Por dentro da NPU: por que todo chip grande agora tem um motor neural — e o que ele realmente faz
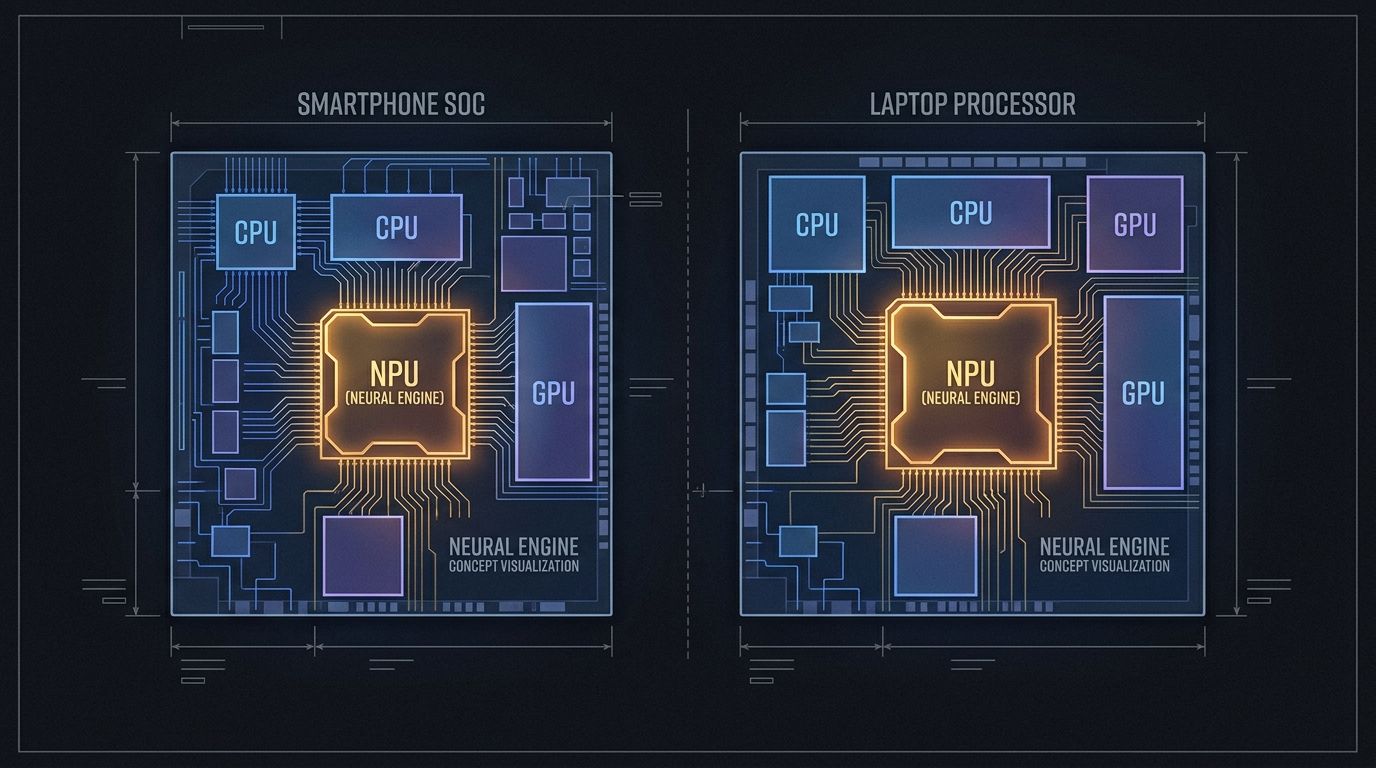
Uma transição silenciosa de hardware vem se desenvolvendo há três anos, e em 2026 está essencialmente completa: quase todos os processadores de consumo enviados pela Apple, Qualcomm, Intel, AMD e MediaTek agora incluem uma unidade de processamento neural dedicada. A NPU não é mais uma especificação para entusiastas. É a nova linha de base.
A mudança é significativa o suficiente para que o programa de certificação Copilot+ do Windows 11 tenha estabelecido um requisito mínimo de 40 TOPS para a NPU como uma barreira rígida para certificação. Na prática, o que esses chips fazem — e por que o hardware existente de GPU e CPU não conseguia lidar com as mesmas cargas de trabalho?
Por que um chip separado para IA
A GPU não desapareceu da pilha de IA — ela continua sendo o substrato computacional dominante para treinamento e inferência em larga escala em data centers. Mas as GPUs consomem muita energia e são otimizadas para paralelismo em escala. Um telefone ou laptop usando uma GPU móvel para inferência contínua de IA — cancelamento de ruído de fundo, tradução em tempo real, melhoria de vídeo — drenaria a bateria em algumas horas.
As NPUs resolvem isso com especialização. Diferente de uma GPU (que executa cargas de trabalho paralelas gerais) ou uma CPU (que se destaca em lógica sequencial e ramificada), uma NPU é construída especificamente para as multiplicações de matrizes e funções de ativação que dominam a inferência de redes neurais. O resultado é uma eficiência energética ordens de grandeza melhor para um conjunto limitado, mas crescente, de tarefas.
A Apple vem enviando NPUs desde o A11 Bionic em 2017, inicialmente comercializado como "Neural Engine" para Face ID. O Neural Engine do A11 executava 600 bilhões de operações por segundo. O A18 Pro do iPhone 16 Pro atinge 35 TOPS — uma melhoria de quase 60 vezes em nove anos, em um chip que ainda cabe em um telefone.
O cenário atual por plataforma
O Snapdragon X Elite da Qualcomm, o chip que alimenta a maioria dos laptops Windows Copilot+ lançados em 2024–2025, oferece 45 TOPS através de sua NPU Hexagon. A Qualcomm afirma uma eficiência por watt 4,5 vezes melhor do que a inferência de GPU comparável nas mesmas tarefas — um número que se mantém razoavelmente bem em testes independentes.
O M4 Pro da Apple entrega 38 TOPS de seu Neural Engine, com a Apple relatando ganhos substanciais nos benchmarks Core ML em relação à geração M3. Os chips da série M se beneficiam da arquitetura de memória unificada — o Neural Engine compartilha o mesmo pool de memória de alta largura de banda que a CPU e a GPU, eliminando a sobrecarga de cópia que prejudica a inferência de GPU discreta em modelos pequenos.
A série Core Ultra 200 da Intel (Lunar Lake) marca a NPU mais competitiva da Intel até o momento, com 48 TOPS — projetada especificamente para ultrapassar o limite do Copilot+ com uma margem que permita futuros requisitos de IA do Windows. A série Ryzen AI 300 da AMD atinge 50 TOPS. O Dimensity 9400 da MediaTek, que alimenta a série Samsung Galaxy S25, alcança 50 TOPS com ganhos significativos de eficiência em relação à geração anterior.
O que as NPUs estão realmente executando
Os casos de uso se enquadram em categorias consistentes:
Tarefas contínuas e sensíveis à latência. Transcrição em tempo real (Live Text da Apple, clareza de voz do Windows Studio), desfoque de fundo em chamadas de vídeo e cancelamento ativo de ruído são tarefas onde a latência da GPU é muito alta e as viagens de ida e volta para a nuvem introduzem atraso inaceitável. As NPUs lidam com essas tarefas continuamente com consumo mínimo de energia.
Inferência de LLM no dispositivo. Modelos na faixa de 1B a 8B parâmetros — Phi-3 Mini, Gemma 3 4B, Llama 3.2 3B — podem ser executados inteiramente no dispositivo através da NPU quando quantizados para precisão de 4 bits. A arquitetura Private Cloud Compute da Apple descarrega apenas as tarefas grandes demais para o Neural Engine. No Windows, o Phi-3 Mini da Microsoft é executado nativamente via DirectML na NPU Hexagon para respostas do Copilot no dispositivo.
Fotografia computacional. Fusão HDR em tempo real, segmentação semântica para substituição de fundo, rastreamento de malha facial para RA — estas são cargas de trabalho de NPU em todos os smartphones flagship atuais. O pipeline de processamento da câmera migrou em grande parte do ISP para a NPU nos últimos três anos.
Indexação de pesquisa e recuperação. O Windows Recall usa a NPU para processar continuamente capturas de tela e criar um índice semântico pesquisável. A pesquisa Fotos no dispositivo da Apple usa o Neural Engine para incorporação de imagens e correspondência de similaridade.
O problema do benchmark
TOPS é uma métrica enganosa. Ela mede a taxa de transferência máxima sob condições ideais — multiplicação de matriz sustentada com todas as unidades de execução ativas. As cargas de trabalho reais de IA são mais irregulares e explosivas. Uma NPU de 50 TOPS executando um modelo mal otimizado pode ter desempenho inferior a um chip de 35 TOPS com melhor suporte do compilador e arquitetura de memória.
O padrão emergente para benchmarking prático de NPU é o MLPerf Mobile, que mede o desempenho de ponta a ponta em modelos padronizados, em vez de TOPS brutos. A diferença entre as especificações de papel e os resultados do MLPerf pode ser grande. Alguns chips com alto TOPS têm desempenho significativamente inferior em tarefas que não eram centrais em seu design.
O que isso significa para os desenvolvedores
A existência de NPUs amplamente implantadas está criando um novo nível na pilha de implantação de IA. A divisão atual: inferência em nuvem para modelos grandes (GPT-4, Claude 3.7+, Gemini 2.5), inferência NPU no dispositivo para modelos de até ~8B parâmetros em quantização de 4 bits, e um nível intermediário crescente de inferência de borda classe servidor para modelos de 13B a 70B.
Para desenvolvedores que criam recursos com tecnologia de IA, a questão prática agora é qual nível de inferência se adequa ao caso de uso — não apenas se a inferência em nuvem está disponível. Tarefas com requisitos estritos de privacidade, necessidades de baixa latência ou requisitos offline devem ter como alvo a inferência no dispositivo via Core ML, Windows ML ou Android NNAPI. Os frameworks estão amadurecendo. O hardware está lá.
A corrida das NPUs não está desacelerando. Espera-se que a plataforma Snapdragon de próxima geração da Qualcomm ultrapasse 70 TOPS. A família A19 Pro da Apple está mirando 45+ TOPS. A questão não é mais se seu dispositivo tem um chip de IA — mas quais partes de sua carga de trabalho você moveu para ele.