پهنای باند حافظه و مدیریت حرارتی، عملکرد واقعی لپتاپهای هوش مصنوعی را تعیین میکنند
بازاریابی پیرامون لپتاپهای AI در سالهای 2024 و 2025 به شدت بر واحدهای پردازش عصبی (NPU) و نرخ Tera Operations Per Second (TOPS) آنها تأکید دارد. با ظهور رایانههای Copilot+ که حداقل 40 TOPS نیاز دارند، مصرفکنندگان به این باور سوق داده میشوند که یک عدد NPU بالا مستقیماً به قابلیتهای قدرتمند AI محلی ترجمه میشود. با این حال، این تمرکز، تنگناهای معماری واقعی را که عملکرد عملی برای اجرای مدلهای زبان بزرگ (LLM) یا تولید تصویر پیچیده به صورت محلی را دیکته میکنند، پنهان میکند. در حالی که NPUs یک جزء حیاتی برای استنتاج AI با بهرهوری انرژی هستند، قدرت محاسباتی خام آنها اغلب به دلیل محدودیتها در پهنای باند حافظه، ظرفیت RAM موجود و توانایی لپتاپ برای حفظ عملکرد تحت بار حرارتی، بیاثر میشود.
برای هر بار کاری جدی AI محلی، چه اجرای یک LLM پیچیده مانند Llama 3 و چه تولید تصاویر با وضوح بالا با Stable Diffusion، توانایی سیستم برای انتقال حجم عظیمی از دادهها به سرعت و کارآمدی بسیار مهم است. یک NPU قدرتمند با 40 یا حتی 70 TOPS بیکار یا کمکار خواهد ماند اگر نتواند دادهها را به اندازه کافی سریع دریافت کند، یا اگر خود مدل نتواند به طور کامل در حافظه قابل دسترس قرار گیرد. این مقاله نقشهای CPU، GPU و NPU را تشریح میکند، توضیح میدهد که چرا معماری حافظه و طراحی حرارتی قهرمانان گمنام عملکرد لپتاپهای AI هستند و بینشهای عملی را برای مصرفکنندگانی که فراتر از هیاهوی بازاریابی به دنبال تصمیمگیری آگاهانه برای خرید در سال 2026 و پس از آن هستند، ارائه میدهد.
فراتر از TOPS NPU: درک چشمانداز محاسبات AI
واحدهای پردازش عصبی شتابدهندههای تخصصی هستند که برای مدیریت کارآمد ضرب ماتریس و سایر عملیات رایج در شبکههای عصبی طراحی شدهاند. مزیت اصلی آنها در بهرهوری انرژی برای وظایف خاص استنتاج AI نهفته است، که آنها را برای جلوههای پسزمینه مانند تصحیح تماس چشمی، سرکوب نویز یا تقسیمبندی ساده تصویر ایدهآل میکند. شرکتهایی مانند Qualcomm، Intel و AMD همگی NPUs قدرتمندتری را در پردازندههای موبایل خود ادغام میکنند، با بنچمارکهایی که اغلب ارقام TOPS چشمگیر آنها را برجسته میکنند.
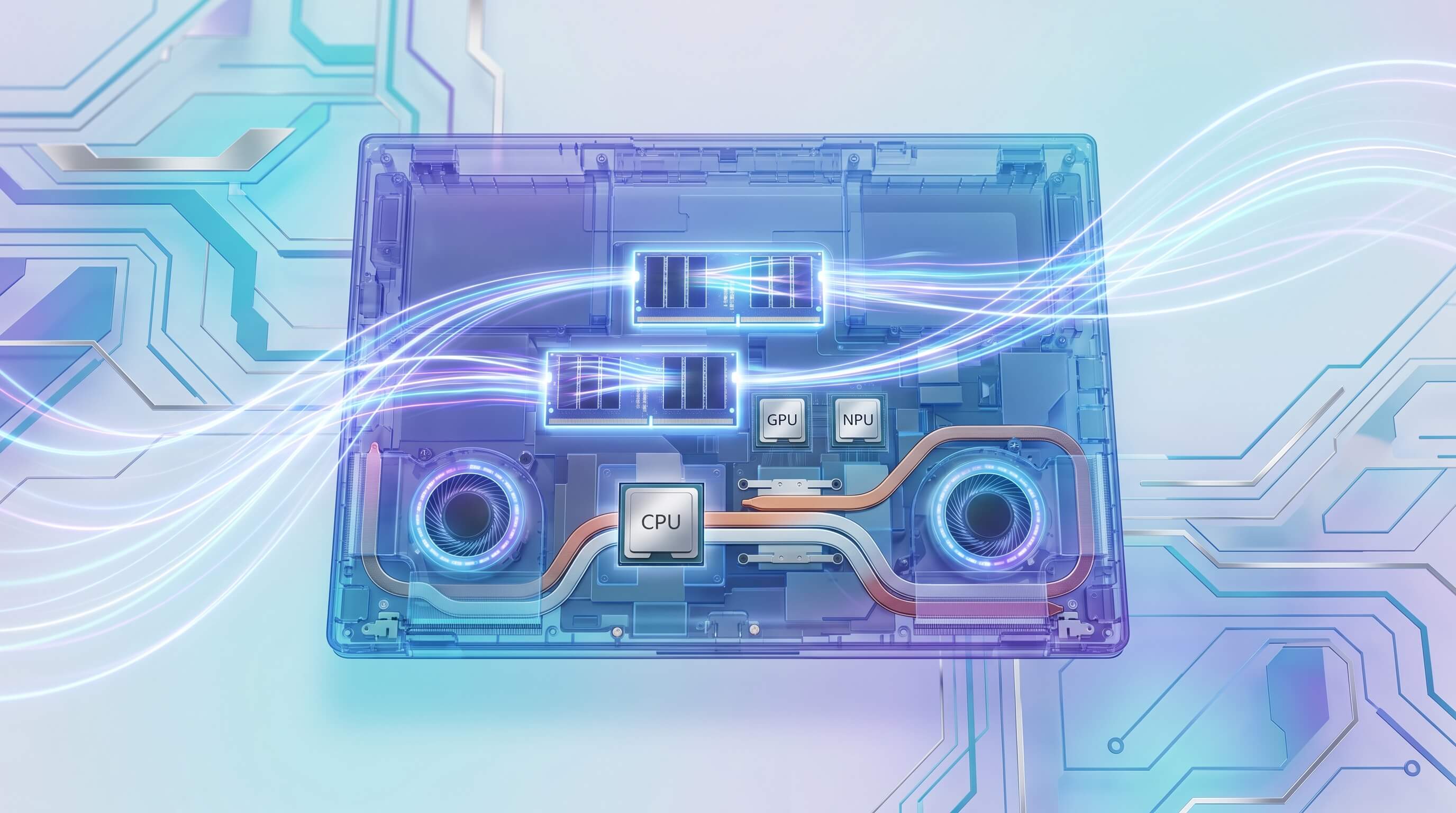
با این حال، TOPS به تنهایی تنها یک جنبه از عملکرد AI را نشان میدهد. نقشهای متمایز سه واحد پردازش اصلی در یک لپتاپ مدرن را در نظر بگیرید:
- CPU (Central Processing Unit): اسب کار عمومی، CPU عملیات سیستم را هماهنگ میکند، جریان دادهها را مدیریت میکند و میتواند مدلهای AI را اجرا کند، به ویژه مدلهای کوچکتر یا آنهایی که برای سختافزار تخصصی بهینه نشدهاند. در وظایف حساس به تأخیر عالی عمل میکند و برای بارهایی که برای GPU یا NPU مناسب نیستند، پشتیبانی فراهم میکند.
- GPU (Graphics Processing Unit): یک نیروگاه پردازش موازی، GPUها برای آموزش مدلهای بزرگ AI و برای اجرای وظایف استنتاج پیچیده که نیاز به محاسبات موازی عظیم دارند، ضروری هستند. معماری آنها، به ویژه با VRAM اختصاصی، پهنای باند حافظه بسیار بالاتری نسبت به RAM سیستم معمولی ارائه میدهد، که آنها را برای LLMهای در مقیاس بزرگ و تولید تصویر که وزن مدل و دادههای میانی قابل توجه هستند، ایدهآل میکند.
- NPU (Neural Processing Unit): بهینه شده برای الگوهای استنتاج AI خاص، NPUs بهرهوری انرژی بالاتری را برای وظایف تکراری ارائه میدهند. آنها برای تخلیه برخی از محاسبات AI از CPU یا GPU عالی هستند، در نتیجه عمر باتری را افزایش میدهند و منابع دیگر را آزاد میکنند. با این حال، اثربخشی آنها به شدت به بهینهسازی نرمافزار و معماری مدل خاص بستگی دارد. بسیاری از LLMهای بزرگ و غیرکوانتیزه شده یا مدلهای انتشار پیچیده به سادگی نمیتوانند به طور کامل یا کارآمد بر روی NPUs فعلی به دلیل اندازه مدل و محدودیتهای معماری اجرا شوند.
همافزایی بین این اجزا بسیار مهم است. یک NPU ممکن است بخش خاصی از یک خط لوله AI را تسریع کند، اما اگر مراحل قبلی یا بعدی توسط عملکرد CPU یا، به طور معمول، توسط سرعت انتقال دادهها با تنگنا مواجه شوند، تجربه کلی کاربر آسیب میبیند.
تسلط انکارناپذیر پهنای باند و ظرفیت حافظه
هنگام اجرای مدلهای AI قابل توجه به صورت محلی، مهمترین عاملی که اغلب نادیده گرفته میشود، حافظه است. این شامل ظرفیت خالص RAM و، حتی مهمتر، سرعتی است که دادهها میتوانند به و از آن RAM منتقل شوند — پهنای باند حافظه.
ظرفیت RAM: فراتر از یک عدد
مدلهای زبان بزرگ دقیقاً همین هستند: بزرگ. یک LLM 7 میلیارد پارامتری رایج، حتی زمانی که به 4 بیت عدد صحیح کوانتیزه (دقت کاهش یافته) شود، همچنان به حدود 8 گیگابایت RAM فقط برای وزنهای خود نیاز دارد. فضای مورد نیاز برای فعالسازیها، پنجره زمینه (بخشی از اعلان و متن تولید شده که مدل "به یاد میآورد")، سیستم عامل و سایر برنامههای در حال اجرا را به این اضافه کنید، و 16 گیگابایت RAM به سرعت به حداقل مطلق تبدیل میشود، که اغلب برای یک تجربه روان کافی نیست. برای مدلهای با قابلیت بیشتر (مثلاً 13 میلیارد پارامتر یا بزرگتر) یا برای اجرای چندین مدل به طور همزمان، 32 گیگابایت یا حتی 64 گیگابایت RAM ضروری میشود. بدون RAM کافی، سیستم به مبادله دادهها با حافظه SSD کندتر متوسل میشود که منجر به کاهش قابل توجه عملکرد و لکنت میشود.
پهنای باند حافظه: قهرمان گمنام
حتی با وجود RAM فراوان، اگر دادهها به اندازه کافی سریع قابل دسترسی نباشند، NPU یا GPU با کمبود داده مواجه خواهد شد. پهنای باند حافظه میزان دادهای را که میتوان در هر ثانیه از حافظه خواند یا در آن نوشت، اندازهگیری میکند. مدلهای AI به طور مداوم مقادیر زیادی از دادهها — وزنهای مدل، اعلانهای ورودی، محاسبات میانی و توکنهای خروجی — را بین حافظه اصلی و واحدهای پردازش جابجا میکنند. اگر پهنای باند حافظه پایین باشد، NPU یا GPU، با وجود نرخ TOPS بالای خود، زمان نامتناسبی را صرف انتظار برای دادهها خواهد کرد و عملاً با تنگنا مواجه میشود. این مستقیماً به زمانهای استنتاج کندتر برای LLMها و زمانهای تولید طولانیتر برای مدلهای تصویر ترجمه میشود.
لپتاپهای مدرن معمولاً از حافظه LPDDR5X یا DDR5 استفاده میکنند. در حالی که LPDDR5X اغلب پهنای باند بالاتر و بهرهوری انرژی بهتری نسبت به DDR5 استاندارد در فرم فاکتور موبایل ارائه میدهد، پیکربندی خاص مهم است. عواملی مانند تعداد کانالهای حافظه (مثلاً رابطهای حافظه 256 بیتی رایج در Apple Silicon، در مقابل رابطهای 128 بیتی باریکتر در بسیاری از لپتاپهای PC) و سرعت کلاک حافظه به طور قابل توجهی بر پهنای باند کلی تأثیر میگذارند. یک پردازنده با NPU با TOPS بالا که با یک زیرسیستم حافظه باریک و با پهنای باند پایین جفت شده است، به ناچار نسبت به سیستمی با معماری متعادل، حتی اگر دومی دارای عدد TOPS NPU نظری پایینتری باشد، عملکرد ضعیفتری خواهد داشت.
سرعت ذخیرهسازی: مانع اولیه
در حالی که به معنای دقیق "حافظه" مانند RAM نیست، سرعت دستگاه ذخیرهسازی لپتاپ شما (SSD) نقش مهمی در عملکرد AI ایفا میکند. مدلهای بزرگ AI باید قبل از استفاده از ذخیرهسازی به RAM بارگذاری شوند. یک SSD سریع NVMe PCIe Gen4 یا Gen5 تضمین میکند که این فرآیند بارگذاری اولیه سریع است. علاوه بر این، اگر ظرفیت RAM شما ناکافی باشد و سیستم نیاز به مبادله بخشهایی از مدل با دیسک داشته باشد، یک SSD با سرعت بالا افت عملکرد را کاهش میدهد، اگرچه هنوز به طور قابل توجهی کندتر از RAM است.
نقش حیاتی حرارت در عملکرد پایدار
بارهای کاری AI ذاتاً محاسباتی فشرده و اغلب پایدار هستند. برخلاف وظایف ناگهانی مانند باز کردن یک برنامه یا بارگذاری یک صفحه وب، اجرای یک LLM برای تولید یک پاسخ طولانی یا تکرار یک اعلان تولید تصویر میتواند CPU، GPU و NPU را برای دورههای طولانی تحت بار سنگین نگه دارد. این محاسبات مداوم گرمای قابل توجهی تولید میکند.
لپتاپها، به دلیل ماهیت خود، توسط فرم فاکتورهای فشرده و راهحلهای خنککننده محدود خود محدود میشوند. هنگامی که اجزا به یک آستانه دمایی خاص میرسند، سیستم به طور خودکار عملکرد را "محدود" میکند تا از گرمای بیش از حد و آسیب احتمالی جلوگیری کند. این بدان معناست که یک لپتاپ که برای چند ثانیه نمرات بنچمارک چشمگیری را به خود اختصاص میدهد، ممکن است سرعت کلاک و مصرف برق خود را به شدت کاهش دهد هنگامی که با یک کار AI واقعی و پایدار مواجه میشود. NPU با 40+ TOPS تبلیغ شده ممکن است فقط برای یک دوره کوتاه عملکرد اوج خود را ارائه دهد، سپس به طور قابل توجهی کاهش یابد، که منجر به تجربهای ناامیدکننده کند میشود.
مدیریت حرارتی مؤثر — از جمله سیستمهای خنککننده قوی با محفظههای بخار، فنهای بزرگتر و طراحی لولههای حرارتی کارآمد — بنابراین بسیار مهم است. یک لپتاپ که برای عملکرد پایدار بالا طراحی شده است، دارای یک راهحل خنککننده پیشرفتهتر خواهد بود که به CPU، GPU و NPU اجازه میدهد تا با سرعت کلاک بالاتر برای مدت زمان طولانیتری کار کنند. هنگام ارزیابی لپتاپهای AI، فراتر از اعداد بنچمارک اولیه نگاه کنید و به دنبال بررسیهایی باشید که به طور خاص عملکرد پایدار را تحت بار سنگین و مداوم آزمایش میکنند. این تمایز بین عملکرد لحظهای و پایدار یک عامل کلیدی برای برنامههای کاربردی AI عملی است.
پیامدهای عملی برای بارهای کاری AI محلی
درک این تنگناها تصویر واضحتری از آنچه باید از یک لپتاپ AI انتظار داشت، ارائه میدهد:
- LLMs: اجرای یک LLM 7 میلیارد پارامتری با یک پنجره زمینه مناسب به صورت محلی حداقل 16 گیگابایت RAM نیاز دارد، اما 32 گیگابایت تجربه بسیار روانتری را فراهم میکند، که امکان پنجرههای زمینه بزرگتر و احتمالاً اجرای چندین مدل یا سایر برنامهها را به طور همزمان میدهد. سرعت Inference (توکن در ثانیه) مستقیماً به پهنای باند حافظه گره خورده است. تکنیکهای Quantization (مانند Q4، Q8) برای جای دادن مدلهای بزرگتر در RAM موجود بسیار مهم هستند، اما با یک معاوضه در دقت یا Perplexity همراه هستند.
- تولید تصویر: مدلهایی مانند Stable Diffusion بسیار پرتقاضا هستند، به ویژه برای وضوحهای بالاتر یا اعلانهای پیچیده. در حالی که NPUs ممکن است در برخی مراحل پیشپردازش کمک کنند، تولید اصلی اغلب به شدت به GPU و VRAM اختصاصی آن متکی است. لپتاپهای بدون GPU مجزا با تولید تصویر مشکل خواهند داشت، حتی با NPU با TOPS بالا، زیرا GPU یکپارچه RAM سیستم را به اشتراک میگذارد و پهنای باند آن محدود است.
- RAG (Retrieval Augmented Generation): پیادهسازی سیستمهای RAG محلی شامل ذخیرهسازی پایگاههای داده برداری بزرگ (فشار بر سرعت SSD)، بارگذاری قطعات مربوطه در RAM (فشار بر ظرفیت RAM و پهنای باند) و سپس استفاده از یک LLM برای تولید (فشار بر NPU/GPU/CPU و حافظه) است. هر جزء باید برای مؤثر بودن RAG قوی باشد.
در حالی که Qualcomm، Intel و AMD همگی قابلیتهای NPU خود را پیش میبرند، معماری سیستم زیربنایی همچنان تعیینکننده واقعی عملکرد AI در دنیای واقعی است. به عنوان مثال، تراشههای Snapdragon X Elite/Plus کوالکام، TOPS NPU چشمگیر و بهرهوری انرژی عالی را به خود اختصاص میدهند، اما قدرت کلی AI آنها در وظایف پرتقاضا همچنان به زیرسیستم حافظهای که با آن جفت شدهاند، بستگی دارد. به طور مشابه، پردازندههای Core Ultra (Meteor Lake) و Lunar Lake آینده اینتل، و تراشههای Ryzen AI AMD، NPUs قدرتمند را در کنار CPUهای توانا و GPUهای یکپارچه ادغام میکنند. تعادل بین این اجزا، به ویژه پهنای باند حافظه و طراحی حرارتی، چیزی است که در نهایت اهمیت دارد.
نکات عملی: اولویتبندی مشخصات برای لپتاپ AI بعدی شما (2026)
هنگام در نظر گرفتن یک لپتاپ AI، فراتر از عدد TOPS NPU تیتروار نگاه کنید. در اینجا آنچه را که باید برای عملکرد AI محلی واقعاً توانمند اولویتبندی کنید، آمده است:
- ظرفیت RAM پادشاه است: حداقل 32 گیگابایت RAM را هدف قرار دهید. اگر بودجه شما اجازه میدهد و AI محلی یک تمرکز اصلی است، 64 گیگابایت فضای بسیار بیشتری برای مدلهای بزرگتر و گردش کار پیچیده فراهم میکند.
- پهنای باند حافظه بالا: به دنبال لپتاپهایی باشید که دارای حافظه LPDDR5X یا DDR5 با سرعت بالا هستند. در صورت امکان، عرض رابط حافظه را بررسی کنید؛ رابطهای گستردهتر (مانند 256 بیتی) پهنای باند برتری را ارائه میدهند. این مشخصات اغلب کمتر تبلیغ میشود اما حیاتی است.
- سیستم خنککننده قوی: به دنبال بررسیهای حرفهای باشید که عملکرد پایدار را تحت بارهای سنگین CPU، GPU و NPU آزمایش میکنند. لپتاپی که سرعت کلاک بالا را برای دورههای طولانی بدون throttling حفظ میکند، یک نشانگر قوی از طراحی حرارتی خوب است.
- SSD سریع NVMe: اطمینان حاصل کنید که لپتاپ شما دارای یک SSD NVMe PCIe Gen4 یا، در حالت ایدهآل، Gen5 است. این کار بارگذاری مدل را تسریع میکند و کاهش عملکرد را در صورت نیاز سیستم به مبادله دادهها کاهش میدهد.
- GPU مجزا را برای وظایف خاص در نظر بگیرید: اگر مورد استفاده اصلی AI محلی شما شامل تولید تصویر سنگین یا LLMهای بسیار بزرگ است که از VRAM اختصاصی بهره میبرند، یک لپتاپ با GPU مجزا (حتی یک مدل میانرده) عملکرد برتری را در مقایسه با اتکا صرف به GPU یکپارچه و NPU ارائه خواهد داد.
- TOPS NPU به عنوان یک خط پایه: نیاز 40+ TOPS برای Copilot+ را به عنوان یک نقطه ورود ضروری در نظر بگیرید، اما نه تنها عامل تمایز. هنگامی که این خط پایه برآورده شد، توجه خود را بر روی سایر اجزای سیستم که واقعاً پتانسیل NPU را آزاد میکنند، متمرکز کنید.
آینده AI در لپتاپها روشن است، اما پیمایش در چشمانداز بازاریابی نیاز به درک عمیقتری از اصول سختافزاری زیربنایی دارد. با اولویتبندی پهنای باند حافظه، ظرفیت RAM و مدیریت حرارتی در کنار قابلیتهای NPU، مصرفکنندگان میتوانند لپتاپی را انتخاب کنند که به وعده AI محلی قدرتمند و کارآمد عمل کند.