El Ancho de Banda de la Memoria y la Gestión Térmica Impulsan el Rendimiento Real de los Portátiles con IA
El marketing en torno a los portátiles con AI en 2024 y 2025 enfatiza en gran medida las Unidades de Procesamiento Neuronal (NPU) y sus clasificaciones de Tera Operaciones Por Segundo (TOPS). Con la llegada de los PC Copilot+ que requieren un mínimo de 40 TOPS, se lleva a los consumidores a creer que un número alto de NPU se traduce directamente en sólidas capacidades de AI local. Sin embargo, este enfoque oculta los verdaderos cuellos de botella arquitectónicos que dictan el rendimiento práctico para ejecutar modelos de lenguaje grandes (LLMs) o la generación de imágenes complejas localmente. Si bien las NPUs son un componente crítico para la inferencia de AI eficiente en energía, su poder de cómputo bruto a menudo se vuelve inútil debido a las limitaciones en el ancho de banda de la memoria, la capacidad de RAM disponible y la capacidad del portátil para mantener el rendimiento bajo carga térmica.
Para cualquier carga de trabajo de AI local seria, ya sea ejecutar un LLM sofisticado como Llama 3 o generar imágenes de alta resolución con Stable Diffusion, la capacidad del sistema para mover grandes cantidades de datos de forma rápida y eficiente es primordial. Una NPU potente con 40 o incluso 70 TOPS permanecerá inactiva o infrautilizada si no se le pueden alimentar datos lo suficientemente rápido, o si el modelo mismo no puede residir completamente en la memoria accesible. Este artículo analizará los roles de la CPU, GPU y NPU, explicará por qué la arquitectura de la memoria y el diseño térmico son los héroes anónimos del rendimiento de los portátiles con AI, y proporcionará información práctica para los consumidores que buscan ir más allá del bombo publicitario para tomar decisiones de compra informadas para 2026 y más allá.
Más allá de los TOPS de la NPU: Entendiendo el Panorama de la Computación con AI
Las Unidades de Procesamiento Neuronal son aceleradores especializados diseñados para manejar eficientemente multiplicaciones de matrices y otras operaciones comunes en redes neuronales. Su principal ventaja radica en su eficiencia energética para tareas específicas de inferencia de AI, lo que las hace ideales para efectos de fondo como la corrección del contacto visual, la supresión de ruido o la segmentación simple de imágenes. Empresas como Qualcomm, Intel y AMD están integrando NPUs cada vez más potentes en sus procesadores móviles, y los benchmarks a menudo destacan sus impresionantes cifras de TOPS.
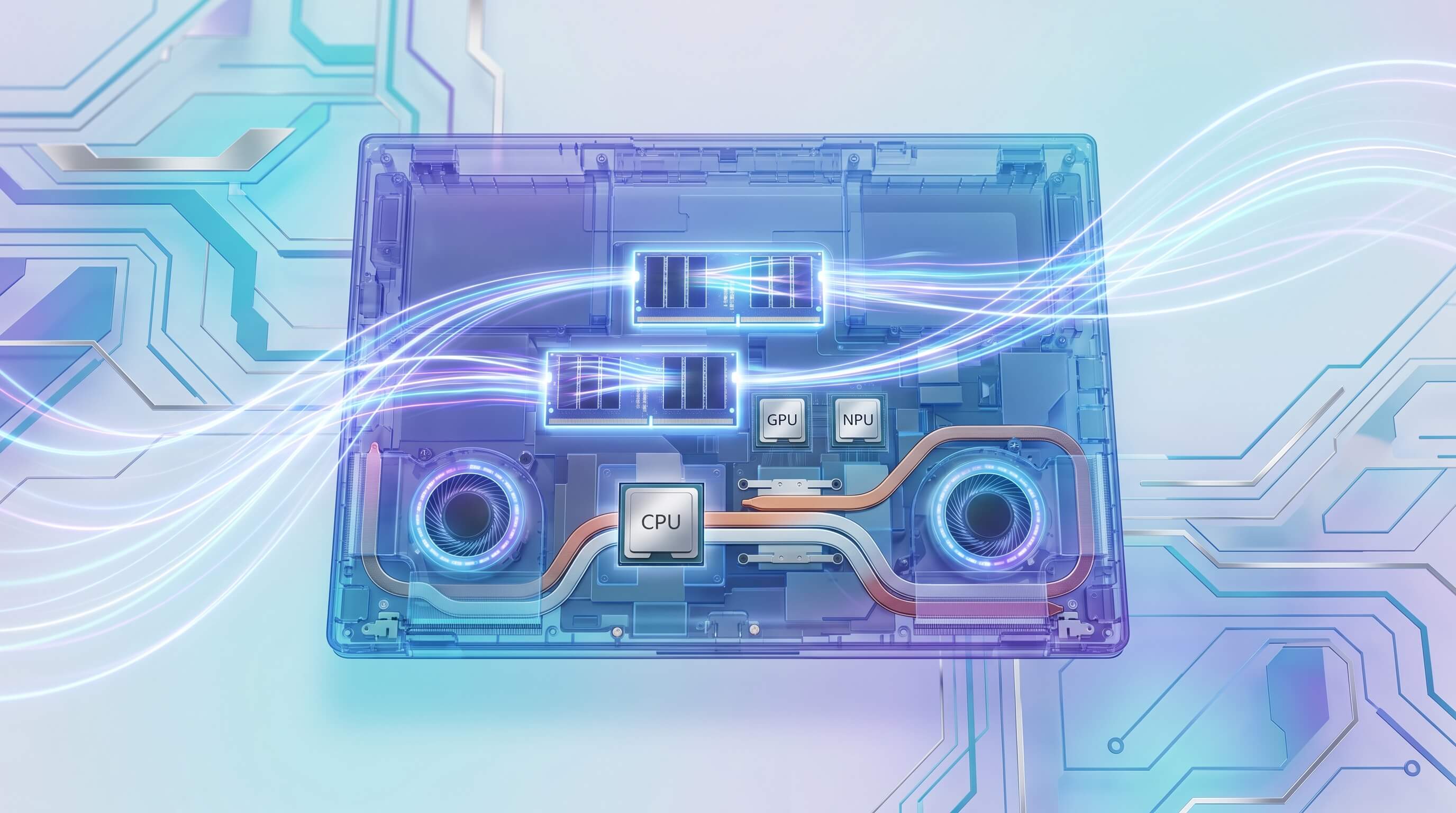
Sin embargo, los TOPS por sí solos representan solo una faceta del rendimiento de la AI. Considere los roles distintos de las tres unidades de procesamiento principales en un portátil moderno:
- CPU (Unidad Central de Procesamiento): El caballo de batalla de propósito general, la CPU orquesta las operaciones del sistema, gestiona el flujo de datos y puede ejecutar modelos de AI, particularmente los más pequeños o aquellos no optimizados para hardware especializado. Destaca en tareas sensibles a la latencia y proporciona respaldo para cargas de trabajo no adecuadas para GPU o NPU.
- GPU (Unidad de Procesamiento Gráfico): Una potencia de procesamiento paralelo, las GPUs son indispensables para entrenar grandes modelos de AI y para ejecutar tareas complejas de inferencia que requieren una computación paralela masiva. Su arquitectura, especialmente con VRAM dedicada, ofrece un ancho de banda de memoria significativamente mayor que la RAM del sistema típica, lo que las hace ideales para LLMs a gran escala y la generación de imágenes donde los pesos del modelo y los datos intermedios son sustanciales.
- NPU (Unidad de Procesamiento Neuronal): Optimizadas para patrones específicos de inferencia de AI, las NPUs ofrecen una eficiencia energética superior para tareas recurrentes. Son excelentes para descargar ciertas computaciones de AI de la CPU o GPU, extendiendo así la duración de la batería y liberando otros recursos. Sin embargo, su eficacia depende en gran medida de la optimización del software y de la arquitectura específica del modelo. Muchos LLMs grandes no cuantificados o modelos de difusión complejos simplemente no pueden ejecutarse de forma completa o eficiente en las NPUs actuales debido al tamaño del modelo y las limitaciones arquitectónicas.
La sinergia entre estos componentes es crucial. Una NPU podría acelerar una parte específica de un pipeline de AI, pero si los pasos anteriores o posteriores están limitados por el rendimiento de la CPU o, más comúnmente, por las velocidades de transferencia de datos, la experiencia general del usuario se ve afectada.
El Dominio Innegable del Ancho de Banda y la Capacidad de la Memoria
Al ejecutar modelos de AI sustanciales localmente, el factor más crítico que a menudo se pasa por alto es la memoria. Esto abarca tanto la capacidad pura de la RAM como, lo que es aún más importante, la velocidad a la que los datos pueden moverse hacia y desde esa RAM: el ancho de banda de la memoria.
Capacidad de RAM: Más que un Número
Los modelos de lenguaje grandes son precisamente eso: grandes. Un LLM común de 7 mil millones de parámetros, incluso cuando se cuantifica (precisión reducida) a enteros de 4 bits, aún puede requerir alrededor de 8GB de RAM solo para sus pesos. Agregue a esto el espacio necesario para las activaciones, la ventana de contexto (la porción del prompt y el texto generado que el modelo "recuerda"), el sistema operativo y otras aplicaciones en ejecución, y 16GB de RAM se convierte rápidamente en un mínimo absoluto, a menudo insuficiente para una experiencia fluida. Para modelos más capaces (por ejemplo, 13B parámetros o más grandes) o para ejecutar múltiples modelos simultáneamente, 32GB o incluso 64GB de RAM se vuelven esenciales. Sin suficiente RAM, el sistema recurre a intercambiar datos con el almacenamiento SSD más lento, lo que lleva a una degradación significativa del rendimiento y a tartamudeos.
Ancho de Banda de la Memoria: El Héroe Anónimo
Incluso con abundante RAM, si no se puede acceder a los datos lo suficientemente rápido, la NPU o GPU se quedará sin datos. El ancho de banda de la memoria mide cuántos datos se pueden leer o escribir en la memoria por segundo. Los modelos de AI constantemente mueven grandes cantidades de datos (pesos del modelo, prompts de entrada, cálculos intermedios y tokens de salida) entre la memoria principal y las unidades de procesamiento. Si el ancho de banda de la memoria es bajo, la NPU o GPU, a pesar de su alta clasificación TOPS, pasará una cantidad desproporcionada de tiempo esperando datos, lo que la convertirá en un cuello de botella efectivo. Esto se traduce directamente en tiempos de inferencia más lentos para los LLMs y tiempos de generación más largos para los modelos de imágenes.
Los portátiles modernos suelen utilizar memoria LPDDR5X o DDR5. Si bien LPDDR5X a menudo ofrece un ancho de banda más alto y una mejor eficiencia energética que la DDR5 estándar en un factor de forma móvil, la configuración específica importa. Factores como el número de canales de memoria (por ejemplo, interfaces de memoria de 256 bits comunes en Apple Silicon, frente a interfaces más estrechas de 128 bits en muchos portátiles de PC) y la velocidad de reloj de la memoria impactan significativamente el ancho de banda general. Un procesador con una NPU de altos TOPS emparejado con un subsistema de memoria estrecho y de bajo ancho de banda inevitablemente tendrá un rendimiento inferior en comparación con un sistema con una arquitectura equilibrada, incluso si este último tiene un número de TOPS de NPU teóricamente más bajo.
Velocidad de Almacenamiento: El Obstáculo Inicial
Aunque no es estrictamente "memoria" en el mismo sentido que la RAM, la velocidad del dispositivo de almacenamiento de su portátil (SSD) juega un papel crucial en el rendimiento de la AI. Los modelos de AI grandes deben cargarse desde el almacenamiento a la RAM antes de poder usarse. Un SSD NVMe PCIe Gen4 o Gen5 rápido garantiza que este proceso de carga inicial sea rápido. Además, si su capacidad de RAM es insuficiente y el sistema necesita intercambiar partes del modelo al disco, un SSD de alta velocidad mitiga el impacto en el rendimiento, aunque sigue siendo significativamente más lento que la RAM.
El Papel Crítico de la Gestión Térmica en el Rendimiento Sostenido
Las cargas de trabajo de AI son inherentemente intensivas en cómputo y a menudo sostenidas. A diferencia de las tareas intermitentes como abrir una aplicación o cargar una página web, ejecutar un LLM para generar una respuesta larga o iterar en un prompt de generación de imágenes puede mantener la CPU, GPU y NPU bajo una carga pesada durante períodos prolongados. Esta computación continua genera un calor significativo.
Los portátiles, por su propia naturaleza, están limitados por sus factores de forma compactos y sus soluciones de refrigeración limitadas. Cuando los componentes alcanzan un cierto umbral de temperatura, el sistema automáticamente "limita" el rendimiento para evitar el sobrecalentamiento y posibles daños. Esto significa que un portátil que presume de impresionantes puntuaciones de benchmark durante unos segundos podría reducir drásticamente sus velocidades de reloj y consumo de energía cuando se enfrenta a una tarea de AI sostenida y del mundo real. La NPU anunciada de 40+ TOPS podría ofrecer su rendimiento máximo solo por un breve período, para luego caer significativamente, lo que lleva a una experiencia frustrantemente lenta.
Por lo tanto, una gestión térmica efectiva, que incluya sistemas de refrigeración robustos con cámaras de vapor, ventiladores más grandes y diseños eficientes de tubos de calor, es primordial. Un portátil diseñado para un alto rendimiento sostenido contará con una solución de refrigeración más avanzada, lo que permitirá que la CPU, GPU y NPU funcionen a velocidades de reloj más altas durante períodos más largos. Al evaluar portátiles con AI, mire más allá de los números iniciales de benchmark y busque reseñas que prueben específicamente el rendimiento sostenido bajo carga pesada y continua. Esta distinción entre rendimiento de ráfaga y sostenido es un diferenciador clave para las aplicaciones prácticas de AI.
Implicaciones Prácticas para las Cargas de Trabajo de AI Local
Comprender estos cuellos de botella proporciona una imagen más clara de lo que se puede esperar de un portátil con AI:
- LLMs: Ejecutar un LLM de 7 mil millones de parámetros con una ventana de contexto decente localmente requiere al menos 16GB de RAM, pero 32GB proporciona una experiencia mucho más fluida, permitiendo ventanas de contexto más grandes y potencialmente ejecutar múltiples modelos u otras aplicaciones simultáneamente. La velocidad de inferencia (tokens por segundo) estará directamente ligada al ancho de banda de la memoria. Las técnicas de Quantization (por ejemplo, Q4, Q8) son cruciales para ajustar modelos más grandes en la RAM disponible, pero conllevan una compensación en la precisión o Perplexity.
- Generación de Imágenes: Modelos como Stable Diffusion son muy exigentes, especialmente para resoluciones más altas o prompts complejos. Si bien las NPUs pueden ayudar con ciertos pasos de preprocesamiento, la generación central a menudo depende en gran medida de la GPU y su VRAM dedicada. Los portátiles sin una GPU discreta tendrán dificultades con la generación de imágenes, incluso con una NPU de altos TOPS, ya que la GPU integrada comparte la RAM del sistema y su ancho de banda es limitado.
- RAG (Retrieval Augmented Generation): La implementación de sistemas RAG locales implica almacenar grandes bases de datos vectoriales (ejerciendo presión sobre la velocidad del SSD), cargar fragmentos relevantes en la RAM (ejerciendo presión sobre la capacidad y el ancho de banda de la RAM), y luego usar un LLM para la generación (ejerciendo presión sobre la NPU/GPU/CPU y la memoria). Cada componente debe ser robusto para que RAG sea efectivo.
Si bien Qualcomm, Intel y AMD están impulsando sus capacidades de NPU, la arquitectura subyacente del sistema sigue siendo el verdadero determinante del rendimiento de la AI en el mundo real. Los chips Snapdragon X Elite/Plus de Qualcomm, por ejemplo, cuentan con impresionantes TOPS de NPU y una excelente eficiencia energética, pero su destreza general en AI en tareas exigentes seguirá dependiendo del subsistema de memoria con el que estén emparejados. De manera similar, los procesadores Core Ultra (Meteor Lake) y los próximos Lunar Lake de Intel, y los chips Ryzen AI de AMD, integran potentes NPUs junto con CPUs capaces y GPUs integradas. El equilibrio entre estos componentes, particularmente el ancho de banda de la memoria y el diseño térmico, es lo que finalmente importa.
Conclusiones Prácticas: Priorizando las Especificaciones para su Próximo Portátil con AI (2026)
Al considerar un portátil con AI, mire más allá del número de TOPS de NPU del titular. Esto es lo que debe priorizar para un rendimiento de AI local verdaderamente capaz:
- La Capacidad de RAM es Clave: Apunte a un mínimo de 32GB de RAM. Si su presupuesto lo permite y la AI local es un enfoque principal, 64GB proporcionarán mucho más margen para modelos más grandes y flujos de trabajo complejos.
- Alto Ancho de Banda de Memoria: Busque portátiles que cuenten con memoria LPDDR5X o DDR5 de alta velocidad. Investigue el ancho de la interfaz de memoria si es posible; las interfaces más anchas (por ejemplo, 256 bits) ofrecen un ancho de banda superior. Esta especificación a menudo se anuncia menos pero es crítica.
- Sistema de Refrigeración Robusto: Busque reseñas profesionales que prueben el rendimiento sostenido bajo cargas pesadas de CPU, GPU y NPU. Un portátil que mantiene altas velocidades de reloj durante períodos prolongados sin throttling es un fuerte indicador de un buen diseño térmico.
- SSD NVMe Rápido: Asegúrese de que su portátil venga con un SSD NVMe PCIe Gen4 o, idealmente, Gen5. Esto acelera la carga del modelo y mitiga las caídas de rendimiento si el sistema necesita intercambiar datos.
- Considere una GPU Discreta para Tareas Específicas: Si su caso de uso principal de AI local implica una generación de imágenes pesada o LLMs muy grandes que se benefician de VRAM dedicada, un portátil con una GPU discreta (incluso una de gama media) ofrecerá un rendimiento superior en comparación con depender únicamente de una GPU integrada y una NPU.
- Los TOPS de la NPU como Línea Base: Trate el requisito de 40+ TOPS para Copilot+ como un punto de entrada necesario, pero no como el único diferenciador. Una vez que se cumple esta línea base, centre su atención en los otros componentes del sistema que realmente desbloquean el potencial de la NPU.
El futuro de la AI en los portátiles es brillante, pero navegar por el panorama del marketing requiere una comprensión más profunda de los principios subyacentes del hardware. Al priorizar el ancho de banda de la memoria, la capacidad de la RAM y la gestión térmica junto con las capacidades de la NPU, los consumidores pueden elegir un portátil que cumpla la promesa de una AI local potente y eficiente.