OpenTelemetry é o padrão de observabilidade agora — veja o que isso realmente significa para sua stack
OpenTelemetry cruzou um limiar em 2026 que importa mais do que qualquer número de download individual: deixou de ser algo que você avalia e se tornou algo que você herda. Quando você contrata um novo engenheiro de backend e ele pergunta qual stack de observabilidade você está usando, OTel é a resposta que ele espera. Quando você sobe um novo serviço e busca por instrumentação, OTel é a biblioteca para a qual você vai. O projeto da CNCF que começou como uma fusão do OpenCensus e OpenTracing em 2019, sete anos depois, venceu a guerra dos padrões de instrumentação de forma decisiva.
Os números apoiam essa caracterização. No início de 2026, 48,5% das organizações estão usando ativamente o OpenTelemetry, com outros 25% planejando implementação. 81% o consideram pronto para produção. Apenas o SDK do Python registrou 224 milhões de downloads em janeiro de 2026 — 6 milhões por dia. O próprio relatório da CNCF mostrou um aumento de 43% em commits e 50% em Pull Requests mesclados em 2025. OpenTelemetry não é uma ferramenta de nicho para entusiastas de observabilidade; é infraestrutura.
O que o OTel realmente padroniza — e o que não
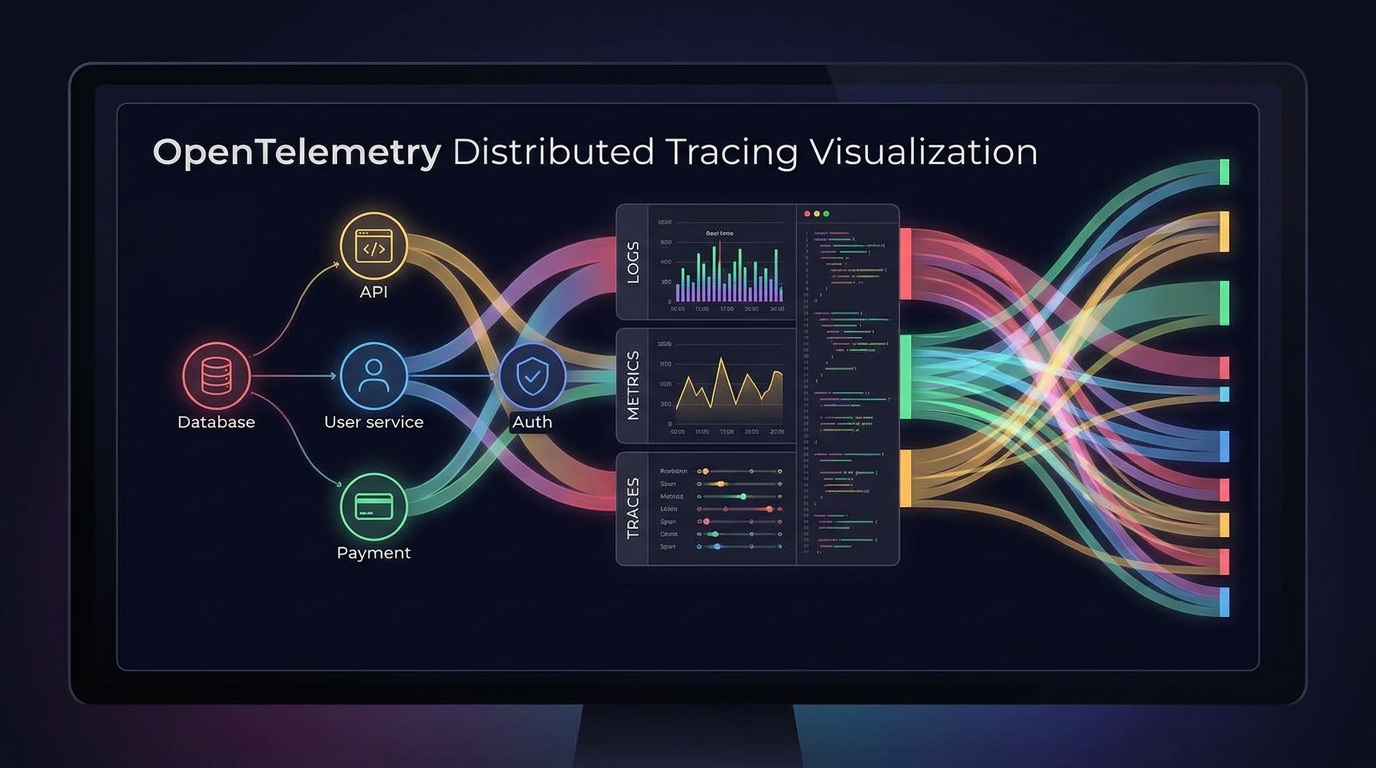
OpenTelemetry padroniza três coisas: as APIs para instrumentar código (como você emite dados de telemetria), os SDKs para coletar e processar esses dados, e o protocolo OTLP para transmiti-los a um backend. O que ele não padroniza é para onde os dados vão ou o que você faz com eles quando chegam.
Esta é a distinção arquitetônica crucial. OTel é um cano, não um banco de dados ou uma camada de visualização. Você pode enviar dados do OTel para Grafana, Datadog, Honeycomb, Dynatrace, Elastic, Jaeger, Prometheus ou qualquer backend que fale OTLP — que, a partir de 2026, são essencialmente todos. O aumento anual de 36% nas distribuições do OTel fornecidas por fornecedores (vendedores que enviam seus próprios coletores e SDKs compatíveis com OTel) reflete o mercado alcançando essa realidade: se seu backend de observabilidade não suporta ingestão nativa do OTel, você está em desvantagem competitiva.
Os três sinais de telemetria que o OTel cobre são traces (rastros distribuídos pelo caminho de uma requisição entre serviços), metrics (medições numéricas ao longo do tempo — latência, taxas de erro, throughput) e logs (registros de eventos estruturados). Em 2026, traces são os mais maduros e amplamente usados (50,2% dos usuários do OTel), seguidos por metrics (57%) e logs (48,4%). Profiles — dados de perfilamento contínuo — são um quarto sinal emergente que 9,2% dos usuários já estão instrumentando, um indicador inicial de para onde o escopo do OTel está indo.
O Collector: onde reside a maior complexidade de produção
O OpenTelemetry Collector é o componente que faz o processamento real de dados — recebendo telemetria de serviços instrumentados, aplicando transformações e filtragem, e encaminhando para um ou mais backends. 65% dos usuários do OTel em produção executam mais de 10 Collectors; implantações grandes executam centenas. Kubernetes continua sendo o ambiente de implantação dominante (81%), embora implantações baseadas em VM tenham crescido significativamente (de 33% para 51%), refletindo a adoção em ambientes que não containerizaram tudo.
O modelo de pipeline do Collector — receivers, processors, exporters encadeados — dá a ele uma flexibilidade que é poderosa e operacionalmente complexa. Um padrão comum de produção: um Collector sidecar por pod que lida com a coleta inicial de dados e filtragem básica, alimentando um cluster de Collector gateway que aplica amostragem, enriquecimento e lógica de roteamento antes de encaminhar para backends. Essa arquitetura de dois níveis separa as preocupações de instrumentação por serviço das preocupações de processamento em nível de cluster, o que importa em escala.
O problema operacional mais comum em implantações do OTel em escala é o gerenciamento de cardinalidade. Rótulos de alta cardinalidade em métricas — usando IDs de usuário, IDs de requisição ou outros valores ilimitados como dimensões de rótulo de métrica — podem causar explosão de séries métricas, criando custos de memória e armazenamento que tornam a observabilidade mais cara do que os sistemas sendo observados. Os processadores de filtro e transformação do Collector podem impor limites de cardinalidade, mas isso requer configuração deliberada que as equipes muitas vezes não priorizam até encontrarem o problema.
Instrumentação: automática vs manual
As bibliotecas de auto-instrumentação do OTel lidam com a maioria das necessidades comuns de instrumentação sem alterações de código. Para aplicações Java, o agente Java auto-instrumenta clientes e servidores HTTP, JDBC, gRPC, Kafka, Redis e dezenas de outras bibliotecas anexando-se no nível da JVM. Para Python, Node.js, .NET, Go e outras linguagens suportadas, auto-instrumentação similar cobre os frameworks e bibliotecas que a maioria das aplicações usa.
A auto-instrumentação lhe dá 80% do valor com esforço mínimo. Os 20% restantes — instrumentar sua lógica de negócio real, adicionar atributos personalizados que carregam contexto de domínio, criar spans para operações que não mapeiam para chamadas de biblioteca — exigem instrumentação manual usando a API do OTel. As disciplinas são diferentes: auto-instrumentação é um problema de configuração de implantação, instrumentação manual é um problema de qualidade de código e compreensão arquitetônica.
Os alvos de instrumentação manual de maior valor não são conselhos genéricos como "adicione spans a tudo" — eles são específicos para o que torna o comportamento do seu sistema observável para fins de depuração. Quais são as operações cuja distribuição de latência você precisa entender? Quais são os atributos de nível de domínio (tier de cliente, valores de feature flags, identificadores de recursos) que você precisa correlacionar entre serviços ao investigar um incidente? A instrumentação manual que responde a essas perguntas vale muito mais do que cobertura uniforme de tudo.
Amostragem: a tensão não resolvida
Rastrear cada requisição em detalhes completos em um sistema de produção de alto volume é economicamente impraticável. Um serviço lidando com 10.000 requisições por segundo gera enormes volumes de trace se cada requisição produzir um trace completo. A amostragem — registrar apenas uma fração dos traces — é uma necessidade prática, mas cria uma tensão fundamental: os traces que você mais precisa para depuração (caminhos de erro, outliers lentos, sequências incomuns) são exatamente os traces que você tem mais chance de perder se amostrar ingenuamente.
A amostragem baseada em cabeça (decidir se rastreia uma requisição no início) é simples de implementar, mas cega para resultados — você não pode saber se uma requisição será interessante até que ela seja concluída. A amostragem baseada em cauda (decidir depois do fato, mantendo traces que atendem a critérios como ocorrência de erro ou limite de latência) é mais inteligente, mas requer buffer de traces completos antes de tomar decisões de amostragem, o que adiciona latência e sobrecarga de memória ao Collector.
O Tail Sampling Processor do OTel implementa amostragem baseada em cauda no Collector, e está disponível em produção. A configuração não é trivial — você precisa definir políticas (manter todos os erros, manter requisições acima de X milissegundos, manter uma amostra aleatória básica de todo o resto) e ajustar os tamanhos de buffer adequadamente. Equipes que investem na configuração de tail sampling obtêm uma relação sinal-ruído drasticamente melhor em seus traces. Equipes que usam head-based sampling com uma taxa fixa obtêm cobertura adequada para a maioria dos propósitos, mas perdem a longa cauda de eventos interessantes.
Para onde o OTel está indo: profiles e além
A CNCF tem o OpenTelemetry no caminho para o status de projeto Graduated em 2026 — a designação de maturidade mais alta no ciclo de vida da CNCF, atualmente mantida por projetos como Kubernetes, Prometheus e Envoy. A graduação do OTel sinaliza que o projeto é estável, amplamente implantado e demonstrou a maturidade de governança para ser considerado infraestrutura fundamental.
A próxima fronteira de capacidade é o perfilamento contínuo — o quarto sinal de telemetria que o OpenTelemetry está estendendo para cobrir. O perfilamento contínuo captura dados de CPU, memória e nível de goroutine/thread de processos em execução de forma recorrente, permitindo correlação entre o desempenho no nível de trace e o código real executado durante requisições lentas. Correlacionar um trace lento com um perfil de CPU que mostra qual função estava queimando ciclos durante aquela janela de requisição é exatamente o tipo de análise multi-sinal que o modelo de dados unificado do OTel torna possível.
Se você não está executando OTel em 2026, não está atrás de uma curva tecnológica — está atrás de um padrão da indústria. A fase de avaliação acabou. A questão é como instrumentar, coletar e rotear seus dados de telemetria efetivamente usando ferramentas que agora convergiram amplamente para o OTel como base.