Les Robots d'Exploration IA Transforment les Sites Web Ouverts en Cibles d'Infrastructure
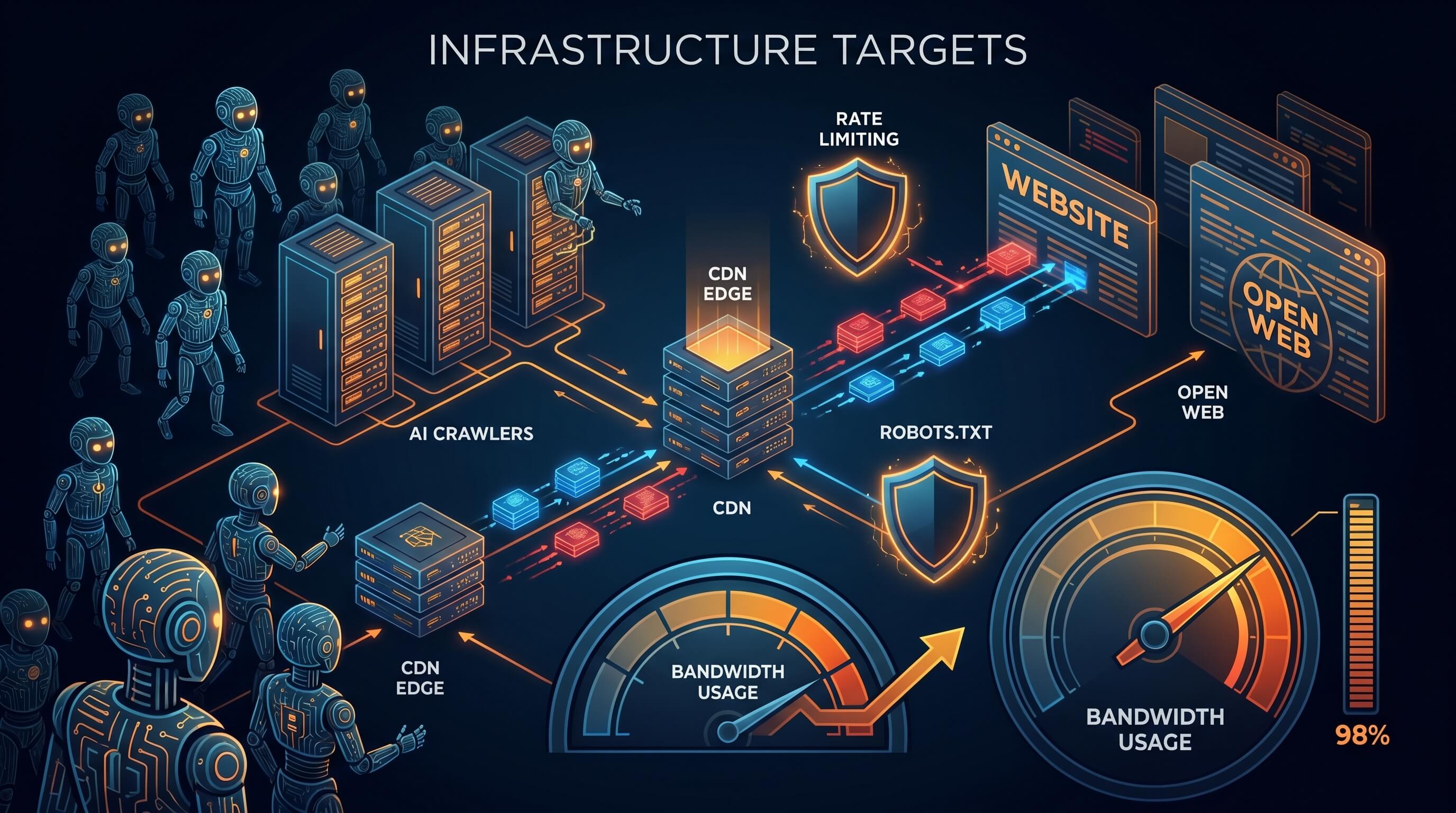
Pendant longtemps, publier sur le web reposait sur un compromis clair. Un site ouvrait ses pages, les moteurs les indexaient, puis des lecteurs humains arrivaient par la recherche et les liens. Ce compromis se fragilise. Les robots d'exploration IA visitent les sites ouverts à une échelle industrielle, souvent sans renvoyer une valeur de trafic comparable.
La conséquence est concrète: de plus en plus de sites sont traités comme des cibles d'infrastructure plutôt que comme des publications. Les factures CDN montent, les serveurs d'origine encaissent davantage de charge et robots.txt ressemble de plus en plus à une simple demande de bonne conduite.
Pourquoi le crawl IA diffère du crawl de recherche classique
Le crawl des moteurs de recherche n'a jamais été gratuit, mais il s'inscrivait dans un échange compréhensible. L'indexation apportait de la visibilité et du trafic. Avec les crawlers IA, ce lien devient beaucoup moins clair. Une plateforme peut crawler pour entraîner un modèle, alimenter une couche de retrieval ou générer des réponses synthétiques sans renvoyer un volume équivalent de visiteurs.
Dans ce cas, le crawler se comporte moins comme un partenaire de découverte que comme un extracteur de valeur.
La facture CDN devient une question éditoriale
Quand le trafic bot augmente, l'infrastructure cesse d'être un sujet purement technique. Elle commence à influencer les choix de publication. Un petit média, un blog spécialisé, une communauté ou une base de connaissance publique peut attirer peu de lecteurs humains mais exposer un grand nombre de pages faciles à crawler.
Le site devient alors plus coûteux à maintenir sans devenir plus utile pour son audience réelle. Cette pression pousse certains opérateurs vers des murs d'accès, des pages de challenge ou des restrictions plus fortes.
robots.txt perd son ancien contrat social
robots.txt a toujours été volontaire et non contraignant sur le plan sécuritaire. Pourtant, il fonctionnait assez bien parce que les grands robots avaient intérêt à rester prévisibles. Cette logique s'effrite.
De nombreux opérateurs supposent désormais que certains agents ignoreront robots.txt, reviendront sous de nouveaux identifiants ou n'en respecteront qu'une lecture minimale. Même un robot conforme ne garantit ni compensation ni attribution suffisante.
Le rate limiting devient la posture par défaut
Beaucoup de sites réservaient autrefois le rate limiting aux pics d'abus ou à la protection des connexions. Il devient aujourd'hui un mécanisme de base du web public. Les équipes limitent davantage les endpoints ouverts, classent les bots et filtrent plus tôt les requêtes suspectes.
Ce durcissement a un coût. Des limites trop agressives peuvent gêner l'automatisation légitime, les chercheurs, l'accessibilité et même l'indexation utile. L'objectif n'est donc pas de tout bloquer, mais de rendre le coût du crawl soutenable et prévisible.
Le vrai problème est l'asymétrie
Les grandes entreprises d'IA peuvent répartir le coût du crawl sur des plateformes massives et le considérer comme un investissement stratégique. Un petit éditeur ne peut pas répartir ainsi le coût de la défense. Chaque téraoctet supplémentaire, chaque réglage WAF et chaque heure d'ingénierie pèsent directement sur lui.
C'est pourquoi le web ouvert risque de devenir une couche subventionnée pour les systèmes d'IA. Le contenu reste public, mais le coût du maintien de cette ouverture est supporté par l'éditeur alors qu'une part croissante de la valeur est captée ailleurs.
Que faire maintenant pour les opérateurs de sites
Mesurer séparément le coût des bots
Isolez autant que possible la bande passante, le volume de requêtes, les cache misses et la charge origin selon les classes de bots.
Réduire les surfaces de crawl coûteuses
Auditez les archives, la navigation facettée, la recherche interne, les variantes d'URL et les flux peu utiles.
Déplacer la protection vers l'edge
Utilisez CDN et WAF pour absorber le trafic répétitif avant qu'il n'atteigne l'origine.
Définir des niveaux d'accès explicites
Tout n'a pas à être simplement ouvert ou fermé. L'accès intensif peut exiger clés API, quotas ou conditions commerciales.
Documenter la politique
Publiez une politique claire de crawl et de licence à côté de robots.txt pour mieux cadrer l'application et la négociation.
Le web ouvert a désormais besoin de défenses économiques
Les crawlers IA ne sont pas une nuisance passagère. Ils modifient le modèle économique de la publication ouverte. La conclusion pratique est claire: mesurer la charge bot, réduire les surfaces inutiles, imposer des limites à l'edge et réserver l'accès massif à des conditions explicites.
La prochaine phase du web sera définie non seulement par ce qui est publié, mais aussi par ceux qui peuvent encore se permettre de rester ouverts.