Pourquoi les Agents d'IA Ont Besoin de Mémoire, Pas Seulement de Fenêtres Contextuelles Plus Grandes
Nous sommes en 2026, et le paysage de l'IA évolue à un rythme effréné. Nous avons vu les fenêtres contextuelles des grands modèles de langage (LLM) passer de quelques milliers de jetons à bien plus d'un million, promettant un avenir où les agents pourront traiter de vastes quantités d'informations en une seule requête. C'est sans aucun doute une avancée puissante, mais pour de nombreux acteurs de l'IA d'entreprise, une prise de conscience critique s'installe : des fenêtres contextuelles plus grandes ne sont pas la panacée pour des agents d'IA vraiment efficaces et durables. Le véritable facteur de différenciation, comme l'a si bien formulé Cloudflare, est la capacité de se souvenir de ce qui compte sans constamment remplir la fenêtre contextuelle, abordant ainsi le problème de production très réel de la 'dégradation du contexte'.
Les Limites d'une Requête Plus Longue
Imaginez que vous essayiez de vous souvenir de chaque détail d'un projet d'un an en relisant chaque e-mail, transcription de réunion et document du début à la fin chaque fois que vous devez prendre une décision. C'est essentiellement ce que nous demandons à un agent d'IA de faire lorsque nous nous appuyons uniquement sur une fenêtre contextuelle en constante expansion. Bien que cette approche soit impressionnante, elle présente des limites inhérentes :
- Coût et Latence : Le traitement de millions de jetons pour chaque interaction est coûteux en termes de calcul et introduit une latence significative, rendant les applications en temps réel difficiles.
- Surcharge d'informations : Tout comme les humains, les modèles d'IA peuvent avoir du mal à identifier les informations les plus pertinentes lorsqu'ils sont confrontés à un volume écrasant de données. Des détails importants peuvent être enfouis, ce qui conduit à des réponses moins précises ou moins efficaces.
- Lacune de la Mémoire Épisodique : Une grande fenêtre contextuelle fournit un instantané de l'interaction actuelle, mais elle ne construit pas intrinsèquement une compréhension durable des interactions passées, des préférences de l'utilisateur ou des objectifs à long terme. Chaque nouvelle requête est en grande partie un nouveau départ, bien qu'avec un contexte plus immédiat.
Comme Microsoft Learn le conseille sagement, l'objectif devrait toujours être d'utiliser l'architecture la moins complexe qui fonctionne de manière fiable. Le simple fait de jeter plus de jetons sur un problème ajoute souvent de la complexité, et non des solutions élégantes.
Pourquoi la Mémoire Change la Donne
Au lieu de simplement allonger la requête, l'intelligence agentique véritable repose sur une mémoire durable et une orchestration intelligente du contexte. Cela permet à un agent d'IA de construire une compréhension persistante et évolutive de son environnement, de ses utilisateurs et de ses tâches, un peu comme le fait un humain. Il s'agit d'un rappel sélectif, et non d'une relecture brute.
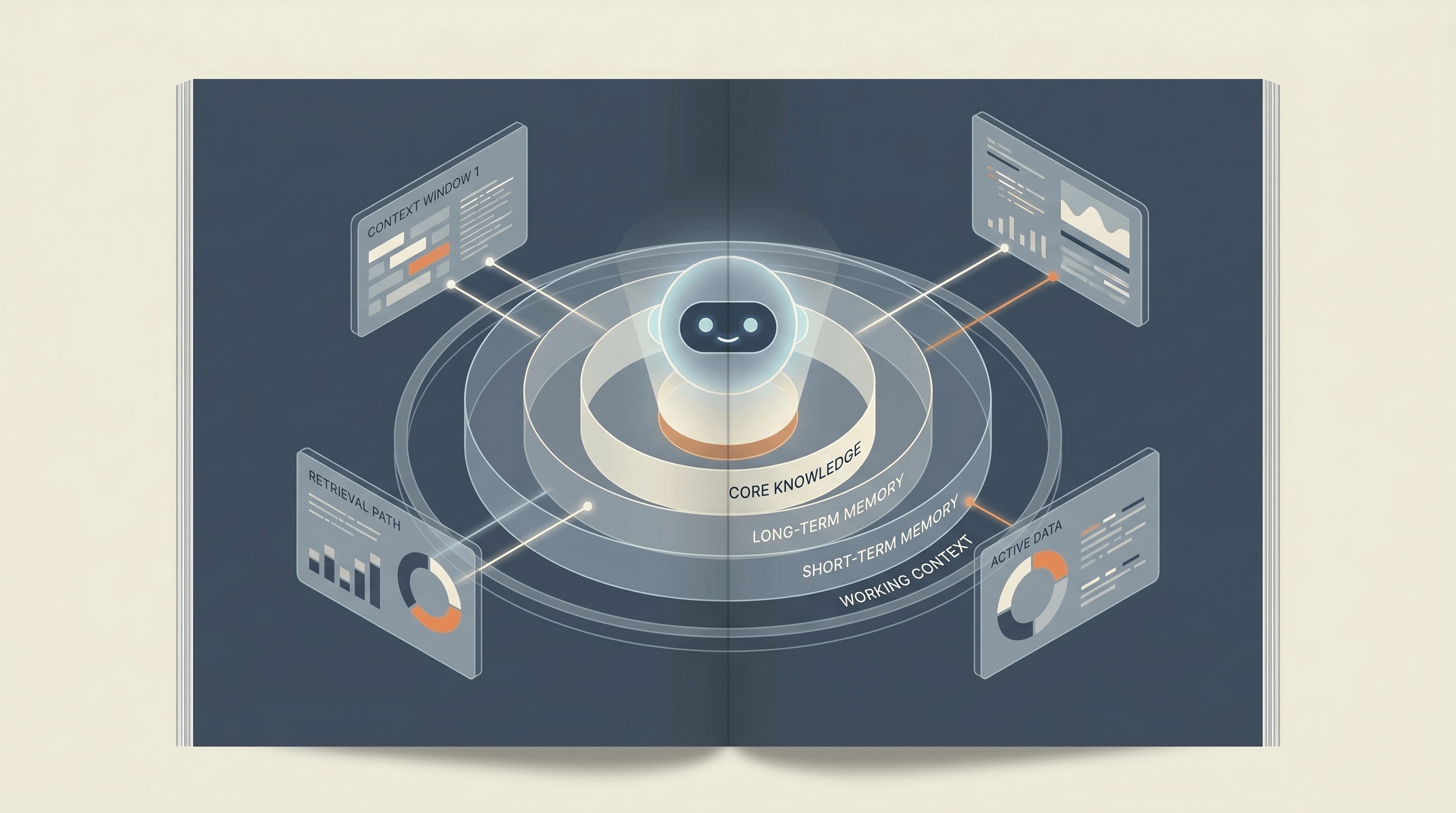
Différentes Formes de Mémoire d'Agent
Pour comprendre comment la mémoire habilite les agents d'IA, il est utile de la décomposer en différentes couches :
- Contexte de Travail (Court Terme) : Il s'agit de la mémoire immédiate et éphémère au sein de la fenêtre de requête actuelle. Elle contient les derniers tours d'une conversation ou les données immédiates en cours de traitement. Elle est cruciale pour une interaction cohérente et en temps réel.
- Faits Récupérés (Base de Connaissances) : Souvent implémentée à l'aide de la Génération Augmentée par Récupération (RAG) et de bases de données vectorielles, cette couche permet aux agents d'accéder à de vastes dépôts d'informations externes et factuelles (documents, bases de données, contenu web). C'est ainsi qu'un agent connaît les politiques spécifiques de l'entreprise ou les spécifications techniques sans les avoir explicitement dans son contexte de travail.
- Préférences Utilisateur/Personnalisation : Cette mémoire durable stocke des informations à long terme sur les habitudes, les préférences, les interactions historiques et les données démographiques d'un utilisateur spécifique (avec des garanties de confidentialité appropriées). Elle permet des expériences personnalisées, se souvenant, par exemple, de la langue préférée d'un utilisateur ou de l'historique des commandes courantes.
- Historique des Tâches (Mémoire Épisodique) : Cette couche suit la séquence des actions, des décisions et des résultats au sein d'un flux de travail spécifique ou d'une série d'interactions au fil du temps. Elle permet à un agent de se souvenir qu'un client a appelé la semaine dernière pour un problème similaire, ou qu'une tâche particulière a été mise en pause et doit être reprise. C'est vital pour la continuité dans les processus complexes en plusieurs étapes.
- Mémoire Procédurale (Compétences et Outils) : Il ne s'agit pas de faits, mais de 'comment faire les choses'. Elle englobe les schémas appris, les capacités d'utilisation d'outils et les intégrations d'API qu'un agent peut exploiter pour atteindre des objectifs. C'est ainsi qu'un agent sait appeler une API spécifique pour vérifier l'inventaire ou générer un rapport.
Impact dans le Monde Réel : Cas d'Usage en Entreprise
Pour les entreprises, les implications d'une mémoire d'agent robuste sont profondes. Elle transforme les agents d'IA de chatbots réactifs en assistants intelligents et proactifs capables de gérer des tâches complexes et de longue durée :
- Flux de Travail de Support de Longue Durée : Un agent peut se souvenir de l'historique complet du support d'un client, des étapes de dépannage précédentes et des configurations spécifiques du produit à travers de multiples interactions, éliminant ainsi le besoin pour le client de se répéter.
- Agents de Codage : Un assistant de codage peut conserver la connaissance de l'architecture d'un projet, des normes de codage, des bibliothèques préférées et des refactorisations passées. Il peut comprendre le style du développeur et fournir des suggestions plus pertinentes contextuellement sur des jours ou des semaines.
- Assistants de Recherche : Pour les analystes ou les chercheurs, un agent d'IA peut suivre les requêtes précédentes, les sources examinées, les principales conclusions extraites et les objectifs généraux de la recherche, construisant une base de connaissances cumulative qui évolue avec le projet.
- Automatisation Opérationnelle : Les agents surveillant des systèmes complexes peuvent apprendre des incidents passés, se souvenir des étapes de remédiation spécifiques qui ont fonctionné (ou échoué) et comprendre l'état historique de divers composants, conduisant à une automatisation plus intelligente et plus résiliente.
L'Approche Responsable : Risques et Considérations
Bien que puissante, la mémoire d'agent n'est pas sans défis. Une approche équilibrée est cruciale :
- Mémoires Obsolètes : Les informations stockées en mémoire peuvent devenir obsolètes. Des mécanismes de mise à jour, d'invalidation ou de rafraîchissement des mémoires sont essentiels pour empêcher les agents d'agir sur des données incorrectes.
- Mauvaise Récupération/Hallucinations : Si le mécanisme de récupération est défectueux ou si les mémoires stockées sont inexactes, l'agent pourrait 'halluciner' ou agir sur des prémisses incorrectes, de la même manière qu'un LLM peut générer de fausses informations.
- Fuites de Confidentialité et de Sécurité : Le stockage de données sensibles d'utilisateurs ou d'entreprises dans des couches de mémoire introduit des risques significatifs pour la confidentialité et la sécurité. Une gouvernance robuste, des contrôles d'accès et des techniques d'anonymisation des données sont primordiaux. L'injection de requêtes via des données récupérées est également une préoccupation si les données externes ne sont pas correctement assainies.
- Sur-ingénierie : Comme l'a averti Microsoft Learn, ne compliquez pas trop. L'orchestration multi-agents et les architectures de mémoire complexes ajoutent des frais de coordination, de latence et de coût. Pour des tâches simples et ponctuelles, une fenêtre contextuelle plus grande pourrait en effet être suffisante. La clé est la discipline architecturale – choisir le bon outil pour le travail.
- Gouvernance : Qui possède les mémoires ? Comment sont-elles auditées ? Comment garantir la conformité aux politiques de rétention des données ? Ces questions deviennent critiques à mesure que les systèmes de mémoire mûrissent.
Conclusion
En 2026, la discussion autour des agents d'IA a dépassé la simple taille de leur capacité de traitement linguistique. Bien que des fenêtres contextuelles toujours plus grandes soient un outil précieux, elles ne remplacent pas les systèmes de mémoire intelligents. Pour les agents d'IA de niveau entreprise et du monde réel qui doivent fonctionner efficacement au fil du temps, une mémoire durable et une orchestration réfléchie du contexte sont primordiales. Il s'agit de construire des systèmes qui ne se contentent pas de traiter l'information, mais qui comprennent, s'adaptent et apprennent véritablement de leurs expériences. En concevant soigneusement les couches de mémoire et en comprenant leurs compromis, nous pouvons construire des agents d'IA non seulement puissants, mais aussi fiables, efficaces et véritablement utiles, aidant les entreprises à relever des défis complexes sans surcharge architecturale inutile.