geração de imagens complexas localmente. Embora as NPUs sejam um componente crítico para a inferência de AI com eficiência energética, seu poder de computação bruto é frequentemente anulado por limitações na largura de banda da memória, capacidade de RAM disponível e a capacidade do laptop de sustentar o desempenho sob carga térmica.
Para qualquer carga de trabalho de AI local séria, seja executando um LLM sofisticado como Llama 3 ou gerando imagens de alta resolução com Stable Diffusion, a capacidade do sistema de mover grandes quantidades de dados de forma rápida e eficiente é primordial. Uma NPU poderosa com 40 ou mesmo 70 TOPS ficará ociosa ou subutilizada se não puder ser alimentada com dados rápido o suficiente, ou se o próprio modelo não puder residir totalmente na memória acessível. Este artigo dissecrá os papéis da CPU, GPU e NPU, explicará por que a arquitetura da memória e o design térmico são os heróis desconhecidos do desempenho dos laptops com AI, e fornecerá insights acionáveis para consumidores que buscam ir além do hype de marketing para tomar decisões de compra informadas para 2026 e além.
Além dos TOPS da NPU: Compreendendo o Cenário de Computação de AI
As Unidades de Processamento Neural são aceleradores especializados projetados para lidar eficientemente com multiplicações de matrizes e outras operações comuns em redes neurais. Sua principal vantagem reside em sua eficiência energética para tarefas específicas de inferência de AI, tornando-as ideais para efeitos de fundo como correção de contato visual, supressão de ruído ou segmentação simples de imagens. Empresas como Qualcomm, Intel e AMD estão todas integrando NPUs cada vez mais poderosas em seus processadores móveis, com benchmarks frequentemente destacando seus impressionantes números de TOPS.
No entanto, TOPS por si só representam apenas uma faceta do desempenho da AI. Considere os papéis distintos das três unidades de processamento primárias em um laptop moderno:
- CPU (Central Processing Unit): O "cavalo de batalha" de propósito geral, a CPU orquestra as operações do sistema, gerencia o fluxo de dados e pode executar modelos de AI, particularmente os menores ou aqueles não otimizados para hardware especializado. Ela se destaca em tarefas sensíveis à latência e fornece suporte para cargas de trabalho não adequadas para GPU ou NPU.
- GPU (Graphics Processing Unit): Uma potência de processamento paralelo, as GPUs são indispensáveis para treinar grandes modelos de AI e para executar tarefas complexas de inferência que exigem computação paralela massiva. Sua arquitetura, especialmente com VRAM dedicada, oferece uma largura de banda de memória significativamente maior do que a RAM do sistema típica, tornando-as ideais para LLMs em larga escala e geração de imagens onde os pesos do modelo e os dados intermediários são substanciais.
- NPU (Neural Processing Unit): Otimizadas para padrões específicos de inferência de AI, as NPUs oferecem eficiência energética superior para tarefas recorrentes. Elas são excelentes para descarregar certas computações de AI da CPU ou GPU, estendendo assim a vida útil da bateria e liberando outros recursos. No entanto, sua eficácia depende muito da otimização de software e da arquitetura específica do modelo. Muitos LLMs grandes e não quantizados ou modelos de difusão complexos simplesmente não podem ser executados total ou eficientemente nas NPUs atuais devido ao tamanho do modelo e às limitações arquitetônicas.
A sinergia entre esses componentes é crucial. Uma NPU pode acelerar uma parte específica de um pipeline de AI, mas se as etapas anteriores ou subsequentes forem gargalos pelo desempenho da CPU ou, mais comumente, pelas velocidades de transferência de dados, a experiência geral do usuário será prejudicada.
O Domínio Inegável da Largura de Banda e Capacidade da Memória
Ao executar modelos de AI substanciais localmente, o fator mais crítico frequentemente negligenciado é a memória. Isso engloba tanto a capacidade pura da RAM quanto, ainda mais importante, a velocidade com que os dados podem ser movidos para e da RAM — a largura de banda da memória.
Capacidade de RAM: Mais do que Apenas um Número
Grandes modelos de linguagem são precisamente isso: grandes. Um LLM comum de 7 bilhões de parâmetros, mesmo quando quantizado (precisão reduzida) para inteiros de 4 bits, ainda pode exigir cerca de 8 GB de RAM apenas para seus pesos. Adicione a isso o espaço necessário para ativações, a janela de contexto (a parte do prompt e do texto gerado que o modelo "lembra"), o sistema operacional e outros aplicativos em execução, e 16 GB de RAM rapidamente se tornam um mínimo absoluto, muitas vezes insuficiente para uma experiência suave. Para modelos mais capazes (por exemplo, 13 bilhões de parâmetros ou maiores) ou para executar vários modelos simultaneamente, 32 GB ou mesmo 64 GB de RAM tornam-se essenciais. Sem RAM adequada, o sistema recorre à troca de dados para o armazenamento SSD mais lento, levando a uma degradação significativa do desempenho e interrupções.
Largura de Banda da Memória: O Herói Desconhecido
Mesmo com RAM abundante, se os dados não puderem ser acessados rápido o suficiente, a NPU ou GPU ficará sem dados. A largura de banda da memória mede quantos dados podem ser lidos ou gravados na memória por segundo. Os modelos de AI constantemente embaralham vastas quantidades de dados — pesos do modelo, prompts de entrada, cálculos intermediários e tokens de saída — entre a memória principal e as unidades de processamento. Se a largura de banda da memória for baixa, a NPU ou GPU, apesar de sua alta classificação TOPS, passará uma quantidade desproporcional de tempo esperando por dados, tornando-se efetivamente um gargalo. Isso se traduz diretamente em tempos de Inference mais lentos para LLMs e tempos de geração mais longos para Image models.
Laptops modernos geralmente usam memória LPDDR5X ou DDR5. Embora a LPDDR5X frequentemente ofereça maior largura de banda e melhor eficiência energética do que a DDR5 padrão em um formato móvel, a configuração específica importa. Fatores como o número de canais de memória (por exemplo, interfaces de memória de 256 bits comuns em Apple Silicon, versus interfaces mais estreitas de 128 bits em muitos laptops de PC) e a velocidade do clock da memória impactam significativamente a largura de banda geral. Um processador com uma NPU de alto TOPS emparelhado com um subsistema de memória estreito e de baixa largura de banda inevitavelmente terá um desempenho inferior em comparação com um sistema com uma arquitetura equilibrada, mesmo que este último tenha um número de TOPS NPU teoricamente menor.
Velocidade de Armazenamento: O Obstáculo Inicial
Embora não seja estritamente "memória" no mesmo sentido que a RAM, a velocidade do dispositivo de armazenamento do seu laptop (SSD) desempenha um papel crucial no desempenho da AI. Grandes modelos de AI precisam ser carregados do armazenamento para a RAM antes de poderem ser usados. Um SSD NVMe PCIe Gen4 ou Gen5 rápido garante que esse processo de carregamento inicial seja rápido. Além disso, se a sua capacidade de RAM for insuficiente e o sistema precisar trocar partes do modelo para o disco, um SSD de alta velocidade mitiga o impacto no desempenho, embora ainda seja significativamente mais lento que a RAM.
O Papel Crítico das Térmicas no Desempenho Sustentado
As cargas de trabalho de AI são inerentemente intensivas em computação e frequentemente sustentadas. Ao contrário de tarefas rápidas como abrir um aplicativo ou carregar uma página da web, executar um LLM para gerar uma resposta longa ou iterar em um prompt de geração de imagens pode manter a CPU, GPU e NPU sob carga pesada por períodos prolongados. Essa computação contínua gera calor significativo.
Laptops, por sua própria natureza, são limitados por seus formatos compactos e soluções de resfriamento limitadas. Quando os componentes atingem um certo limite de temperatura, o sistema automaticamente "reduz" o desempenho para evitar superaquecimento e danos potenciais. Isso significa que um laptop com pontuações de benchmark impressionantes por alguns segundos pode reduzir drasticamente suas velocidades de clock e consumo de energia quando confrontado com uma tarefa de AI real e sustentada. A NPU anunciada de 40+ TOPS pode fornecer seu desempenho máximo apenas por um curto período, e depois cair significativamente, levando a uma experiência frustrantemente lenta.
O gerenciamento térmico eficaz — incluindo sistemas de resfriamento robustos com câmaras de vapor, ventiladores maiores e designs eficientes de tubos de calor — é, portanto, primordial. Um laptop projetado para alto desempenho sustentado apresentará uma solução de resfriamento mais avançada, permitindo que a CPU, GPU e NPU operem em velocidades de clock mais altas por durações mais longas. Ao avaliar laptops com AI, olhe além dos números iniciais de benchmark e procure por análises que testem especificamente o desempenho sustentado sob carga pesada e contínua. Essa distinção entre desempenho de pico e desempenho sustentado é um diferencial chave para aplicações práticas de AI.
Implicações Práticas para Cargas de Trabalho de AI Local
Compreender esses gargalos fornece uma imagem mais clara do que esperar de um laptop com AI:
- LLMs: Executar um LLM de 7 bilhões de parâmetros com uma janela de contexto decente localmente exige pelo menos 16 GB de RAM, mas 32 GB proporcionam uma experiência muito mais suave, permitindo janelas de contexto maiores e potencialmente a execução de vários modelos ou outros aplicativos simultaneamente. A velocidade de Inference (tokens por segundo) estará diretamente ligada à largura de banda da memória. Técnicas de Quantization (por exemplo, Q4, Q8) são cruciais para encaixar modelos maiores na RAM disponível, mas vêm com uma troca em precisão ou Perplexity.
- Geração de Imagens: Modelos como Stable Diffusion são altamente exigentes, especialmente para resoluções mais altas ou prompts complexos. Embora as NPUs possam auxiliar em certas etapas de pré-processamento, a geração principal frequentemente depende fortemente da GPU e de sua VRAM dedicada. Laptops sem uma GPU discreta terão dificuldades com a geração de imagens, mesmo com uma NPU de alto TOPS, pois a GPU integrada compartilha a RAM do sistema e sua largura de banda é limitada.
- RAG (Retrieval Augmented Generation): A implementação de sistemas RAG locais envolve o armazenamento de grandes bancos de dados vetoriais (sobrecarregando a velocidade do SSD), o carregamento de partes relevantes na RAM (sobrecarregando a capacidade e a largura de banda da RAM) e, em seguida, o uso de um LLM para geração (sobrecarregando a NPU/GPU/CPU e a memória). Cada componente deve ser robusto para que o RAG seja eficaz.
Enquanto Qualcomm, Intel e AMD estão todos impulsionando suas capacidades de NPU, a arquitetura subjacente do sistema permanece o verdadeiro determinante do desempenho de AI no mundo real. Os chips Snapdragon X Elite/Plus da Qualcomm, por exemplo, ostentam impressionantes TOPS de NPU e excelente eficiência energética, mas sua proeza geral de AI em tarefas exigentes ainda dependerá do subsistema de memória com o qual são emparelhados. Da mesma forma, os processadores Core Ultra (Meteor Lake) e os próximos Lunar Lake da Intel, e os chips Ryzen AI da AMD, integram NPUs poderosas juntamente com CPUs capazes e GPUs integradas. O equilíbrio entre esses componentes, particularmente a largura de banda da memória e o design térmico, é o que realmente importa.
Conclusões Acionáveis: Priorizando Especificações para Seu Próximo Laptop com AI (2026)
Ao considerar um laptop com AI, olhe além do número de TOPS da NPU. Aqui está o que priorizar para um desempenho de AI local verdadeiramente capaz:
- A Capacidade de RAM é Fundamental: Procure um mínimo de 32 GB de RAM. Se o seu orçamento permitir e a AI local for um foco principal, 64 GB proporcionarão significativamente mais espaço para modelos maiores e fluxos de trabalho complexos.
- Alta Largura de Banda da Memória: Procure laptops com memória LPDDR5X ou DDR5 de alta velocidade. Investigue a largura da interface de memória, se possível; interfaces mais amplas (por exemplo, 256 bits) oferecem largura de banda superior. Essa especificação é frequentemente menos anunciada, mas é crítica.
- Sistema de Resfriamento Robusto: Procure análises profissionais que testem o desempenho sustentado sob cargas pesadas de CPU, GPU e NPU. Um laptop que mantém altas velocidades de clock por períodos prolongados sem throttling é um forte indicador de um bom design térmico.
- SSD NVMe Rápido: Certifique-se de que seu laptop venha com um SSD NVMe PCIe Gen4 ou, idealmente, Gen5. Isso acelera o carregamento do modelo e mitiga quedas de desempenho se o sistema precisar trocar dados.
- Considere uma GPU Discreta para Tarefas Específicas: Se o seu caso de uso principal de AI local envolve geração de imagens pesadas ou LLMs muito grandes que se beneficiam de VRAM dedicada, um laptop com uma GPU discreta (mesmo de médio porte) oferecerá desempenho superior em comparação com a dependência exclusiva de uma GPU integrada e uma NPU.
- TOPS da NPU como Linha de Base: Trate o requisito de 40+ TOPS para Copilot+ como um ponto de entrada necessário, mas não como o único diferencial. Uma vez que essa linha de base seja atendida, concentre sua atenção nos outros componentes do sistema que realmente desbloqueiam o potencial da NPU.
O futuro da AI em laptops é promissor, mas navegar no cenário de marketing exige uma compreensão mais profunda dos princípios de hardware subjacentes. Ao priorizar a largura de banda da memória, a capacidade de RAM e o gerenciamento térmico, juntamente com as capacidades da NPU, os consumidores podem escolher um laptop que cumpra a promessa de uma AI local poderosa e eficiente.