تقنيات تعزيز الخصوصية تنتقل من نظرية الامتثال إلى البنية التحتية للبيانات
يشهد مشهد خصوصية البيانات تحولًا عميقًا، منتقلًا من ممارسة الامتثال النظرية إلى ضرورة معمارية أساسية. لسنوات، كانت تقنيات تعزيز الخصوصية (PETs) تُناقش إلى حد كبير في الأوساط القانونية والأكاديمية، وتُعتبر مفاهيم متقدمة لتطبيقات متخصصة. ومع ذلك، فقد وصلت نقطة تحول حاسمة: تتحول أنظمة الحفاظ على الخصوصية الآن بسرعة إلى بنية تحتية رئيسية للبيانات لأن تجميع البيانات الخام والحساسة أصبح محفوفًا بالمخاطر، ومُنظمًا بشكل مفرط، وهشًا من الناحية التشغيلية. هذا التطور لا يتعلق فقط بالالتزام باللوائح الأكثر صرامة مثل GDPR أو CCPA؛ بل يتعلق بتمكين استمرارية فائدة البيانات والابتكار في بيئة تكون فيها خروقات البيانات مكلفة، وثقة الجمهور هشة، والشبكة التنظيمية تتسع باستمرار.
النموذج التقليدي لتجميع مجموعات البيانات الضخمة في بحيرات بيانات مركزية للتحليلات، والتعلم الآلي (Machine Learning)، وذكاء الأعمال أصبح غير قابل للاستمرار بشكل متزايد. إن الحجم الهائل للمعلومات الحساسة يخلق هدفًا لا يقاوم للجهات الخبيثة ومسؤولية كبيرة للمنظمات. وبالتالي، تحول التركيز من مجرد تأمين البيانات في حالة السكون (at rest) وأثناء النقل (in transit) إلى تأمين البيانات أثناء الاستخدام وتمكين التحليل التعاوني دون التعرض المباشر للبيانات. يتطلب هذا التحول النموذجي اعتماد PETs ليس كطبقة أمان اختيارية، بل كمكونات أساسية لخطوط أنابيب البيانات الحديثة وأطر الحوكمة، مما يسمح للمنظمات باستخلاص الرؤى وبناء النماذج من المعلومات الحساسة مع تقليل التعرض وزيادة ضمانات الخصوصية.
الضرورة التشغيلية: لماذا أصبحت PETs الآن بنية تحتية أساسية
إن التحرك نحو PETs كبنية تحتية أساسية مدفوع بعدة عوامل متقاربة. أولاً، إن التكلفة المتصاعدة لانتهاكات البيانات، المالية والسمعية، تفرض موقفًا استباقيًا بشأن حماية البيانات. ثانيًا، إن خليط قوانين سيادة البيانات العالمية ولوائح الخصوصية يجعل مشاركة البيانات ومعالجتها عبر الحدود معقدة بشكل لا يصدق. تواجه المنظمات معضلة: الاستفادة من البيانات لتحقيق ميزة تنافسية أو المخاطرة بعدم الامتثال والإضرار بالسمعة. توفر PETs مسارًا ثالثًا حاسمًا، مما يسمح بفائدة البيانات دون المساس بالخصوصية أو انتهاك الولايات القضائية. ثالثًا، يتطلب صعود نماذج الذكاء الاصطناعي (AI) والتعلم الآلي (ML)، التي غالبًا ما تتطلب كميات هائلة من البيانات المتنوعة، طرقًا جديدة للوصول إلى المعلومات الحساسة ومعالجتها دون إنشاء ثغرات خصوصية جديدة. توفر PETs الوسائل التقنية لتدريب النماذج على مجموعات بيانات موزعة وحساسة دون الكشف عن البيانات الخام الأساسية على الإطلاق.
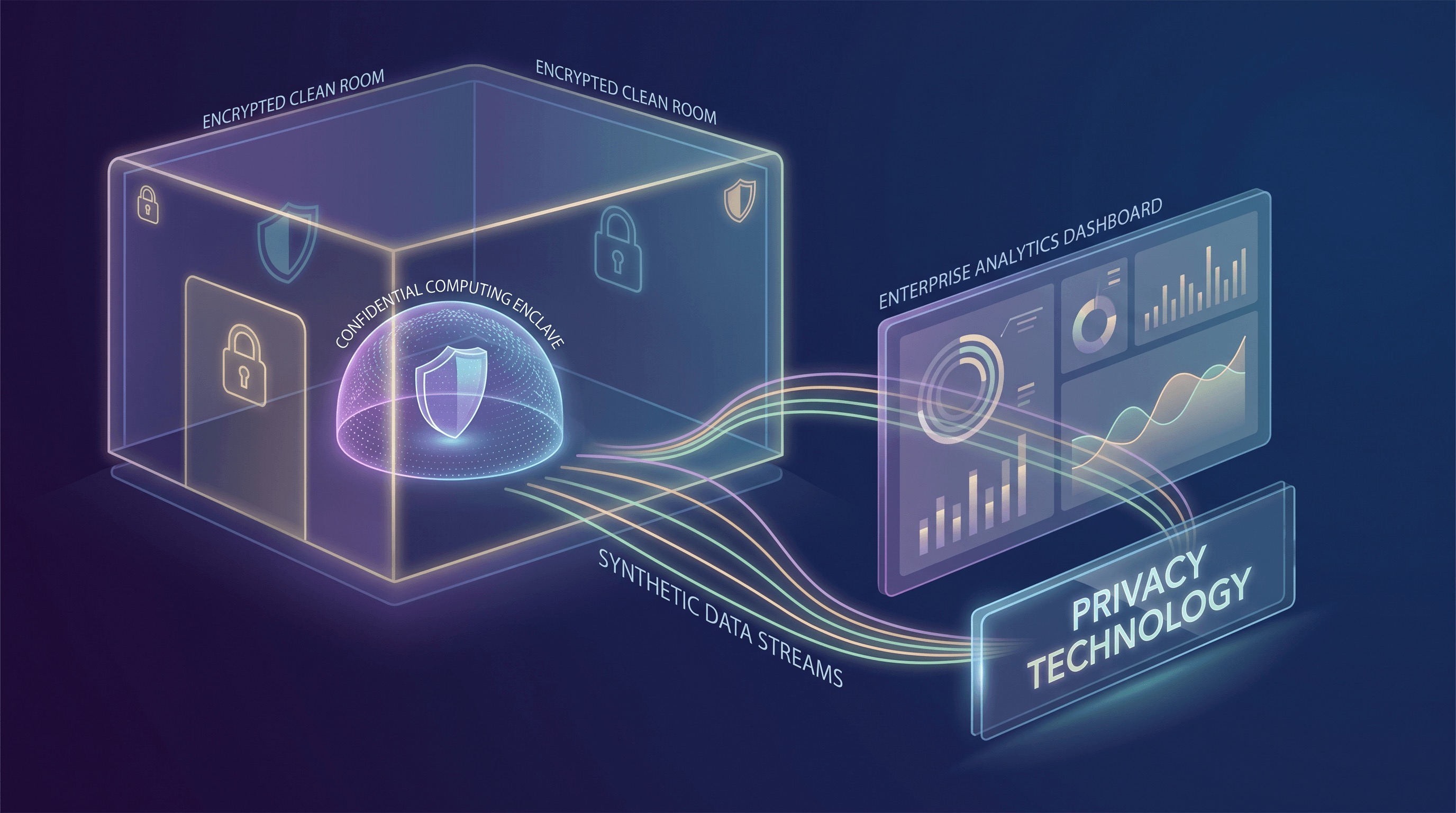
Confidential Computing: تأمين البيانات أثناء الاستخدام
أحد أهم التطورات في PETs هو Confidential Computing. تقليديًا، ركز أمان البيانات على التشفير في حالة السكون (التخزين) وأثناء النقل (الشبكة). يكمل Confidential Computing هذه الثلاثية من خلال حماية البيانات أثناء الاستخدام – بينما تتم معالجتها بواسطة وحدة المعالجة المركزية والذاكرة. يتم تحقيق ذلك من خلال بيئات التنفيذ الموثوقة (TEEs) القائمة على الأجهزة، والتي يشار إليها غالبًا باسم Enclaves. تنشئ هذه TEEs بيئة آمنة ومعزولة داخل وحدة المعالجة المركزية حيث يمكن معالجة البيانات والتعليمات البرمجية بضمانات قوية للنزاهة والسرية، حتى من مزود السحابة أو البرامج الأخرى ذات الامتياز على نفس الجهاز.
على سبيل المثال، تُعرّف Google Cloud تقنية Confidential Computing بأنها تقنية تقوم بتشفير البيانات في الذاكرة وأثناء الحساب، مما يضمن بقاء البيانات غير قابلة للوصول إلى البنية التحتية الأساسية، بما في ذلك مشغل السحابة. هذه الإمكانية تحويلية. وهذا يعني أن العمليات الحسابية الحساسة، مثل معالجة معلومات التعريف الشخصية (PII) أو الخوارزميات الاحتكارية، يمكن إجراؤها في السحابة بمستويات غير مسبوقة من الضمان. حركة السوق حول Confidential Computing قوية، مع توفر عروض الآن تشمل Confidential VMs، وConfidential Spaces لأحمال العمل المعبأة في حاويات، وخدمات التصديق للأجهزة، وحلول متخصصة لحالات استخدام التحليلات والذكاء الاصطناعي/التعلم الآلي. يشير هذا التبني الواسع إلى انتقالها من مفهوم أمني متخصص إلى أساس بنية تحتية سحابية قابلة للاستخدام وقابلة للتوسع، مما يتيح سيناريوهات كانت تعتبر في السابق محفوفة بالمخاطر للغاية بالنسبة لبيئات السحابة العامة.
Data Clean Rooms: تحليلات تعاونية مع الخصوصية
تقنية PET قوية أخرى تكتسب زخمًا هي Data Clean Room. توفر Clean Rooms بيئة آمنة ومتحكم بها حيث يمكن لأطراف متعددة التعاون في تحليل مجموعات بيانات حساسة، غالبًا ما تكون متداخلة، دون الكشف المباشر عن بياناتها الخام لبعضها البعض. وهذا ذو قيمة خاصة لقياس الإعلانات، واكتشاف الاحتيال، وتحسين سلسلة التوريد، حيث تتطلب الرؤى دمج البيانات من منظمات مختلفة. المبدأ الأساسي هو أن الرؤى المجمعة التي تحافظ على الخصوصية فقط هي التي يتم مشاركتها، وليس البيانات الخام على مستوى الفرد أبدًا.
تُعد AWS Clean Rooms مثالاً على هذا الاتجاه، حيث تقدم خدمة تسمح للعملاء بتحليل مجموعات بياناتهم المدمجة والتعاون بشأنها بشكل آمن دون مشاركة أو الكشف عن البيانات الأساسية. ومن الميزات البارزة إدخال إنشاء مجموعات بيانات اصطناعية (Synthetic Dataset Generation) معززة للخصوصية لتدريب ML داخل هذه Clean Rooms. هذه الإمكانية حاسمة: فهي تسمح للمنظمات بإنشاء إصدارات اصطناعية تمثيلية إحصائيًا لبياناتها الحساسة. تحافظ مجموعات البيانات الاصطناعية هذه على الأنماط والعلاقات الإحصائية الأساسية الموجودة في البيانات الأصلية، مما يجعلها مناسبة لتدريب نماذج ML، مع تقليل مخاطر إعادة التحديد (re-identification) واستدلال العضوية (membership inference) بشكل كبير. توفر AWS مقاييس الدقة والخصوصية لمساعدة المستخدمين على فهم المفاضلات والتأكد من أن البيانات الاصطناعية تلبي متطلبات فائدتها وخصوصيتها. يعالج هذا الابتكار بشكل مباشر تحدي بناء نماذج AI قوية تتطلب بيانات واسعة دون تحمل المسؤوليات الكاملة للخصوصية الناتجة عن مشاركة أو تجميع PII الخام.
Synthetic Data: أداة خصوصية متعددة الاستخدامات
إلى جانب تطبيقها في Clean Rooms، تبرز Synthetic Data كتقنية مستقلة ومتعددة الاستخدامات لتعزيز الخصوصية. توفر البيانات التي تم إنشاؤها والتي تحاكي البيانات الحقيقية إحصائيًا ولكنها لا تحتوي على أي سجلات فردية فعلية حلاً قويًا للتطوير والاختبار وحتى بعض المهام التحليلية. تتيح القدرة على إنشاء مجموعات بيانات اصطناعية عالية الدقة للمطورين بناء واختبار التطبيقات باستخدام بيانات واقعية دون لمس PII الإنتاجية على الإطلاق. هذا يسرع دورات التطوير، ويقلل من الأعباء التشغيلية للامتثال، ويقلل من سطح الهجوم المرتبط بمعالجة المعلومات الحساسة في بيئات غير إنتاجية.
لقد تقدمت دقة إنشاء Synthetic Data بشكل كبير، مستفيدة من نماذج الذكاء الاصطناعي التوليدية (Generative AI) لالتقاط الارتباطات والتوزيعات المعقدة الموجودة في البيانات الأصلية. وهذا يضمن أن النماذج المدربة على البيانات الاصطناعية تعمل بشكل مشابه لتلك المدربة على البيانات الحقيقية، مما يجعلها بديلاً قابلاً للتطبيق للعديد من سير عمل ML. المفتاح هو الموازنة بين الفائدة والخصوصية، والتأكد من أن البيانات الاصطناعية مفيدة بما يكفي للغرض المقصود منها مع توفير ضمانات قوية ضد إعادة التحديد.
Federated Analysis: التعلم بدون مركزية
يمثل Federated Analysis، بما في ذلك تطبيقه الأكثر تحديدًا في Federated Learning، تقنية PET حاسمة أخرى لبيئات البيانات الموزعة. بدلاً من تجميع البيانات الخام من مصادر متعددة (على سبيل المثال، أجهزة مختلفة، منظمات، أو مناطق جغرافية) في موقع واحد للتحليل أو تدريب النموذج، تجلب الأساليب الموحدة الحساب إلى البيانات. في Federated Learning، على سبيل المثال، يتم تدريب نموذج عالمي عن طريق إرسال معلمات النموذج إلى الأجهزة المحلية أو صوامع البيانات. يقوم كل كيان محلي بتدريب النموذج على بياناته الخاصة، ويتم إرسال معلمات النموذج المحدثة فقط (أو التدرجات) مرة أخرى إلى خادم مركزي، حيث يتم تجميعها لتحسين النموذج العالمي. لا تغادر البيانات الخام موقعها الأصلي أبدًا.
هذا النهج ذو قيمة خاصة للسيناريوهات التي تتضمن بيانات حساسة للغاية موزعة عبر العديد من نقاط النهاية، مثل السجلات الطبية في مستشفيات مختلفة أو بيانات المستخدم على الأجهزة المحمولة الفردية. إنه يسمح بالتحليلات التعاونية وتدريب النماذج عبر مجموعات بيانات متنوعة دون التحديات الهائلة للخصوصية واللوجستية لتجميع البيانات الخام. يدعم Federated Analysis بشكل أساسي سيادة البيانات ويقلل من مخاطر انتهاكات البيانات على نطاق واسع، حيث لا يمتلك أي كيان واحد جميع المعلومات الخام على الإطلاق.
PETs كأساس جديد لبنية البيانات
يشير دمج تقنيات تعزيز الخصوصية هذه إلى تحول أساسي في كيفية تعامل المنظمات مع حوكمة البيانات واستخدامها. لم تعد مجرد ميزات أمان "من الجيد امتلاكها" أو فضول أكاديمي معقد. بدلاً من ذلك، أصبحت PETs هي البنية التقنية التي تمكن الشركات من الاستمرار في الاستفادة من البيانات الحساسة بفعالية بموجب توقعات الخصوصية، وسيادة البيانات، وحوكمة الذكاء الاصطناعي (AI governance) المتزايدة الصرامة. وهذا يعني أن مهندسي البيانات، والمهندسين، ومسؤولي الخصوصية يجب أن يفهموا وينفذوا بشكل متزايد حلولًا مثل Confidential Computing، وData Clean Rooms، وإنشاء Synthetic Data، وFederated Analysis كمكونات قياسية لبنيتهم التحتية للبيانات.
يعتمد مستقبل الابتكار القائم على البيانات على القدرة على استخلاص القيمة من المعلومات الحساسة بمسؤولية. توفر PETs الجسر الحاسم بين فائدة البيانات وحماية الخصوصية. ومع نضوج هذه التقنيات وتزايد إمكانية الوصول إليها من خلال عروض مزودي السحابة ومبادرات المصادر المفتوحة (open-source)، سيتسارع اعتمادها، مما يعيد تشكيل كيفية جمع البيانات ومعالجتها ومشاركتها وتحليلها عبر الصناعات بشكل أساسي. عصر تجميع البيانات الخام دون عواقب يقترب من نهايته؛ عصر بنية البيانات الذكية التي تحافظ على الخصوصية قد بدأ للتو.