Tecnologias de Aprimoramento da Privacidade Estão Migrando da Teoria de Conformidade para a Infraestrutura de Dados
O cenário da privacidade de dados está passando por uma transformação profunda, mudando de um exercício de conformidade teórico para um imperativo arquitetônico fundamental. Por anos, as Tecnologias de Aprimoramento da Privacidade (PETs) foram amplamente discutidas em círculos legais e acadêmicos, vistas como conceitos avançados para aplicações de nicho. No entanto, um ponto de inflexão crítico chegou: sistemas de preservação da privacidade estão se tornando rapidamente infraestrutura de dados mainstream porque centralizar dados brutos e sensíveis está se tornando muito arriscado, muito regulamentado e muito frágil operacionalmente. Esta evolução não é meramente sobre aderir a regulamentações mais rigorosas como GDPR ou CCPA; é sobre permitir a utilidade contínua dos dados e a inovação em um ambiente onde as violações de dados são caras, a confiança pública é frágil e a rede regulatória está se expandindo constantemente.
O modelo tradicional de agregação de vastos conjuntos de dados em data lakes centrais para análise, Machine Learning e Business Intelligence é cada vez mais insustentável. O grande volume de informações sensíveis cria um alvo irresistível para atores maliciosos e uma responsabilidade significativa para as organizações. Consequentemente, o foco mudou de simplesmente proteger os dados em repouso (at rest) e em trânsito (in transit) para proteger os dados em uso e permitir a análise colaborativa sem exposição direta dos dados. Essa mudança de paradigma exige a adoção de PETs não como uma camada de segurança opcional, mas como componentes integrais dos pipelines de dados modernos e estruturas de governança, permitindo que as organizações derivem insights e construam modelos a partir de informações sensíveis, minimizando a exposição e maximizando as garantias de privacidade.
O Imperativo Operacional: Por que as PETs são Agora Infraestrutura Central
A mudança para as PETs como infraestrutura central é impulsionada por vários fatores convergentes. Primeiramente, o custo crescente das violações de dados, tanto financeiras quanto de reputação, força uma postura proativa na proteção de dados. Em segundo lugar, o mosaico de leis globais de soberania de dados e regulamentações de privacidade torna o compartilhamento e processamento de dados transfronteiriços incrivelmente complexo. As organizações enfrentam um dilema: alavancar dados para vantagem competitiva ou arriscar a não conformidade e danos à reputação. As PETs oferecem um terceiro caminho crucial, permitindo a utilidade dos dados sem comprometer a privacidade ou violar mandatos jurisdicionais. Em terceiro lugar, o surgimento de modelos de AI e Machine Learning (ML), que frequentemente exigem grandes quantidades de dados diversos, necessita de novas maneiras de acessar e processar informações sensíveis sem criar novas vulnerabilidades de privacidade. As PETs fornecem os meios técnicos para treinar modelos em conjuntos de dados distribuídos e sensíveis sem nunca expor os dados brutos subjacentes.
Confidential Computing: Protegendo Dados em Uso
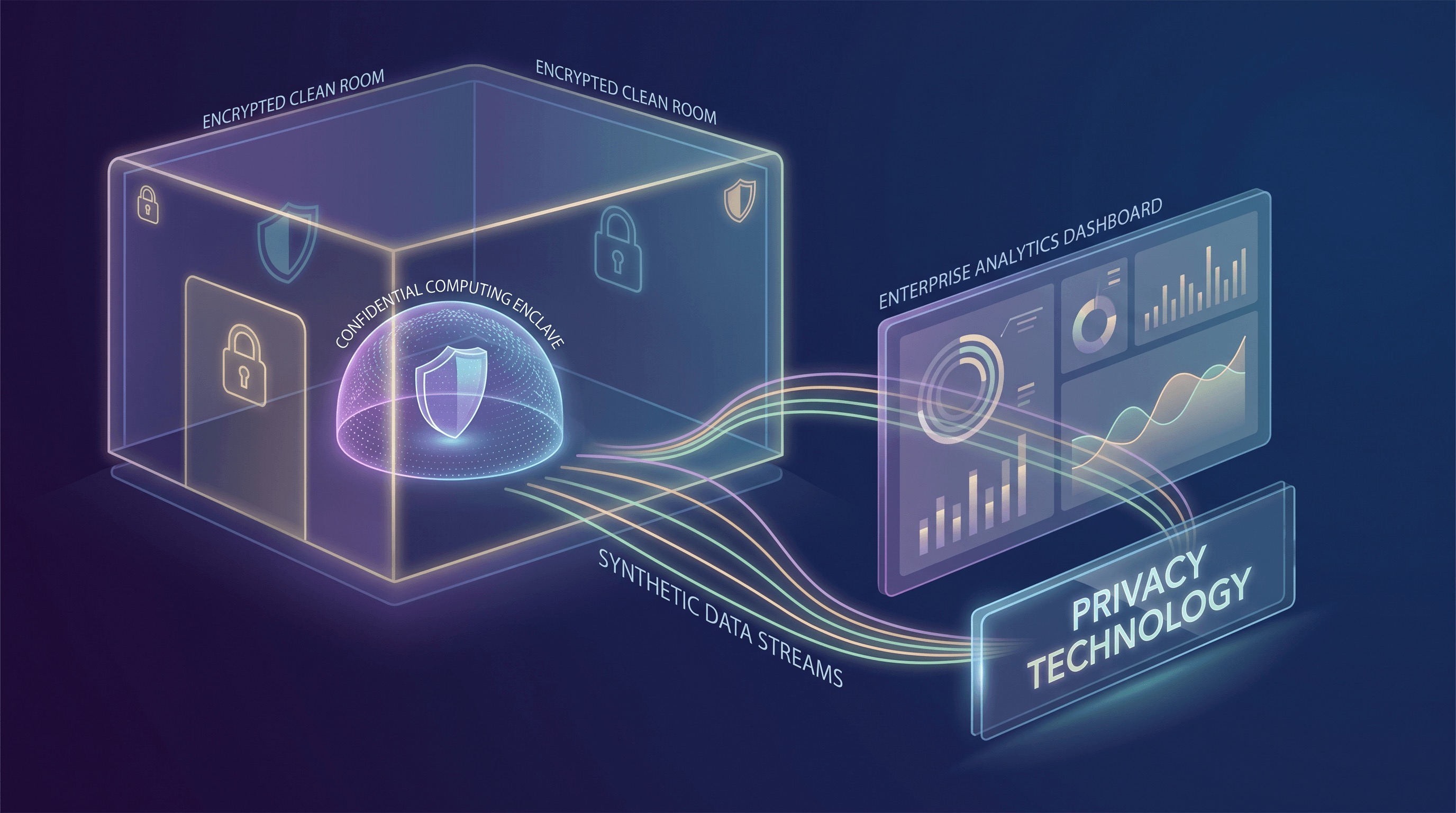
Um dos avanços mais significativos em PETs é o Confidential Computing. Tradicionalmente, a segurança de dados focava na criptografia em repouso (armazenamento) e em trânsito (rede). O Confidential Computing completa essa tríade protegendo os dados em uso – enquanto estão sendo processados pela CPU e memória. Isso é alcançado através de Trusted Execution Environments (TEEs) baseados em hardware, frequentemente referidos como enclaves. Esses TEEs criam um ambiente seguro e isolado dentro de uma CPU onde dados e código podem ser processados com fortes garantias de integridade e confidencialidade, mesmo do provedor de nuvem ou de outros softwares privilegiados na mesma máquina.
O Google Cloud, por exemplo, define o Confidential Computing como uma tecnologia que criptografa dados na memória e durante a computação, garantindo que os dados permaneçam inacessíveis à infraestrutura subjacente, incluindo o operador da nuvem. Essa capacidade é transformadora. Significa que computações sensíveis, como o processamento de informações de identificação pessoal (PII) ou algoritmos proprietários, podem ser realizadas na nuvem com níveis sem precedentes de garantia. O movimento do mercado em torno do Confidential Computing é robusto, com ofertas que agora abrangem Confidential VMs, Confidential Spaces para cargas de trabalho em contêineres, serviços de atestação de hardware e soluções especializadas para casos de uso de Analytics e AI/ML. Essa ampla adoção significa sua transição de um conceito de segurança de nicho para uma primitiva de infraestrutura de nuvem utilizável e escalável, permitindo cenários anteriormente considerados muito arriscados para ambientes de nuvem pública.
Clean Rooms de Dados: Análise Colaborativa com Privacidade
Outra PET poderosa que está ganhando força é a Clean Room de Dados. Clean rooms fornecem um ambiente seguro e controlado onde múltiplas partes podem colaborar na análise de conjuntos de dados sensíveis, frequentemente sobrepostos, sem expor diretamente seus dados brutos umas às outras. Isso é particularmente valioso para medição de publicidade, detecção de fraudes e otimização da cadeia de suprimentos, onde insights exigem a combinação de dados de diferentes organizações. O princípio central é que apenas insights agregados e que preservam a privacidade são compartilhados, nunca os dados brutos em nível individual.
A AWS Clean Rooms exemplifica essa tendência, oferecendo um serviço que permite aos clientes analisar e colaborar com segurança em seus conjuntos de dados combinados sem compartilhar ou revelar dados subjacentes. Uma característica notável é a introdução da geração de conjuntos de dados sintéticos (Synthetic Dataset Generation) que aprimoram a privacidade para treinamento de ML dentro dessas Clean Rooms. Essa capacidade é crucial: ela permite que as organizações criem versões sintéticas estatisticamente representativas de seus dados sensíveis. Esses conjuntos de dados sintéticos preservam os padrões e relacionamentos estatísticos essenciais encontrados nos dados originais, tornando-os adequados para treinar modelos de ML, ao mesmo tempo em que reduzem significativamente o risco de reidentificação e inferência de associação. A AWS fornece métricas de fidelidade e privacidade para ajudar os usuários a entender as compensações e garantir que os dados sintéticos atendam aos seus requisitos de utilidade e privacidade. Essa inovação aborda diretamente o desafio de construir modelos de AI poderosos que exigem dados extensos sem incorrer em todas as responsabilidades de privacidade de compartilhar ou centralizar PII bruta.
Synthetic Data: Uma Ferramenta de Privacidade Versátil
Além de sua aplicação em Clean Rooms, os Synthetic Data estão emergindo como uma Tecnologia de Aprimoramento da Privacidade versátil e autônoma. Dados gerados que imitam estatisticamente dados reais, mas não contêm registros individuais reais, oferecem uma solução poderosa para desenvolvimento, teste e até mesmo algumas tarefas analíticas. A capacidade de gerar conjuntos de dados sintéticos de alta fidelidade permite que os desenvolvedores construam e testem aplicativos usando dados realistas sem nunca tocar em PII de produção. Isso acelera os ciclos de desenvolvimento, reduz a sobrecarga de conformidade e minimiza a superfície de ataque associada ao manuseio de informações sensíveis em ambientes não produtivos.
A sofisticação da geração de Synthetic Data avançou consideravelmente, aproveitando modelos de AI generativa (Generative AI) para capturar correlações e distribuições complexas presentes nos dados originais. Isso garante que os modelos treinados em dados sintéticos tenham um desempenho semelhante aos treinados em dados reais, tornando-o uma alternativa viável para muitos fluxos de trabalho de ML. A chave é equilibrar utilidade e privacidade, garantindo que os dados sintéticos sejam úteis o suficiente para o propósito pretendido, ao mesmo tempo em que fornecem fortes garantias contra a reidentificação.
Análise Federada: Aprendizado Sem Centralização
A Análise Federada (Federated Analysis), incluindo sua aplicação mais específica em Federated Learning, representa outra PET crítica para ambientes de dados distribuídos. Em vez de centralizar dados brutos de múltiplas fontes (por exemplo, diferentes dispositivos, organizações ou regiões geográficas) em um único local para análise ou treinamento de modelos, os métodos federados trazem a computação para os dados. No Federated Learning, por exemplo, um modelo global é treinado enviando os parâmetros do modelo para dispositivos locais ou silos de dados. Cada entidade local treina o modelo em seus dados privados, e apenas os parâmetros do modelo atualizados (ou gradientes) são enviados de volta a um servidor central, onde são agregados para melhorar o modelo global. Os dados brutos nunca saem de sua localização original.
Essa abordagem é particularmente valiosa para cenários que envolvem dados altamente sensíveis distribuídos por muitos endpoints, como registros médicos em diferentes hospitais ou dados de usuários em dispositivos móveis individuais. Ela permite análises colaborativas e treinamento de modelos em diversos conjuntos de dados sem os imensos desafios de privacidade e logísticos de agrupar dados brutos. A Análise Federada apoia inerentemente a soberania dos dados e minimiza o risco de violações de dados em larga escala, pois nenhuma entidade única detém todas as informações brutas.
PETs como a Nova Fundação da Arquitetura de Dados
A integração dessas Tecnologias de Aprimoramento da Privacidade significa uma mudança fundamental na forma como as organizações abordam a governança e a utilização dos dados. Elas não são mais meramente recursos de segurança "bons de ter" ou curiosidades acadêmicas complexas. Em vez disso, as PETs estão se tornando a arquitetura técnica que permite às empresas continuar a alavancar dados sensíveis de forma eficaz sob expectativas cada vez mais rigorosas de privacidade, soberania de dados e AI governance. Isso significa que arquitetos de dados, engenheiros e oficiais de privacidade devem cada vez mais entender e implementar soluções como Confidential Computing, Clean Rooms de Dados, geração de Synthetic Data e Análise Federada como componentes padrão de sua infraestrutura de dados.
O futuro da inovação impulsionada por dados depende da capacidade de extrair valor de informações sensíveis de forma responsável. As PETs fornecem a ponte crucial entre a utilidade dos dados e a proteção da privacidade. À medida que essas tecnologias amadurecem e se tornam mais acessíveis por meio de ofertas de provedores de nuvem e iniciativas open-source, sua adoção acelerará, remodelando fundamentalmente como os dados são coletados, processados, compartilhados e analisados em todas as indústrias. A era de centralizar dados brutos sem consequências está chegando ao fim; a era da infraestrutura de dados inteligente e que preserva a privacidade está apenas começando.