La Bande Passante Mémoire et les Thermiques Déterminent les Performances Réelles des Ordinateurs Portables AI
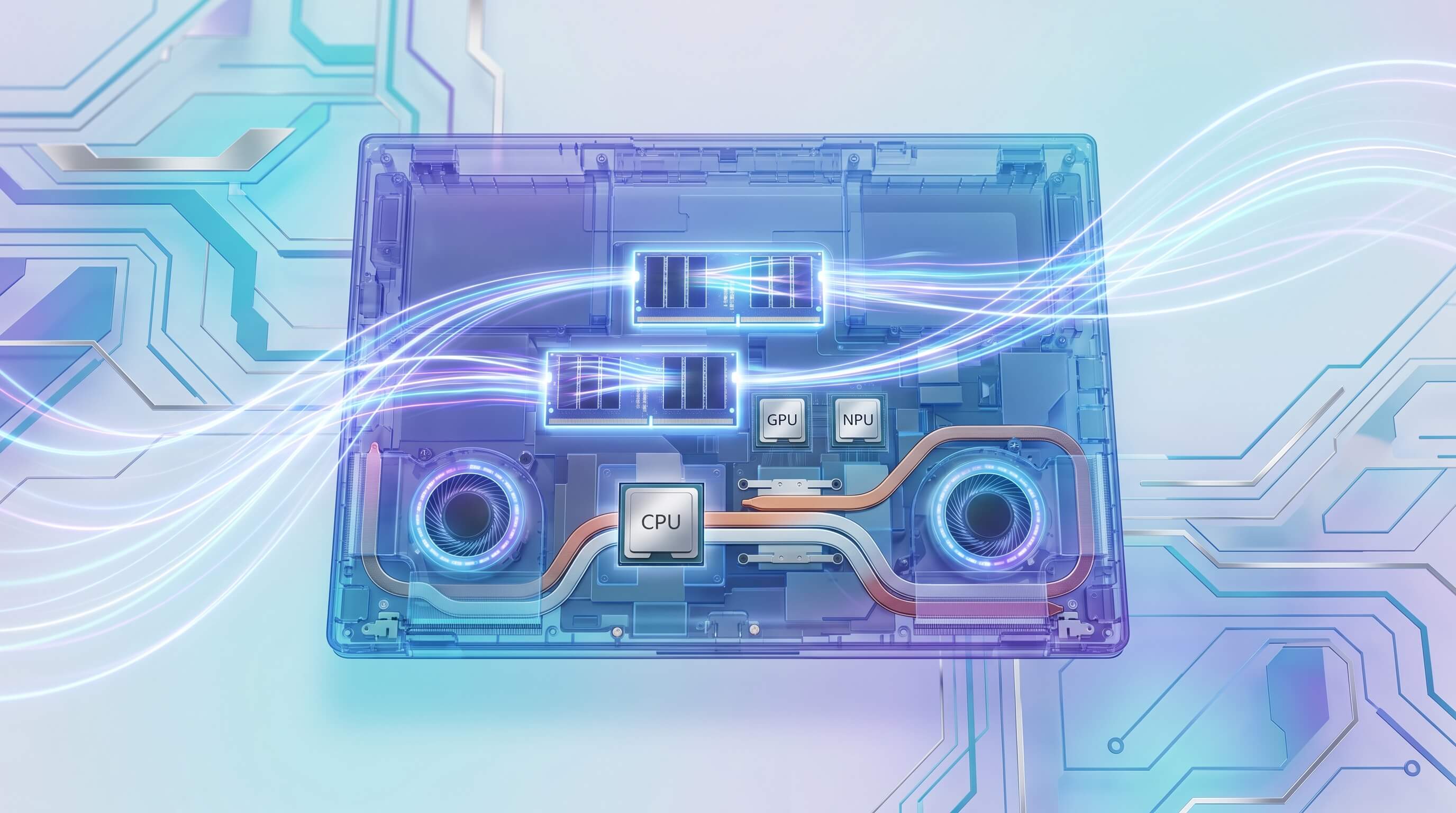
Le marketing autour des ordinateurs portables AI en 2024 et 2025 met fortement l'accent sur les Unités de Traitement Neuronal (NPU) et leurs évaluations en Tera Operations Per Second (TOPS). Avec l'avènement des PC Copilot+ nécessitant un minimum de 40 TOPS, les consommateurs sont amenés à croire qu'un nombre élevé de NPU se traduit directement par de solides capacités AI locales. Cependant, cette focalisation masque les véritables goulots d'étranglement architecturaux qui dictent les performances pratiques pour l'exécution de grands modèles de langage (LLMs) ou la génération d'images complexes localement. Bien que les NPUs soient un composant critique pour l'inférence AI économe en énergie, leur puissance de calcul brute est souvent rendue caduque par les limitations de la bande passante mémoire, de la capacité de RAM disponible et de la capacité de l'ordinateur portable à maintenir les performances sous charge thermique.
Pour toute charge de travail AI locale sérieuse, qu'il s'agisse d'exécuter un LLM sophistiqué comme Llama 3 ou de générer des images haute résolution avec Stable Diffusion, la capacité du système à déplacer de vastes quantités de données rapidement et efficacement est primordiale. Une NPU puissante avec 40 ou même 70 TOPS restera inactive ou sous-utilisée si elle ne peut pas être alimentée en données assez rapidement, ou si le modèle lui-même ne peut pas résider entièrement dans la mémoire accessible. Cet article analysera les rôles de la CPU, GPU et NPU, expliquera pourquoi l'architecture mémoire et la conception thermique sont les héros méconnus des performances des ordinateurs portables AI, et fournira des informations exploitables aux consommateurs cherchant au-delà du battage marketing pour prendre des décisions d'achat éclairées pour 2026 et au-delà.
Au-delà des TOPS NPU : Comprendre le Paysage de Calcul AI
Les Unités de Traitement Neuronal sont des accélérateurs spécialisés conçus pour gérer efficacement les multiplications matricielles et autres opérations courantes dans les réseaux neuronaux. Leur principal avantage réside dans leur efficacité énergétique pour des tâches spécifiques d'inférence AI, ce qui les rend idéales pour les effets d'arrière-plan comme la correction du contact visuel, la suppression du bruit ou la segmentation simple d'images. Des entreprises comme Qualcomm, Intel et AMD intègrent toutes des NPUs de plus en plus puissantes dans leurs processeurs mobiles, avec des benchmarks soulignant souvent leurs chiffres TOPS impressionnants.
Cependant, les TOPS seuls ne représentent qu'une facette des performances AI. Considérez les rôles distincts des trois unités de traitement principales dans un ordinateur portable moderne :
- CPU (Central Processing Unit) : Cheval de bataille polyvalent, la CPU orchestre les opérations du système, gère le flux de données et peut exécuter des modèles AI, en particulier les plus petits ou ceux non optimisés pour du matériel spécialisé. Elle excelle dans les tâches sensibles à la latence et fournit un recours pour les charges de travail non adaptées au GPU ou NPU.
- GPU (Graphics Processing Unit) : Puissance de traitement parallèle, les GPUs sont indispensables pour l'entraînement de grands modèles AI et pour l'exécution de tâches d'inférence complexes qui nécessitent un calcul parallèle massif. Leur architecture, en particulier avec une VRAM dédiée, offre une bande passante mémoire significativement plus élevée que la RAM système typique, ce qui les rend idéales pour les LLMs à grande échelle et la génération d'images où les poids du modèle et les données intermédiaires sont substantiels.
- NPU (Neural Processing Unit) : Optimisées pour des schémas d'inférence AI spécifiques, les NPUs offrent une efficacité énergétique supérieure pour les tâches récurrentes. Elles sont excellentes pour décharger certaines computations AI de la CPU ou du GPU, prolongeant ainsi la durée de vie de la batterie et libérant d'autres ressources. Cependant, leur efficacité dépend fortement de l'optimisation logicielle et de l'architecture spécifique du modèle. De nombreux LLMs non quantifiés de grande taille ou des modèles de diffusion complexes ne peuvent tout simplement pas s'exécuter entièrement ou efficacement sur les NPUs actuelles en raison de la taille du modèle et des limitations architecturales.
La synergie entre ces composants est cruciale. Une NPU pourrait accélérer une partie spécifique d'un pipeline AI, mais si les étapes précédentes ou suivantes sont limitées par les performances de la CPU ou, plus communément, par les vitesses de transfert de données, l'expérience utilisateur globale en souffre.
La Dominance Indéniable de la Bande Passante et de la Capacité Mémoire
Lors de l'exécution de modèles AI substantiels localement, le facteur le plus critique souvent négligé est la mémoire. Cela englobe à la fois la capacité pure de la RAM et, plus important encore, la vitesse à laquelle les données peuvent être déplacées vers et depuis cette RAM — la bande passante mémoire.
Capacité de RAM : Plus qu'un Simple Chiffre
Les grands modèles de langage sont précisément cela : grands. Un LLM commun de 7 milliards de paramètres, même quantifié (précision réduite) à des entiers de 4 bits, peut encore nécessiter environ 8 Go de RAM juste pour ses poids. Ajoutez à cela l'espace nécessaire pour les activations, la fenêtre de contexte (la partie du prompt et du texte généré que le modèle "retient"), le système d'exploitation et d'autres applications en cours d'exécution, et 16 Go de RAM deviennent rapidement un minimum absolu, souvent insuffisant pour une expérience fluide. Pour des modèles plus performants (par exemple, 13 milliards de paramètres ou plus) ou pour exécuter plusieurs modèles simultanément, 32 Go ou même 64 Go de RAM deviennent essentiels. Sans RAM adéquate, le système recourt à l'échange de données vers un stockage SSD plus lent, ce qui entraîne une dégradation significative des performances et des saccades.
Bande Passante Mémoire : Le Héros Méconnu
Même avec une RAM abondante, si les données ne peuvent pas être accédées assez rapidement, la NPU ou le GPU manquera de données. La bande passante mémoire mesure la quantité de données pouvant être lues ou écrites en mémoire par seconde. Les modèles AI brassent constamment de vastes quantités de données — poids du modèle, prompts d'entrée, calculs intermédiaires et tokens de sortie — entre la mémoire principale et les unités de traitement. Si la bande passante mémoire est faible, la NPU ou le GPU, malgré son indice TOPS élevé, passera une quantité disproportionnée de temps à attendre les données, devenant ainsi un goulot d'étranglement. Cela se traduit directement par des temps d'inférence plus lents pour les LLMs et des temps de génération plus longs pour les modèles d'images.
Les ordinateurs portables modernes utilisent généralement de la mémoire LPDDR5X ou DDR5. Bien que la LPDDR5X offre souvent une bande passante plus élevée et une meilleure efficacité énergétique que la DDR5 standard dans un format mobile, la configuration spécifique est importante. Des facteurs tels que le nombre de canaux mémoire (par exemple, des interfaces mémoire de 256 bits courantes dans les Apple Silicon, contre des interfaces plus étroites de 128 bits dans de nombreux ordinateurs portables PC) et la vitesse d'horloge de la mémoire ont un impact significatif sur la bande passante globale. Un processeur avec une NPU à TOPS élevés associé à un sous-système mémoire étroit et à faible bande passante sera inévitablement moins performant qu'un système avec une architecture équilibrée, même si ce dernier a un nombre de TOPS NPU théoriquement inférieur.
Vitesse de Stockage : L'Obstacle Initial
Bien que n'étant pas strictement de la "mémoire" au même titre que la RAM, la vitesse du périphérique de stockage de votre ordinateur portable (SSD) joue un rôle crucial dans les performances de l'AI. Les grands modèles AI doivent être chargés du stockage vers la RAM avant de pouvoir être utilisés. Un SSD NVMe PCIe Gen4 ou Gen5 rapide garantit que ce processus de chargement initial est rapide. De plus, si votre capacité de RAM est insuffisante et que le système doit échanger des parties du modèle vers le disque, un SSD haute vitesse atténue l'impact sur les performances, bien qu'il soit toujours significativement plus lent que la RAM.
Le Rôle Critique des Thermiques dans les Performances Soutenues
Les charges de travail AI sont intrinsèquement gourmandes en calcul et souvent soutenues. Contrairement aux tâches en rafale comme l'ouverture d'une application ou le chargement d'une page web, l'exécution d'un LLM pour générer une longue réponse ou l'itération sur un prompt de génération d'images peut maintenir la CPU, le GPU et la NPU sous forte charge pendant des périodes prolongées. Cette computation continue génère une chaleur significative.
Les ordinateurs portables, par leur nature même, sont contraints par leurs facteurs de forme compacts et leurs solutions de refroidissement limitées. Lorsque les composants atteignent un certain seuil de température, le système "étrangle" automatiquement les performances pour éviter la surchauffe et les dommages potentiels. Cela signifie qu'un ordinateur portable affichant des scores de benchmark impressionnants pendant quelques secondes pourrait réduire drastiquement ses vitesses d'horloge et sa consommation d'énergie lorsqu'il est confronté à une tâche AI réelle et soutenue. La NPU annoncée de 40+ TOPS pourrait ne délivrer ses performances maximales que pendant une courte rafale, puis chuter significativement, entraînant une expérience frustrante et lente.
Une gestion thermique efficace — incluant des systèmes de refroidissement robustes avec chambres à vapeur, des ventilateurs plus grands et des conceptions de caloducs efficaces — est donc primordiale. Un ordinateur portable conçu pour des performances élevées soutenues sera doté d'une solution de refroidissement plus avancée, permettant à la CPU, au GPU et à la NPU de fonctionner à des vitesses d'horloge plus élevées pendant des durées plus longues. Lors de l'évaluation des ordinateurs portables AI, regardez au-delà des chiffres de benchmark initiaux et recherchez des critiques qui testent spécifiquement les performances soutenues sous une charge lourde et continue. Cette distinction entre performances en rafale et performances soutenues est un facteur clé de différenciation pour les applications AI pratiques.
Implications Pratiques pour les Charges de Travail AI Locales
Comprendre ces goulots d'étranglement offre une image plus claire de ce que l'on peut attendre d'un ordinateur portable AI :
- LLMs : L'exécution locale d'un LLM de 7 milliards de paramètres avec une fenêtre de contexte décente nécessite au moins 16 Go de RAM, mais 32 Go offrent une expérience beaucoup plus fluide, permettant des fenêtres de contexte plus grandes et potentiellement l'exécution de plusieurs modèles ou d'autres applications simultanément. La vitesse d'inférence (tokens par seconde) sera directement liée à la bande passante mémoire. Les techniques de Quantization (par exemple, Q4, Q8) sont cruciales pour faire tenir des modèles plus grands dans la RAM disponible, mais elles s'accompagnent d'un compromis en termes de précision ou de Perplexity.
- Génération d'Images : Les modèles comme Stable Diffusion sont très exigeants, surtout pour des résolutions plus élevées ou des prompts complexes. Bien que les NPUs puissent aider avec certaines étapes de pré-traitement, la génération principale repose souvent fortement sur le GPU et sa VRAM dédiée. Les ordinateurs portables sans GPU discret auront du mal avec la génération d'images, même avec une NPU à TOPS élevés, car le GPU intégré partage la RAM du système et sa bande passante est limitée.
- RAG (Retrieval Augmented Generation) : L'implémentation de systèmes RAG locaux implique le stockage de grandes bases de données vectorielles (sollicitant la vitesse du SSD), le chargement de fragments pertinents dans la RAM (sollicitant la capacité et la bande passante de la RAM), puis l'utilisation d'un LLM pour la génération (sollicitant la NPU/GPU/CPU et la mémoire). Chaque composant doit être robuste pour que RAG soit efficace.
Alors que Qualcomm, Intel et AMD poussent tous leurs capacités NPU, l'architecture système sous-jacente reste le véritable déterminant des performances AI réelles. Les puces Snapdragon X Elite/Plus de Qualcomm, par exemple, affichent des TOPS NPU impressionnants et une excellente efficacité énergétique, mais leur prouesse AI globale dans les tâches exigeantes dépendra toujours du sous-système mémoire avec lequel elles sont associées. De même, les processeurs Core Ultra (Meteor Lake) et les prochains Lunar Lake d'Intel, ainsi que les puces Ryzen AI d'AMD, intègrent des NPUs puissantes aux côtés de CPUs capables et de GPUs intégrés. L'équilibre entre ces composants, en particulier la bande passante mémoire et la conception thermique, est ce qui compte finalement.
Points Clés : Prioriser les Spécifications pour Votre Prochain Ordinateur Portable AI (2026)
Lorsque vous envisagez un ordinateur portable AI, regardez au-delà du chiffre de TOPS NPU. Voici ce qu'il faut prioriser pour des performances AI locales véritablement capables :
- La Capacité de RAM est Reine : Visez un minimum de 32 Go de RAM. Si votre budget le permet et que l'AI locale est une priorité, 64 Go offriront une marge de manœuvre nettement supérieure pour les modèles plus grands et les flux de travail complexes.
- Bande Passante Mémoire Élevée : Recherchez les ordinateurs portables dotés de mémoire LPDDR5X ou DDR5 haute vitesse. Renseignez-vous sur la largeur de l'interface mémoire si possible ; les interfaces plus larges (par exemple, 256 bits) offrent une bande passante supérieure. Cette spécification est souvent moins publicisée mais est critique.
- Système de Refroidissement Robuste : Recherchez des critiques professionnelles qui testent les performances soutenues sous de lourdes charges CPU, GPU et NPU. Un ordinateur portable qui maintient des vitesses d'horloge élevées pendant des périodes prolongées sans throttling est un indicateur fort d'une bonne conception thermique.
- SSD NVMe Rapide : Assurez-vous que votre ordinateur portable est équipé d'un SSD NVMe PCIe Gen4 ou, idéalement, Gen5. Cela accélère le chargement des modèles et atténue les baisses de performances si le système doit échanger des données.
- Considérez un GPU Discret pour des Tâches Spécifiques : Si votre cas d'utilisation principal de l'AI locale implique une génération d'images lourde ou de très grands LLMs qui bénéficient de la VRAM dédiée, un ordinateur portable avec un GPU discret (même de milieu de gamme) offrira des performances supérieures par rapport à une dépendance exclusive à un GPU intégré et une NPU.
- Les TOPS NPU comme Ligne de Base : Considérez l'exigence de 40+ TOPS pour Copilot+ comme un point d'entrée nécessaire, mais pas comme le seul facteur de différenciation. Une fois ce seuil atteint, concentrez votre attention sur les autres composants du système qui débloquent véritablement le potentiel de la NPU.
L'avenir de l'AI sur les ordinateurs portables est prometteur, mais naviguer dans le paysage marketing exige une compréhension plus approfondie des principes matériels sous-jacents. En priorisant la bande passante mémoire, la capacité de RAM et la gestion thermique aux côtés des capacités NPU, les consommateurs peuvent choisir un ordinateur portable qui tient la promesse d'une AI locale puissante et efficace.