Au cœur du NPU : pourquoi toutes les grandes puces ont désormais un moteur neuronal — et ce qu'il fait réellement
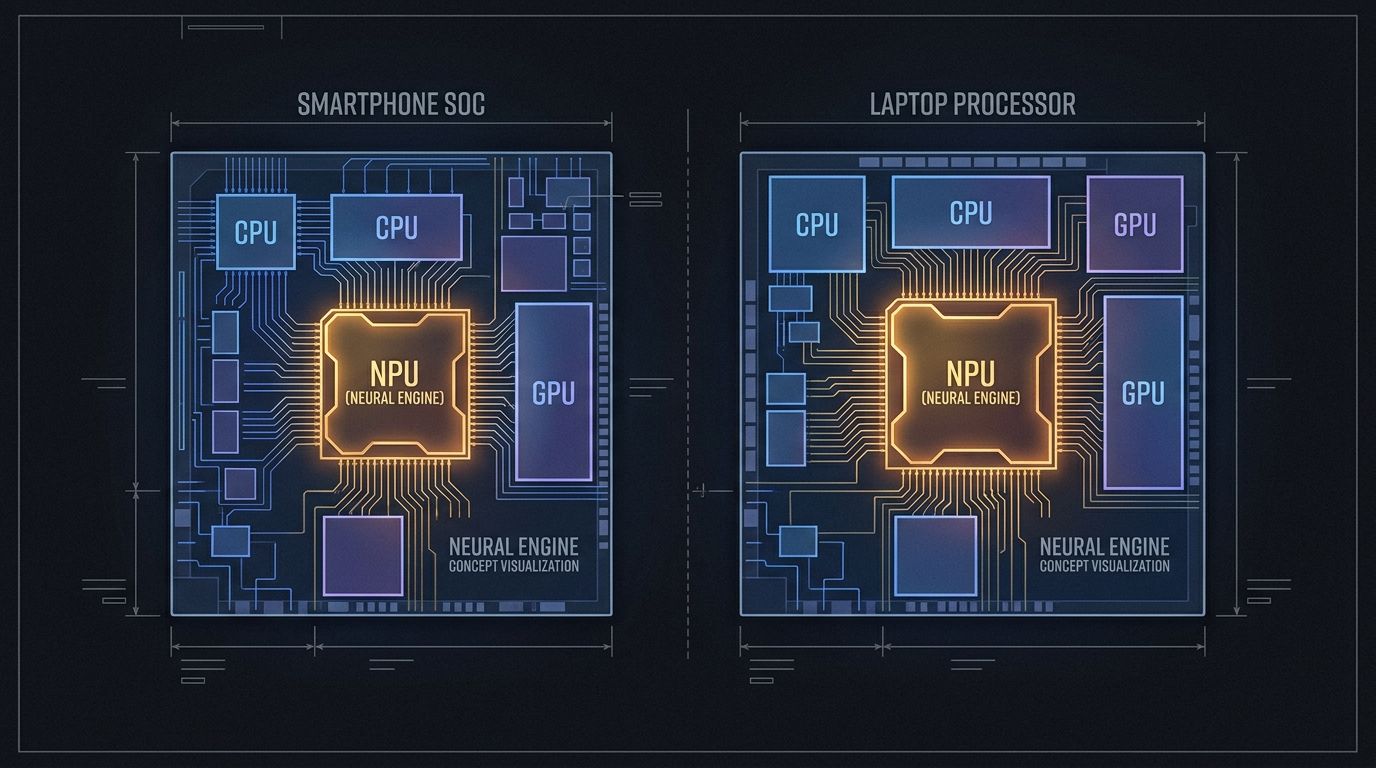
Une transition matérielle silencieuse se prépare depuis trois ans, et en 2026, elle est essentiellement achevée : presque tous les processeurs grand public expédiés par Apple, Qualcomm, Intel, AMD et MediaTek incluent désormais une unité de traitement neuronal dédiée. Le NPU n'est plus une spécification pour passionnés. C'est la nouvelle norme.
Ce changement est suffisamment significatif pour que le programme de certification Copilot+ de Windows 11 ait fait d'un minimum de 40 TOPS pour le NPU une condition stricte pour la certification. En pratique, que font ces puces — et pourquoi le matériel GPU et CPU existant ne pouvait-il pas gérer les mêmes charges de travail ?
Pourquoi une puce séparée pour l'IA
Le GPU n'a pas disparu de la pile IA — il reste le substrat de calcul dominant pour l'entraînement et l'inférence à grande échelle dans les centres de données. Mais les GPU sont gourmands en énergie et optimisés pour le parallélisme à grande échelle. Un téléphone ou un ordinateur portable utilisant un GPU mobile pour une inférence IA continue — suppression du bruit de fond, traduction en temps réel, amélioration vidéo — viderait la batterie en quelques heures.
Les NPU résolvent ce problème par la spécialisation. Contrairement à un GPU (qui exécute des charges de travail parallèles générales) ou à un CPU (qui excelle dans la logique séquentielle et ramifiée), un NPU est spécifiquement conçu pour les multiplications matricielles et les fonctions d'activation qui dominent l'inférence des réseaux neuronaux. Le résultat est une efficacité énergétique des ordres de grandeur meilleure pour un ensemble limité mais croissant de tâches.
Apple expédie des NPU depuis l'A11 Bionic en 2017, initialement commercialisé sous le nom de "Neural Engine" pour Face ID. Le Neural Engine de l'A11 exécutait 600 milliards d'opérations par seconde. L'A18 Pro de l'iPhone 16 Pro atteint 35 TOPS — une amélioration de près de 60 fois en neuf ans, sur une puce qui tient toujours dans un téléphone.
Le paysage actuel par plateforme
Le Snapdragon X Elite de Qualcomm, la puce qui alimente la plupart des ordinateurs portables Windows Copilot+ sortis en 2024-2025, délivre 45 TOPS via son NPU Hexagon. Qualcomm affirme une efficacité par watt 4,5 fois meilleure que l'inférence GPU comparable sur les mêmes tâches — un chiffre qui tient raisonnablement bien dans les tests indépendants.
Le M4 Pro d'Apple atteint 38 TOPS avec son Neural Engine, Apple signalant des gains substantiels sur les benchmarks Core ML par rapport à la génération M3. Les puces de la série M bénéficient d'une architecture mémoire unifiée — le Neural Engine partage le même pool de mémoire à haute bande passante que le CPU et le GPU, éliminant la surcharge de copie qui handicape l'inférence GPU discrète sur les petits modèles.
La série Core Ultra 200 d'Intel (Lunar Lake) marque le NPU le plus compétitif d'Intel à ce jour avec 48 TOPS — conçu spécifiquement pour franchir le seuil Copilot+ avec une marge permettant de futures exigences IA de Windows. La série Ryzen AI 300 d'AMD atteint 50 TOPS. Le Dimensity 9400 de MediaTek, qui alimente la série Samsung Galaxy S25, atteint 50 TOPS avec des gains d'efficacité significatifs par rapport à la génération précédente.
Ce que les NPU exécutent réellement
Les cas d'utilisation se répartissent en catégories cohérentes :
Tâches continues et sensibles à la latence. Transcription en temps réel (Live Text d'Apple, clarté vocale Windows Studio), floutage d'arrière-plan dans les appels vidéo et suppression active du bruit sont des tâches pour lesquelles la latence du GPU est trop élevée et les allers-retours vers le cloud introduisent un retard inacceptable. Les NPU gèrent ces tâches en continu avec une consommation d'énergie minimale.
Inférence LLM sur l'appareil. Les modèles de la gamme 1B à 8B paramètres — Phi-3 Mini, Gemma 3 4B, Llama 3.2 3B — peuvent s'exécuter entièrement sur l'appareil via le NPU lorsqu'ils sont quantifiés en précision 4 bits. L'architecture Private Cloud Compute d'Apple ne décharge que les tâches trop volumineuses pour le Neural Engine. Sous Windows, Phi-3 Mini de Microsoft s'exécute nativement via DirectML sur le NPU Hexagon pour les réponses Copilot sur l'appareil.
Photographie computationnelle. Fusion HDR en temps réel, segmentation sémantique pour le remplacement d'arrière-plan, suivi du maillage facial pour la RA — ce sont des charges de travail NPU sur tous les smartphones phares actuels. Le pipeline de traitement de l'appareil photo a largement migré de l'ISP vers le NPU au cours des trois dernières années.
Indexation de recherche et de récupération. Windows Recall utilise le NPU pour traiter en continu les captures d'écran et créer un index sémantique interrogeable. La recherche Photos sur l'appareil d'Apple utilise le Neural Engine pour l'incorporation d'images et la correspondance de similarité.
Le problème du benchmark
Le TOPS est une métrique trompeuse. Elle mesure le débit de pointe dans des conditions idéales — multiplication matricielle soutenue avec toutes les unités d'exécution actives. Les charges de travail réelles de l'IA sont plus irrégulières et sporadiques. Un NPU de 50 TOPS exécutant un modèle mal optimisé peut être moins performant qu'une puce de 35 TOPS avec un meilleur support du compilateur et une architecture mémoire plus adaptée.
La norme émergente pour l'évaluation comparative pratique des NPU est MLPerf Mobile, qui mesure les performances de bout en bout sur des modèles standardisés plutôt que sur des TOPS bruts. L'écart entre les spécifications papier et les résultats MLPerf peut être important. Certaines puces à haut TOPS sont nettement moins performantes sur des tâches qui n'étaient pas centrales dans leur conception.
Ce que cela signifie pour les développeurs
L'existence de NPU largement déployés crée un nouveau niveau dans la pile de déploiement de l'IA. La division actuelle : inférence cloud pour les grands modèles (GPT-4, Claude 3.7+, Gemini 2.5), inférence NPU sur l'appareil pour les modèles jusqu'à ~8B paramètres en quantification 4 bits, et un niveau intermédiaire croissant d'inférence en périphérie de classe serveur pour les modèles de 13B à 70B.
Pour les développeurs créant des fonctionnalités basées sur l'IA, la question pratique est maintenant de savoir quel niveau d'inférence correspond au cas d'utilisation — pas seulement si l'inférence cloud est disponible. Les tâches ayant des exigences strictes en matière de confidentialité, des besoins de faible latence ou des contraintes hors ligne devraient cibler l'inférence sur l'appareil via Core ML, Windows ML ou Android NNAPI. Les frameworks arrivent à maturité. Le matériel est là.
La course au NPU ne ralentit pas. La plateforme Snapdragon de nouvelle génération de Qualcomm devrait dépasser les 70 TOPS. La famille A19 Pro d'Apple vise 45+ TOPS. La question n'est plus de savoir si votre appareil a une puce IA — mais quelles parties de votre charge de travail vous y avez déplacées.