O roteamento de modelos (Model Routing) está se tornando o plano de controle para a IA corporativa
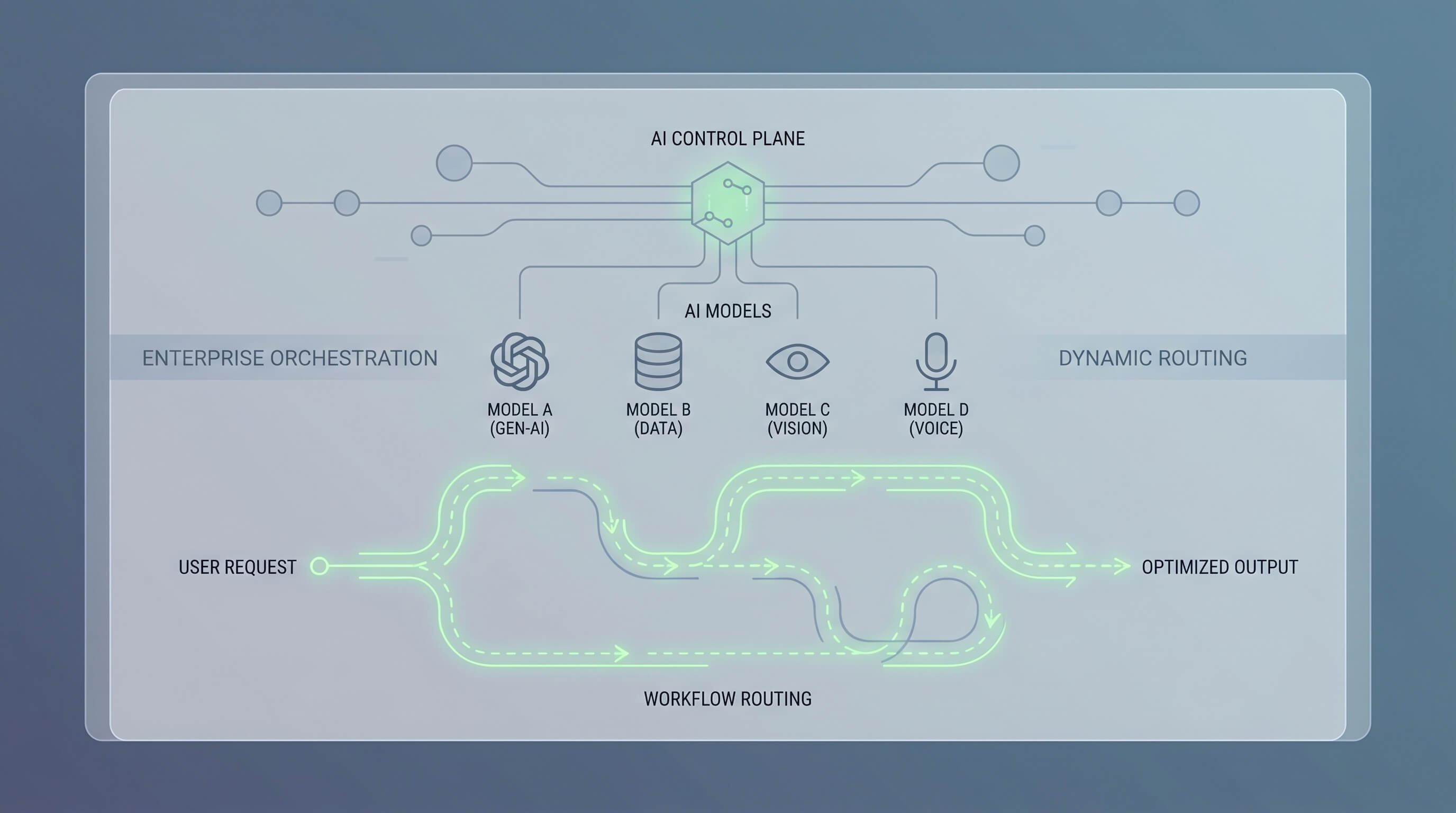
A IA corporativa está superando a fase em que o sucesso dependia de escolher um único modelo principal e conectá-lo a um chatbot. À medida que copilotos e agentes se espalham para suporte, operações, revisão jurídica, entrega de software e busca interna, o verdadeiro desafio se torna o controle. Qual modelo deve lidar com qual tarefa? Quando um fluxo de trabalho deve escalar de um modelo barato para um mais capaz? O que acontece quando os requisitos de residência de dados, latência ou auditabilidade entram em conflito com o puro desempenho de benchmark? As organizações que escalam bem a IA estão respondendo cada vez mais a essas perguntas com uma camada de roteamento, não com uma estratégia de lealdade a um modelo.
Essa camada de roteamento está se transformando no plano de controle para a IA corporativa. Ela decide como as solicitações são classificadas, como os modelos são selecionados, quando as ferramentas são invocadas, como as barreiras de proteção são aplicadas e como a qualidade é medida ao longo do tempo. Na prática, isso significa que a arquitetura de IA corporativa mais durável não é "um aplicativo, um modelo", mas "muitas tarefas, uma camada de orquestração governada". Copilotos e agentes podem ser a interface visível, mas o roteamento de modelos (model routing) é o que os torna economicamente viáveis, operacionalmente seguros e adaptáveis à medida que o cenário de modelos continua mudando.
Por que uma estratégia de modelo único falha
Em protótipos, um único modelo forte parece eficiente. As equipes se movem rapidamente, a demonstração funciona e a arquitetura permanece simples. Em produção, essa simplicidade se torna cara e frágil. Nem toda solicitação precisa do modelo de raciocínio mais avançado. Nem todo fluxo de trabalho pode tolerar a mesma latência. Nem toda classe de dados pode ser enviada para o mesmo provedor. E nem todo modo de falha pode ser detectado na camada de prompt.
Um copiloto corporativo que lida com milhares de interações diárias pode enfrentar sumarização, recuperação, classificação, consulta de políticas, geração de planilhas e raciocínio de várias etapas na mesma hora. Para alguns desses trabalhos, um modelo rápido e de baixo custo é suficiente. Para outros, especialmente tarefas ambíguas ou de alto risco, o sistema pode precisar de um modelo mais capaz, uma passagem de verificação ou um ponto de verificação humano. Sem roteamento, a organização paga a mais por trabalho rotineiro ou tem um desempenho inferior em trabalhos complexos. Muitas vezes, ela faz ambos.
O roteamento resolve isso separando a intenção da tarefa da identidade do modelo. Em vez de perguntar: "Qual modelo executa nosso assistente?", as empresas podem perguntar: "Qual é o caminho mais barato, rápido e seguro para uma boa resposta para esta classe de trabalho?". Essa é uma pergunta muito mais operacional e muito mais próxima de como as equipes de infraestrutura maduras pensam.
O que o roteamento de modelos realmente faz
Na melhor das hipóteses, o roteamento de modelos não é apenas uma central telefônica. É um motor de políticas apoiado por telemetria. Ele avalia a solicitação, o usuário, a janela de contexto, os requisitos da ferramenta, o nível de risco e o objetivo de nível de serviço. Em seguida, ele escolhe um caminho de execução.
Decisões comuns de roteamento incluem
Escolher entre modelos com base em custo, latência, adequação ao domínio ou restrições de conformidade.
Escalar consultas difíceis quando as pontuações de confiança são baixas ou quando as passagens anteriores falham na validação.
Enviar extração estruturada para um modelo menor, reservando modelos de raciocínio premium para casos de exceção.
Aplicar roteamento específico da região para dados regulamentados, como manter cargas de trabalho de saúde ou financeiras dentro de provedores e geografias aprovados.
Executar verificações secundárias, como detecção de alucinações, verificação de citações ou revisão de políticas, antes que uma resposta chegue ao usuário.
Em outras palavras, o roteamento se torna o lugar onde as regras de negócios e o comportamento do modelo se encontram. É por isso que a analogia do plano de controle é importante. Essa camada não apenas otimiza a inferência. Ela governa as operações de IA.
Padrões de implementação que funcionam no mundo real
O primeiro padrão útil é a escalada em camadas. Um copiloto de suporte pode começar com um modelo de baixo custo para detecção de intenção, recuperação de conhecimento e geração de rascunhos de resposta. Se a solicitação envolver disputas de faturamento, linguagem jurídica ou clientes frustrados ameaçando cancelar, o sistema escala para um modelo mais forte e anexa uma etapa de validação de política. Esse padrão reduz o custo na maior parte dos tickets, preservando a qualidade onde ela é mais importante.
O segundo padrão é o roteamento especializado. Um assistente de engenharia de software pode usar um modelo para conclusão de código, outro para raciocínio em todo o repositório e um terceiro para análise focada em segurança. A mudança importante é que o usuário experimenta um único assistente, enquanto a plataforma decide qual pilha de recursos invocar nos bastidores. É assim que as empresas muitas vezes escondem a complexidade do modelo dos usuários finais sem abrir mão da flexibilidade.
O terceiro padrão é a orquestração que prioriza as ferramentas. Em aquisições, por exemplo, um agente que revisa contratos de fornecedores pode chamar sistemas de recuperação, bancos de dados de políticas, ferramentas de revisão e fluxos de trabalho de aprovação antes de gerar uma resposta em linguagem natural. O roteador determina se a tarefa precisa de geração, ou se ferramentas determinísticas podem responder à maior parte dela. Isso reduz o risco de alucinações e melhora a auditabilidade.
Um quarto padrão é o de julgar e reparar. Em operações de saúde ou na entrada de sinistros de seguros, um modelo extrai campos de documentos não estruturados, enquanto outro verifica a consistência do esquema e sinaliza anomalias. Se a confiança da extração cair abaixo do limite, o fluxo de trabalho tenta novamente com um modelo mais forte ou encaminha para revisão humana. Esse padrão trata os modelos como componentes em um pipeline controlado, em vez de oráculos de uma só vez.
Exemplos corporativos concretos
Um banco que implanta um copiloto de conformidade interno pode rotear perguntas de política de rotina para um modelo de menor custo hospedado em um ambiente aprovado, mas escalar casos extremos de combate à lavagem de dinheiro para um modelo de raciocínio superior com verificações de citação e registro obrigatórios. A lógica de roteamento é impulsionada menos pela marca do modelo do que pela classificação de risco.
Uma empresa global de software pode rotear tarefas de assistente de desenvolvedor por tipo de trabalho. O preenchimento automático e a elaboração de testes de unidade vão para endpoints de inferência rápidos, enquanto a revisão de arquitetura ou o planejamento de migração usam um modelo de raciocínio maior com recuperação de repositório. As varreduras de segurança podem então ser passadas para um modelo separado ajustado para explicação de vulnerabilidades. Os usuários veem um copiloto, mas a plataforma executa vários caminhos especializados.
Um administrador de saúde que processa documentos de encaminhamento pode usar um modelo compacto para limpeza de OCR e extração de metadados, e depois um modelo mais forte apenas quando os registros estão incompletos, contraditórios ou provavelmente afetarão as decisões de autorização prévia. Isso mantém a produtividade alta, reservando o raciocínio caro para exceções.
Um marketplace de comércio eletrônico pode executar agentes de atendimento ao cliente por meio de um roteador multilíngue que leva em conta o idioma, o valor do pedido, os indicadores de fraude e a sensibilidade da política de reembolso. Uma simples pergunta de envio recebe uma resposta barata e rápida. Uma suspeita de apropriação de conta aciona um fluxo de trabalho mais rigoroso com políticas de verificação e geração limitada.
O que os líderes devem medir
Muitos programas de IA medem a qualidade do modelo apenas em termos de benchmarks. O roteamento desvia a atenção para o desempenho do sistema. Os líderes devem rastrear o custo por resultado bem-sucedido, não apenas o custo por token. Eles devem medir a taxa de escalada, a taxa de nova tentativa, a frequência de substituição humana, a latência por nível de fluxo de trabalho e a taxa de violação de políticas. Se um modelo premium produz apenas ganhos marginais em tarefas de baixo risco, o roteador deve aprender com isso. Se um modelo mais barato causa retrabalho downstream, esse custo também deve ser visível.
Isso também significa que a avaliação precisa acontecer no nível do fluxo de trabalho. A pergunta certa não é se um modelo superou outro em um benchmark público, mas se a orquestração geral melhorou os resultados de negócios sob as restrições corporativas.
O retorno estratégico
As empresas que investem cedo no roteamento de modelos ganham algo mais valioso do que a otimização de curto prazo. Elas ganham opcionalidade. Os provedores mudarão, os modelos melhorarão, os preços cairão e os requisitos de governança se tornarão mais rígidos. Um plano de controle forte permite que as organizações se adaptem sem reconstruir cada copiloto e agente do zero.
Essa é a mudança mais profunda em andamento. A vantagem corporativa duradoura em IA não virá de apostar tudo em um único fornecedor de modelos. Virá da construção da camada de orquestração que combina continuamente o modelo, a ferramenta e a política certos para o trabalho em questão. Na próxima fase da IA corporativa, o roteamento não é apenas infraestrutura. É estratégia tornada operacional.