Les Technologies d'Amélioration de la Confidentialité Passent de la Théorie de la Conformité à l'Infrastructure de Données
Le paysage de la confidentialité des données connaît une transformation profonde, passant d'un exercice de conformité théorique à un impératif architectural fondamental. Pendant des années, les Technologies d'Amélioration de la Confidentialité (PETs) ont été largement discutées dans les cercles juridiques et universitaires, considérées comme des concepts avancés pour des applications de niche. Cependant, un point d'inflexion critique est arrivé : les systèmes de préservation de la confidentialité se transforment rapidement en infrastructure de données grand public, car la centralisation des données brutes et sensibles devient trop risquée, trop réglementée et trop fragile sur le plan opérationnel. Cette évolution ne consiste pas seulement à adhérer à des réglementations plus strictes comme le GDPR ou le CCPA ; il s'agit de permettre une utilité continue des données et l'innovation dans un environnement où les violations de données sont coûteuses, la confiance du public est fragile et le filet réglementaire s'élargit constamment.
Le modèle traditionnel d'agrégation de vastes ensembles de données dans des lacs de données centraux pour l'analyse, le Machine Learning et la Business Intelligence est de plus en plus intenable. Le volume même d'informations sensibles crée une cible irrésistible pour les acteurs malveillants et une responsabilité significative pour les organisations. Par conséquent, l'accent est passé de la simple sécurisation des données au repos (at rest) et en transit (in transit) à la sécurisation des données en cours d'utilisation et à la facilitation de l'analyse collaborative sans exposition directe des données. Ce changement de paradigme exige l'adoption des PETs non pas comme une couche de sécurité facultative, mais comme des composants intégraux des pipelines de données modernes et des cadres de gouvernance, permettant aux organisations de tirer des informations et de construire des modèles à partir d'informations sensibles tout en minimisant l'exposition et en maximisant les garanties de confidentialité.
L'Impératif Opérationnel : Pourquoi les PETs sont Désormais une Infrastructure Essentielle
Le mouvement vers les PETs en tant qu'infrastructure essentielle est motivé par plusieurs facteurs convergents. Premièrement, le coût croissant des violations de données, tant financières que réputationnelles, impose une approche proactive de la protection des données. Deuxièmement, la mosaïque de lois mondiales sur la souveraineté des données et de réglementations sur la confidentialité rend le partage et le traitement des données transfrontaliers incroyablement complexes. Les organisations sont confrontées à un dilemme : exploiter les données pour un avantage concurrentiel ou risquer la non-conformité et les dommages à la réputation. Les PETs offrent une troisième voie cruciale, permettant l'utilité des données sans compromettre la confidentialité ni violer les mandats juridictionnels. Troisièmement, l'essor des modèles d'AI et de Machine Learning (ML), qui nécessitent souvent de grandes quantités de données diverses, rend nécessaires de nouvelles façons d'accéder et de traiter les informations sensibles sans créer de nouvelles vulnérabilités en matière de confidentialité. Les PETs fournissent les moyens techniques pour entraîner des modèles sur des ensembles de données distribués et sensibles sans jamais exposer les données brutes sous-jacentes.
Confidential Computing : Sécuriser les Données en Cours d'Utilisation
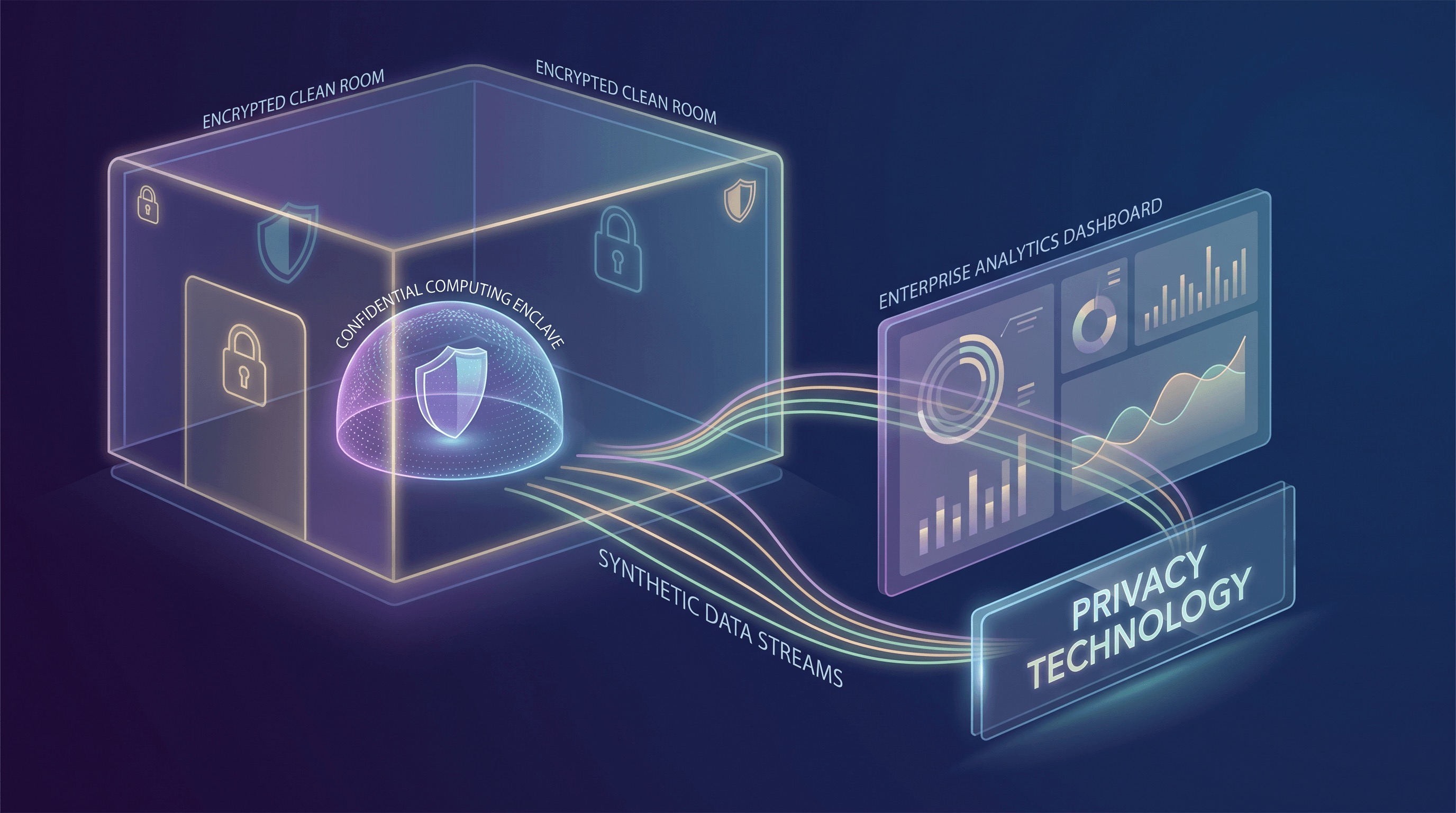
L'une des avancées les plus significatives des PETs est le Confidential Computing. Traditionnellement, la sécurité des données se concentrait sur le chiffrement au repos (stockage) et en transit (réseau). Le Confidential Computing complète cette triade en protégeant les données en cours d'utilisation – pendant qu'elles sont traitées par le CPU et la mémoire. Ceci est réalisé grâce à des Trusted Execution Environments (TEEs) basés sur le matériel, souvent appelés enclaves. Ces TEEs créent un environnement sécurisé et isolé au sein d'un CPU où les données et le code peuvent être traités avec de solides garanties d'intégrité et de confidentialité, même vis-à-vis du fournisseur de cloud ou d'autres logiciels privilégiés sur la même machine.
Google Cloud, par exemple, définit le Confidential Computing comme une technologie qui chiffre les données en mémoire et pendant le calcul, garantissant que les données restent inaccessibles à l'infrastructure sous-jacente, y compris l'opérateur de cloud. Cette capacité est transformative. Cela signifie que les calculs sensibles, tels que le traitement des informations d'identification personnelle (PII) ou des algorithmes propriétaires, peuvent être effectués dans le cloud avec des niveaux d'assurance sans précédent. Le mouvement du marché autour du Confidential Computing est robuste, avec des offres couvrant désormais les Confidential VMs, les Confidential Spaces pour les charges de travail conteneurisées, les services d'attestation matérielle et des solutions spécialisées pour les cas d'utilisation d'Analytics et d'AI/ML. Cette large adoption signifie sa transition d'un concept de sécurité de niche à une primitive d'infrastructure cloud utilisable et évolutive, permettant des scénarios auparavant jugés trop risqués pour les environnements de cloud public.
Data Clean Rooms : Analyse Collaborative avec Confidentialité
Une autre PET puissante qui gagne du terrain est la Data Clean Room. Les Clean Rooms offrent un environnement sécurisé et contrôlé où plusieurs parties peuvent collaborer à l'analyse d'ensembles de données sensibles, souvent superposés, sans exposer directement leurs données brutes les unes aux autres. Ceci est particulièrement précieux pour la mesure publicitaire, la détection de fraudes et l'optimisation de la chaîne d'approvisionnement, où les informations nécessitent de combiner des données provenant de différentes organisations. Le principe fondamental est que seules les informations agrégées et respectueuses de la confidentialité sont partagées, jamais les données brutes au niveau individuel.
AWS Clean Rooms illustre cette tendance, offrant un service qui permet aux clients d'analyser et de collaborer en toute sécurité sur leurs ensembles de données combinés sans partager ni révéler les données sous-jacentes. Une caractéristique notable est l'introduction de la génération d'ensembles de données synthétiques (Synthetic Dataset Generation) améliorant la confidentialité pour l'entraînement de ML au sein de ces Clean Rooms. Cette capacité est cruciale : elle permet aux organisations de créer des versions synthétiques statistiquement représentatives de leurs données sensibles. Ces ensembles de données synthétiques préservent les modèles et les relations statistiques essentiels trouvés dans les données originales, ce qui les rend adaptés à l'entraînement de modèles ML, tout en réduisant considérablement le risque de ré-identification et d'inférence d'appartenance. AWS fournit des métriques de fidélité et de confidentialité pour aider les utilisateurs à comprendre les compromis et à s'assurer que les données synthétiques répondent à leurs exigences d'utilité et de confidentialité. Cette innovation répond directement au défi de construire des modèles d'AI puissants qui nécessitent des données étendues sans encourir toutes les responsabilités en matière de confidentialité liées au partage ou à la centralisation des PII brutes.
Synthetic Data : Un Outil de Confidentialité Polyvalent
Au-delà de son application dans les Clean Rooms, les Synthetic Data émergent comme une Technologie d'Amélioration de la Confidentialité polyvalente et autonome. Les données générées qui imitent statistiquement les données réelles mais ne contiennent aucun enregistrement individuel réel offrent une solution puissante pour le développement, les tests et même certaines tâches analytiques. La capacité à générer des ensembles de données synthétiques de haute fidélité permet aux développeurs de construire et de tester des applications en utilisant des données réalistes sans jamais toucher les PII de production. Cela accélère les cycles de développement, réduit la charge de conformité et minimise la surface d'attaque associée à la gestion d'informations sensibles dans des environnements non-production.
La sophistication de la génération de Synthetic Data a considérablement progressé, tirant parti des modèles d'AI générative (Generative AI) pour capturer les corrélations et les distributions complexes présentes dans les données originales. Cela garantit que les modèles entraînés sur des données synthétiques fonctionnent de manière similaire à ceux entraînés sur des données réelles, ce qui en fait une alternative viable pour de nombreux flux de travail ML. La clé est d'équilibrer l'utilité et la confidentialité, en s'assurant que les données synthétiques sont suffisamment utiles pour leur objectif prévu tout en offrant de solides garanties contre la ré-identification.
Federated Analysis : Apprendre sans Centralisation
L'Federated Analysis, y compris son application plus spécifique dans le Federated Learning, représente une autre PET critique pour les environnements de données distribués. Au lieu de centraliser les données brutes provenant de multiples sources (par exemple, différents appareils, organisations ou régions géographiques) en un seul endroit pour l'analyse ou l'entraînement de modèles, les méthodes fédérées amènent le calcul aux données. Dans le Federated Learning, par exemple, un modèle global est entraîné en envoyant les paramètres du modèle à des appareils locaux ou à des silos de données. Chaque entité locale entraîne le modèle sur ses données privées, et seuls les paramètres du modèle mis à jour (ou les gradients) sont renvoyés à un serveur central, où ils sont agrégés pour améliorer le modèle global. Les données brutes ne quittent jamais leur emplacement d'origine.
Cette approche est particulièrement précieuse pour les scénarios impliquant des données très sensibles distribuées sur de nombreux points de terminaison, tels que les dossiers médicaux dans différents hôpitaux ou les données d'utilisateurs sur des appareils mobiles individuels. Elle permet des analyses collaboratives et l'entraînement de modèles sur des ensembles de données divers sans les immenses défis de confidentialité et logistiques liés au regroupement de données brutes. L'Federated Analysis soutient intrinsèquement la souveraineté des données et minimise le risque de violations de données à grande échelle, car aucune entité unique ne détient jamais toutes les informations brutes.
Les PETs comme Nouvelle Fondation de l'Architecture de Données
L'intégration de ces Technologies d'Amélioration de la Confidentialité signifie un changement fondamental dans la façon dont les organisations abordent la gouvernance et l'utilisation des données. Elles ne sont plus de simples fonctionnalités de sécurité "agréables à avoir" ou des curiosités académiques complexes. Au lieu de cela, les PETs deviennent l'architecture technique qui permet aux entreprises de continuer à exploiter efficacement les données sensibles sous des attentes de plus en plus strictes en matière de confidentialité, de souveraineté des données et d'AI governance. Cela signifie que les architectes de données, les ingénieurs et les responsables de la confidentialité doivent de plus en plus comprendre et mettre en œuvre des solutions telles que le Confidential Computing, les Data Clean Rooms, la génération de Synthetic Data et l'Federated Analysis comme composants standard de leur infrastructure de données.
L'avenir de l'innovation axée sur les données dépend de la capacité à extraire de la valeur des informations sensibles de manière responsable. Les PETs constituent le pont crucial entre l'utilité des données et la protection de la confidentialité. À mesure que ces technologies mûrissent et deviennent plus accessibles grâce aux offres des fournisseurs de cloud et aux initiatives open-source, leur adoption s'accélérera, remodelant fondamentalement la manière dont les données sont collectées, traitées, partagées et analysées dans toutes les industries. L'ère de la centralisation des données brutes sans conséquence touche à sa fin ; l'ère de l'infrastructure de données intelligente et respectueuse de la confidentialité ne fait que commencer.