Speicherbandbreite und Thermik bestimmen die tatsächliche AI-Laptop-Leistung
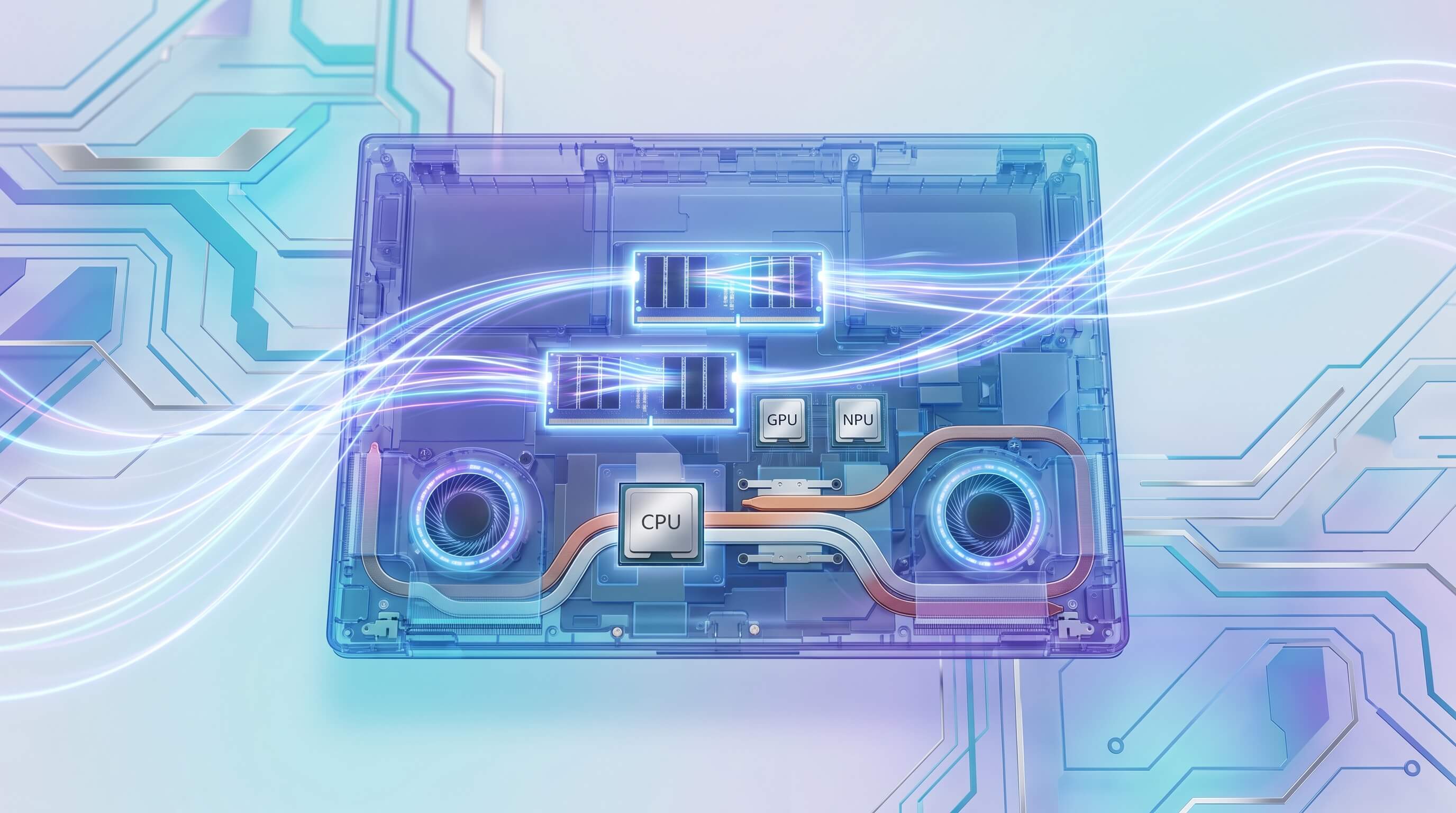
Das Marketing rund um AI-Laptops in den Jahren 2024 und 2025 legt einen starken Schwerpunkt auf Neural Processing Units (NPUs) und deren Tera Operations Per Second (TOPS)-Bewertungen. Mit dem Aufkommen von Copilot+-PCs, die mindestens 40 TOPS erfordern, werden Verbraucher zu der Annahme verleitet, dass eine hohe NPU-Zahl direkt zu robusten lokalen AI-Fähigkeiten führt. Dieser Fokus verschleiert jedoch die wahren architektonischen Engpässe, die die praktische Leistung für das lokale Ausführen großer Sprachmodelle (LLMs) oder komplexer Bilderzeugung bestimmen. Während NPUs eine kritische Komponente für energieeffiziente AI-Inferenz sind, wird ihre rohe Rechenleistung oft durch Einschränkungen bei der Speicherbandbreite, der verfügbaren RAM-Kapazität und der Fähigkeit des Laptops, die Leistung unter thermischer Last aufrechtzuerhalten, zunichte gemacht.
Für jede ernsthafte lokale AI-Workload, sei es das Ausführen eines hochentwickelten LLM wie Llama 3 oder das Generieren hochauflösender Bilder mit Stable Diffusion, ist die Fähigkeit des Systems, riesige Datenmengen schnell und effizient zu bewegen, von größter Bedeutung. Eine leistungsstarke NPU mit 40 oder sogar 70 TOPS bleibt untätig oder unterfordert, wenn sie nicht schnell genug mit Daten versorgt werden kann oder wenn das Modell selbst nicht vollständig im zugänglichen Speicher residieren kann. Dieser Artikel wird die Rollen von CPU, GPU und NPU analysieren, erklären, warum Speicherarchitektur und thermisches Design die unbesungenen Helden der AI-Laptop-Leistung sind, und umsetzbare Erkenntnisse für Verbraucher liefern, die über den Marketing-Hype hinaus fundierte Kaufentscheidungen für 2026 und darüber hinaus treffen möchten.
Jenseits von NPU-TOPS: Die AI-Rechenlandschaft verstehen
Neuronale Verarbeitungseinheiten sind spezialisierte Beschleuniger, die darauf ausgelegt sind, Matrixmultiplikationen und andere gängige Operationen in neuronalen Netzen effizient zu verarbeiten. Ihr Hauptvorteil liegt in ihrer Energieeffizienz für spezifische AI-Inferenzaufgaben, was sie ideal für Hintergrundeffekte wie Blickkontaktkorrektur, Rauschunterdrückung oder einfache Bildsegmentierung macht. Unternehmen wie Qualcomm, Intel und AMD integrieren alle zunehmend leistungsfähige NPUs in ihre mobilen Prozessoren, wobei Benchmarks oft ihre beeindruckenden TOPS-Zahlen hervorheben.
TOPS allein stellen jedoch nur eine Facette der AI-Leistung dar. Betrachten Sie die unterschiedlichen Rollen der drei primären Verarbeitungseinheiten in einem modernen Laptop:
- CPU (Central Processing Unit): Als Allzweck-Arbeitspferd orchestriert die CPU Systemoperationen, verwaltet den Datenfluss und kann AI-Modelle ausführen, insbesondere kleinere oder solche, die nicht für spezialisierte Hardware optimiert sind. Sie zeichnet sich bei latenzsensitiven Aufgaben aus und bietet eine Ausweichmöglichkeit für Workloads, die nicht für GPU oder NPU geeignet sind.
- GPU (Graphics Processing Unit): Als paralleles Verarbeitungs-Kraftpaket sind GPUs unverzichtbar für das Training großer AI-Modelle und für die Ausführung komplexer Inferenzaufgaben, die massive parallele Berechnungen erfordern. Ihre Architektur, insbesondere mit dediziertem VRAM, bietet eine deutlich höhere Speicherbandbreite als typischer System-RAM, was sie ideal für große LLMs und Bilderzeugung macht, bei denen Modellgewichte und Zwischendaten erheblich sind.
- NPU (Neural Processing Unit): Optimiert für spezifische AI-Inferenzmuster bieten NPUs eine überlegene Energieeffizienz für wiederkehrende Aufgaben. Sie eignen sich hervorragend zum Auslagern bestimmter AI-Berechnungen von der CPU oder GPU, wodurch die Akkulaufzeit verlängert und andere Ressourcen freigegeben werden. Ihre Effektivität hängt jedoch stark von der Softwareoptimierung und der spezifischen Modellarchitektur ab. Viele große, unquantisierte LLMs oder komplexe Diffusionsmodelle können aufgrund der Modellgröße und architektonischer Einschränkungen einfach nicht vollständig oder effizient auf aktuellen NPUs ausgeführt werden.
Die Synergie zwischen diesen Komponenten ist entscheidend. Eine NPU könnte einen bestimmten Teil einer AI-Pipeline beschleunigen, aber wenn die vorhergehenden oder nachfolgenden Schritte durch die CPU-Leistung oder, häufiger, durch die Datenübertragungsgeschwindigkeiten ausgebremst werden, leidet das gesamte Benutzererlebnis.
Die unbestreitbare Dominanz von Speicherbandbreite und -kapazität
Beim lokalen Ausführen umfangreicher AI-Modelle ist der am häufigsten übersehene kritischste Faktor der Speicher. Dies umfasst sowohl die schiere Kapazität des RAM als auch, was noch wichtiger ist, die Geschwindigkeit, mit der Daten zu und von diesem RAM bewegt werden können – die Speicherbandbreite.
RAM-Kapazität: Mehr als nur eine Zahl
Große Sprachmodelle sind genau das: groß. Ein gängiges LLM mit 7 Milliarden Parametern kann selbst bei Quantisierung (reduzierter Präzision) auf 4-Bit-Ganzzahlen immer noch etwa 8 GB RAM allein für seine Gewichte benötigen. Hinzu kommt der Platzbedarf für Aktivierungen, das Kontextfenster (der Teil der Eingabeaufforderung und des generierten Textes, den das Modell „sich merkt“), das Betriebssystem und andere laufende Anwendungen, und 16 GB RAM werden schnell zu einem absoluten Minimum, das oft für eine reibungslose Erfahrung nicht ausreicht. Für leistungsfähigere Modelle (z. B. 13 Milliarden Parameter oder größer) oder für das gleichzeitige Ausführen mehrerer Modelle werden 32 GB oder sogar 64 GB RAM unerlässlich. Ohne ausreichend RAM greift das System auf das Auslagern von Daten auf langsamere SSD-Speicher zurück, was zu einer erheblichen Leistungseinbuße und Rucklern führt.
Speicherbandbreite: Der unbesungene Held
Selbst mit ausreichend RAM wird die NPU oder GPU hungern, wenn die Daten nicht schnell genug zugänglich sind. Die Speicherbandbreite misst, wie viele Daten pro Sekunde aus dem Speicher gelesen oder in den Speicher geschrieben werden können. AI-Modelle verschieben ständig riesige Datenmengen – Modellgewichte, Eingabeaufforderungen, Zwischenberechnungen und Ausgabetoken – zwischen dem Hauptspeicher und den Verarbeitungseinheiten. Ist die Speicherbandbreite gering, verbringt die NPU oder GPU trotz ihrer hohen TOPS-Bewertung einen überproportionalen Teil der Zeit mit Warten auf Daten und wird effektiv zum Engpass. Dies führt direkt zu langsameren Inferenzzeiten für LLMs und längeren Generierungszeiten für Image models.
Moderne Laptops verwenden typischerweise LPDDR5X- oder DDR5-Speicher. Während LPDDR5X in einem mobilen Formfaktor oft eine höhere Bandbreite und bessere Energieeffizienz als Standard-DDR5 bietet, ist die spezifische Konfiguration wichtig. Faktoren wie die Anzahl der Speicherkanäle (z. B. 256-Bit breite Speicherschnittstellen, die in Apple Silicon üblich sind, im Gegensatz zu schmaleren 128-Bit-Schnittstellen in vielen PC-Laptops) und die Speichertaktfrequenz beeinflussen die Gesamtbandbreite erheblich. Ein Prozessor mit einer NPU mit hohen TOPS, gepaart mit einem schmalen Speicher-Subsystem mit geringerer Bandbreite, wird unweigerlich schlechter abschneiden als ein System mit einer ausgewogenen Architektur, selbst wenn letzteres eine theoretisch niedrigere NPU-TOPS-Zahl aufweist.
Speichergeschwindigkeit: Die anfängliche Hürde
Obwohl nicht streng „Speicher“ im gleichen Sinne wie RAM, spielt die Geschwindigkeit des Speichergeräts Ihres Laptops (SSD) eine entscheidende Rolle für die AI-Leistung. Große AI-Modelle müssen vor ihrer Verwendung vom Speicher in den RAM geladen werden. Eine schnelle NVMe PCIe Gen4- oder Gen5-SSD sorgt dafür, dass dieser anfängliche Ladevorgang schnell erfolgt. Wenn Ihre RAM-Kapazität nicht ausreicht und das System Teile des Modells auf die Festplatte auslagern muss, mildert eine Hochgeschwindigkeits-SSD den Leistungseinbruch, obwohl sie immer noch deutlich langsamer ist als RAM.
Die kritische Rolle der Thermik für nachhaltige Leistung
AI-Workloads sind von Natur aus rechenintensiv und oft langanhaltend. Im Gegensatz zu kurzzeitigen Aufgaben wie dem Öffnen einer Anwendung oder dem Laden einer Webseite kann das Ausführen eines LLM zur Generierung einer langen Antwort oder das Iterieren einer Bilderzeugungsaufforderung die CPU, GPU und NPU über längere Zeiträume unter starker Last halten. Diese kontinuierliche Berechnung erzeugt erhebliche Wärme.
Laptops sind naturgemäß durch ihre kompakten Formfaktoren und begrenzten Kühllösungen eingeschränkt. Wenn Komponenten eine bestimmte Temperaturschwelle erreichen, drosselt das System automatisch die Leistung, um Überhitzung und potenzielle Schäden zu vermeiden. Dies bedeutet, dass ein Laptop, der für einige Sekunden beeindruckende Benchmark-Ergebnisse erzielt, seine Taktraten und den Stromverbrauch drastisch reduzieren könnte, wenn er mit einer realen, langanhaltenden AI-Aufgabe konfrontiert wird. Die beworbene NPU mit 40+ TOPS liefert ihre Spitzenleistung möglicherweise nur für einen kurzen Moment und fällt dann erheblich ab, was zu einer frustrierend langsamen Erfahrung führt.
Ein effektives Wärmemanagement – einschließlich robuster Kühlsysteme mit Dampfkammern, größeren Lüftern und effizienten Heatpipe-Designs – ist daher von größter Bedeutung. Ein Laptop, der für dauerhaft hohe Leistung ausgelegt ist, verfügt über eine fortschrittlichere Kühllösung, die es CPU, GPU und NPU ermöglicht, über längere Zeiträume mit höheren Taktraten zu arbeiten. Bei der Bewertung von AI-Laptops sollten Sie über die anfänglichen Benchmark-Zahlen hinausblicken und nach Tests suchen, die speziell die dauerhafte Leistung unter schwerer, kontinuierlicher Last prüfen. Diese Unterscheidung zwischen kurzzeitiger und dauerhafter Leistung ist ein wichtiges Unterscheidungsmerkmal für praktische AI-Anwendungen.
Praktische Implikationen für lokale AI-Workloads
Das Verständnis dieser Engpässe bietet ein klareres Bild dessen, was von einem AI-Laptop zu erwarten ist:
- LLMs: Das lokale Ausführen eines LLM mit 7 Milliarden Parametern und einem anständigen Kontextfenster erfordert mindestens 16 GB RAM, aber 32 GB bieten eine wesentlich reibungslosere Erfahrung, ermöglichen größere Kontextfenster und potenziell das gleichzeitige Ausführen mehrerer Modelle oder anderer Anwendungen. Die Geschwindigkeit der Inference (Tokens pro Sekunde) hängt direkt von der Speicherbandbreite ab. Quantization-Techniken (z. B. Q4, Q8) sind entscheidend, um größere Modelle in den verfügbaren RAM zu passen, gehen aber mit einem Kompromiss bei Genauigkeit oder Perplexity einher.
- Bilderzeugung: Modelle wie Stable Diffusion sind sehr anspruchsvoll, insbesondere bei höheren Auflösungen oder komplexen Prompts. Während NPUs bei bestimmten Vorverarbeitungsschritten helfen können, basiert die Kern-Generierung oft stark auf der GPU und ihrem dedizierten VRAM. Laptops ohne diskrete GPU werden bei der Bilderzeugung Schwierigkeiten haben, selbst mit einer NPU mit hohen TOPS, da die integrierte GPU den System-RAM teilt und ihre Bandbreite begrenzt ist.
- RAG (Retrieval Augmented Generation): Die Implementierung lokaler RAG-Systeme beinhaltet das Speichern großer Vektordatenbanken (belastet die SSD-Geschwindigkeit), das Laden relevanter Blöcke in den RAM (belastet die RAM-Kapazität und -Bandbreite) und dann die Verwendung eines LLM zur Generierung (belastet NPU/GPU/CPU und Speicher). Jede Komponente muss robust sein, damit RAG effektiv ist.
Während Qualcomm, Intel und AMD alle ihre NPU-Fähigkeiten vorantreiben, bleibt die zugrunde liegende Systemarchitektur der wahre Bestimmungsfaktor für die reale AI-Leistung. Qualcomms Snapdragon X Elite/Plus-Chips beispielsweise bieten beeindruckende NPU-TOPS und eine hervorragende Energieeffizienz, aber ihre gesamte AI-Leistung bei anspruchsvollen Aufgaben hängt immer noch vom Speicher-Subsystem ab, mit dem sie gepaart sind. Ähnlich integrieren Intels Core Ultra (Meteor Lake) und die kommenden Lunar Lake-Prozessoren sowie AMDs Ryzen AI-Chips leistungsstarke NPUs neben fähigen CPUs und integrierten GPUs. Das Gleichgewicht zwischen diesen Komponenten, insbesondere Speicherbandbreite und thermisches Design, ist letztendlich entscheidend.
Umsetzbare Erkenntnisse: Spezifikationen für Ihren nächsten AI-Laptop (2026) priorisieren
Wenn Sie einen AI-Laptop in Betracht ziehen, schauen Sie über die Schlagzeilen-NPU-TOPS-Zahl hinaus. Hier ist, was Sie für eine wirklich leistungsfähige lokale AI-Leistung priorisieren sollten:
- RAM-Kapazität ist König: Streben Sie mindestens 32 GB RAM an. Wenn Ihr Budget es zulässt und lokale AI ein primärer Fokus ist, bieten 64 GB deutlich mehr Spielraum für größere Modelle und komplexe Workflows.
- Hohe Speicherbandbreite: Suchen Sie nach Laptops mit LPDDR5X- oder Hochgeschwindigkeits-DDR5-Speicher. Untersuchen Sie, wenn möglich, die Breite der Speicherschnittstelle; breitere Schnittstellen (z. B. 256-Bit) bieten eine überlegene Bandbreite. Diese Spezifikation wird oft weniger beworben, ist aber entscheidend.
- Robustes Kühlsystem: Suchen Sie nach professionellen Testberichten, die die dauerhafte Leistung unter hoher CPU-, GPU- und NPU-Last testen. Ein Laptop, der über längere Zeiträume hohe Taktraten ohne Drosselung beibehält, ist ein starker Indikator für ein gutes thermisches Design.
- Schnelle NVMe-SSD: Stellen Sie sicher, dass Ihr Laptop mit einer PCIe Gen4- oder idealerweise Gen5-NVMe-SSD ausgestattet ist. Dies beschleunigt das Laden von Modellen und mindert Leistungseinbrüche, wenn das System Daten auslagern muss.
- Diskrete GPU für spezifische Aufgaben in Betracht ziehen: Wenn Ihr primärer lokaler AI-Anwendungsfall eine intensive Bilderzeugung oder sehr große LLMs umfasst, die von dediziertem VRAM profitieren, bietet ein Laptop mit einer diskreten GPU (selbst einer Mittelklasse-GPU) eine überlegene Leistung im Vergleich zur ausschließlichen Abhängigkeit von einer integrierten GPU und einer NPU.
- NPU-TOPS als Basislinie: Betrachten Sie die Anforderung von 40+ TOPS für Copilot+ als notwendigen Einstiegspunkt, aber nicht als einziges Unterscheidungsmerkmal. Sobald diese Basislinie erfüllt ist, konzentrieren Sie Ihre Aufmerksamkeit auf die anderen Systemkomponenten, die das Potenzial der NPU wirklich freisetzen.
Die Zukunft der AI auf Laptops ist vielversprechend, aber die Navigation in der Marketinglandschaft erfordert ein tieferes Verständnis der zugrunde liegenden Hardware-Prinzipien. Durch die Priorisierung von Speicherbandbreite, RAM-Kapazität und Wärmemanagement neben den NPU-Fähigkeiten können Verbraucher einen Laptop wählen, der das Versprechen einer leistungsstarken, effizienten lokalen AI erfüllt.