Os Crawlers de IA Estão Transformando Sites Abertos em Alvos de Infraestrutura
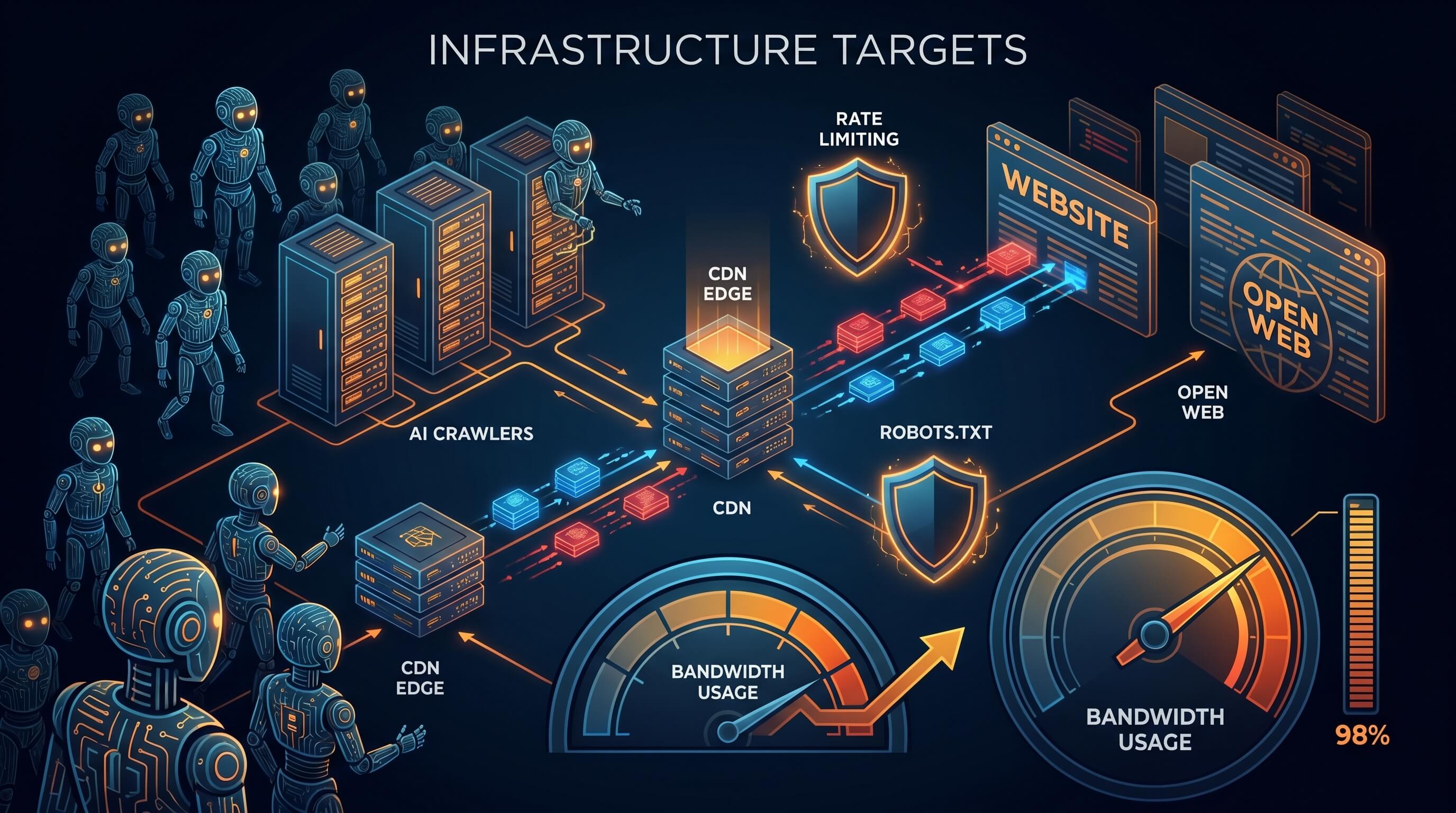
Durante grande parte da história da web, manter um site público significava aceitar um acordo básico. Você publicava páginas abertamente, os motores de busca indexavam esse conteúdo e visitantes humanos chegavam por links e descoberta. Esse modelo está mudando. Crawlers de IA estão a atingir sites abertos em escala de máquina e muitas vezes consomem muito mais recursos do que devolvem em visitas humanas.
A consequência prática é clara: mais sites estão a ser tratados como alvos de infraestrutura, e não apenas como publicações. As contas de CDN sobem, a pressão sobre servidores de origem aumenta e o robots.txt passa a parecer mais uma sugestão do que um mecanismo eficaz.
Por que o tráfego de crawlers de IA é diferente
O rastreamento tradicional de motores de busca nunca foi gratuito, mas havia uma troca relativamente compreensível. O editor aceitava o custo porque a indexação podia trazer descoberta e audiência. No caso dos crawlers de IA, essa ligação enfraquece. Um fornecedor pode rastrear intensamente para treino de modelos, camadas de retrieval ou sistemas de resposta sem enviar tráfego proporcional de volta à fonte.
Isso muda os incentivos. Se um bot consome grandes volumes de tráfego e quase não envia referências, ele comporta-se mais como extrator do que como parceiro de descoberta.
A fatura de CDN torna-se um problema editorial
Quando o tráfego de bots aumenta, a infraestrutura deixa de ser apenas um tema de bastidores. Ela começa a influenciar decisões de publicação. Um blog de nicho, um fórum comunitário ou uma base pública de conhecimento pode ter pouco público humano, mas um grande conjunto de páginas facilmente rastreáveis.
Nesse cenário, o site torna-se mais caro de operar sem se tornar mais valioso para a sua audiência real. Isso pode empurrar operadores para paywalls leves, desafios automáticos ou políticas de bloqueio mais duras.
O contrato social antigo do robots.txt está a enfraquecer
O robots.txt sempre foi voluntário, não uma fronteira de segurança. Ainda assim, funcionou razoavelmente bem porque os grandes crawlers tinham incentivos para se comportar de forma previsível. Essa expectativa está a enfraquecer.
Muitos operadores já partem do princípio de que alguns agentes vão ignorar o robots.txt, regressar com novos identificadores ou respeitá-lo apenas formalmente. Mesmo a conformidade não garante compensação económica nem atribuição suficiente.
Rate limiting torna-se postura padrão
Muitos sites usavam rate limiting apenas para abuso ou proteção de login. Agora essa prática está a tornar-se um controlo básico de publicação pública. Equipes limitam endpoints abertos, classificam bots e bloqueiam padrões suspeitos antes que cheguem à origem.
Há tradeoffs evidentes. Limites agressivos podem prejudicar automações legítimas, investigadores, acessibilidade e até motores de busca úteis. O objetivo não é bloquear tudo, mas tornar o custo do rastreamento previsível e sustentável.
O problema central é a assimetria
Grandes empresas de IA podem distribuir o custo do rastreamento por plataformas enormes e tratá-lo como insumo estratégico. Um pequeno editor não consegue distribuir da mesma forma o custo da defesa. Cada terabyte extra, cada ajuste de WAF e cada hora de engenharia recaem diretamente sobre o operador.
É por isso que a web aberta corre o risco de se tornar uma camada subsidiada para sistemas de IA. O conteúdo continua público, mas o custo de mantê-lo público é pago pelos editores, enquanto parte crescente do valor final é capturada noutro lugar.
O que operadores de sites devem fazer agora
Medir separadamente o custo dos bots
Separe largura de banda, volume de pedidos, cache misses e carga na origem por classe de bot sempre que possível.
Reduzir superfícies de rastreamento caras
Audite arquivos, pesquisa interna, paginação, variantes de URL e caminhos de baixo valor.
Levar a proteção para a edge
Use controlos de CDN e WAF para absorver tráfego repetitivo antes de atingir a infraestrutura de origem.
Definir níveis explícitos de acesso
Nem tudo precisa ser simplesmente aberto ou fechado. Acesso em alto volume pode exigir chaves de API, quotas ou termos comerciais.
Documentar a política
Publique uma política clara de crawling e licenciamento ao lado do robots.txt para reforçar a base de aplicação e negociação.
A web aberta agora precisa de defesas económicas
Os crawlers de IA não são um incómodo temporário. Eles estão a alterar o modelo de custos da publicação pública. A conclusão prática é agir já: medir a carga bot, reduzir superfícies desnecessárias, aplicar limites na edge e reservar o acesso intensivo para termos explícitos.
A próxima fase da web será definida não apenas pelo que é publicado, mas também por quem consegue suportar o custo de permanecer aberto.