چرا هوش مصنوعی حفظکننده حریم خصوصی به زیرساخت داده سازمانی تبدیل میشود
در چشمانداز بهسرعت در حال تحول هوش مصنوعی، وعده بینشهای تحولآفرین اغلب با ضرورت حفظ حریم خصوصی دادهها در تضاد است. شرکتها در سراسر جهان با این چالش دست و پنجه نرم میکنند که چگونه از قدرت هوش مصنوعی بدون به خطر انداختن اطلاعات حساس، نقض مقررات سختگیرانه یا قرار گرفتن در معرض نقض فاجعهبار دادهها استفاده کنند. برای سالها، پارادایم غالب شامل متمرکز کردن مجموعههای داده عظیم در دریاچههای داده یکپارچه بود، رویهای که اگرچه برای آموزش مدل کارآمد بود، اما خطرات زیادی ایجاد میکرد. امروز، یک تغییر اساسی در حال وقوع است: هوش مصنوعی حفظکننده حریم خصوصی (PPAI) فراتر از کنجکاوی آکادمیک و کاربردهای خاص، به یک جزء اساسی از زیرساخت داده سازمانی تبدیل میشود.
معضل تمرکز داده و ظهور PPAI
رویکرد سنتی به توسعه هوش مصنوعی به شدت به تجمیع دادهها متکی است. چه سوابق مشتری، تراکنشهای مالی یا تاریخچه پزشکی باشد، هرچه یک مدل هوش مصنوعی به دادههای بیشتری دسترسی داشته باشد، معمولاً عملکرد بهتری دارد. با این حال، این تمرکز یک هدف واحد و بسیار جذاب برای مجرمان سایبری و یک کابوس انطباق برای سازمانها ایجاد میکند. مقرراتی مانند GDPR، HIPAA، CCPA و بیشمار دیگر، قوانین سختگیرانهای را در مورد نحوه جمعآوری، ذخیره، پردازش و به اشتراکگذاری دادههای شخصی و حساس اعمال میکنند. عدم انطباق نه تنها جریمههای سنگین، بلکه آسیبهای جدی به اعتبار را نیز به همراه دارد.
این معضل، توسعه و پذیرش فناوریهای PPAI را تسریع کرده است. PPAI مجموعهای از روشها را در بر میگیرد که برای اجازه دادن به مدلهای هوش مصنوعی برای یادگیری از دادهها بدون دسترسی مستقیم یا افشای اطلاعات خام و حساس طراحی شدهاند. این در مورد امکان همکاری و تولید بینش در عین حفظ بالاترین استانداردهای حریم خصوصی و امنیت است. این فقط یک ملاحظه اخلاقی نیست؛ بلکه یک ضرورت استراتژیک برای هر شرکتی است که با دادههای حساس کار میکند.
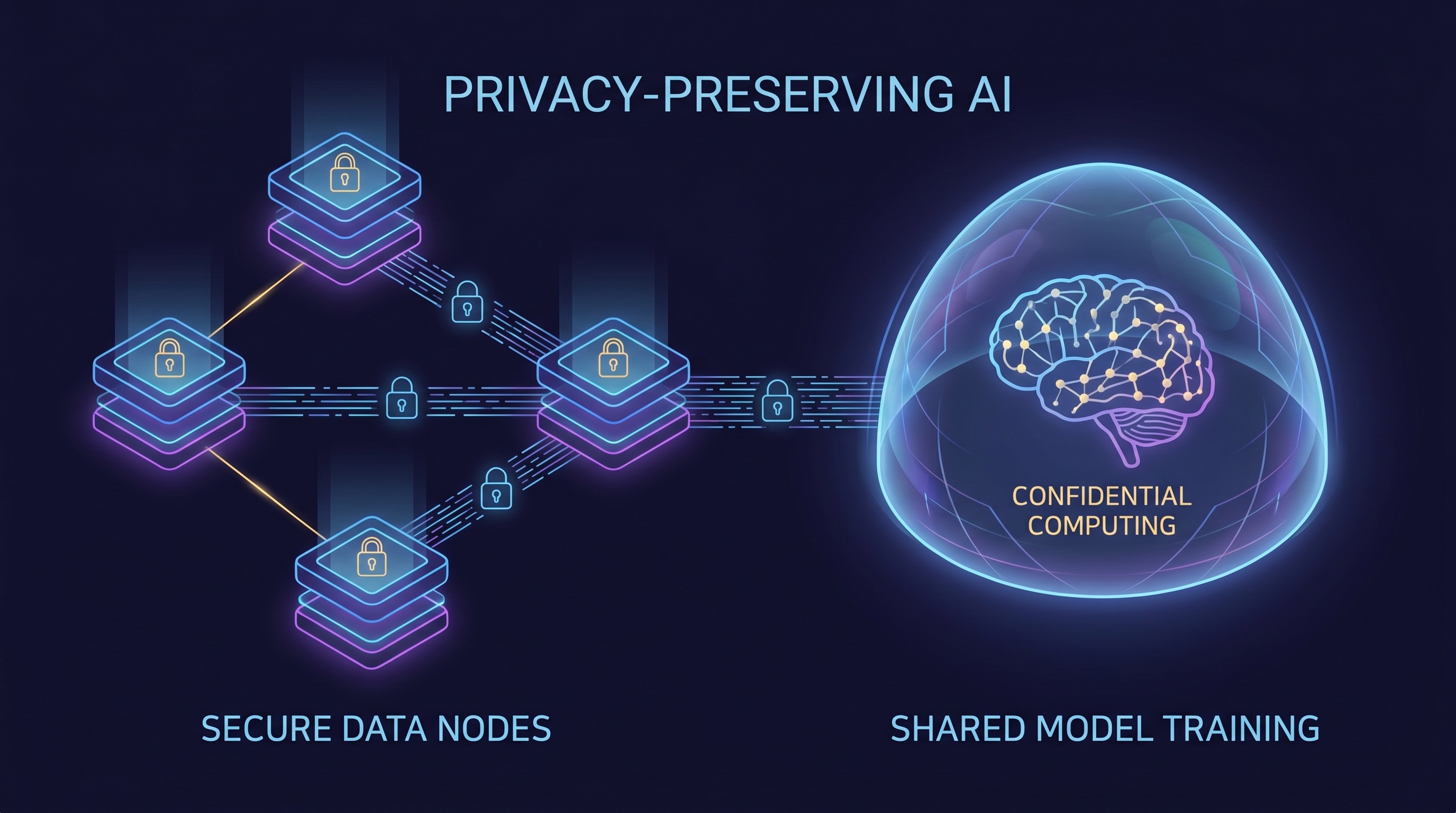
یادگیری فدرال: آوردن مدل به داده
یکی از برجستهترین ستونهای PPAI، یادگیری فدرال (FL) است. همانطور که گوگل کلود به درستی توضیح میدهد، FL مدل سنتی را وارونه میکند: به جای متمرکز کردن دادههای خام، مدل را به دادهها میفرستید. در یک تنظیم یادگیری فدرال، صاحبان دادههای فردی (مانند بیمارستانها، بانکها، دستگاههای تلفن همراه) یک مدل هوش مصنوعی محلی را بر روی مجموعههای داده خود آموزش میدهند. فقط بهروزرسانیهای این مدلهای محلی – نه خود دادههای خام – سپس برای تجمیع به یک سرور مرکزی ارسال میشوند. این بهروزرسانی مدل تجمیعشده سپس به شرکتکنندگان محلی توزیع میشود و مدلهای آنها را بدون افشای دادههای حساس زیربنایی بهبود میبخشد.
این معماری به ویژه برای بخشهای تحت نظارت انقلابی است. BizTech و IDC، در چارچوب آوریل 2026 خود، یادگیری فدرال را به عنوان یک معماری سازمانی رو به رشد، به ویژه برای مراقبتهای بهداشتی و مالی برجسته میکنند. تصور کنید چندین بیمارستان برای آموزش یک هوش مصنوعی تشخیصی دقیقتر بدون به اشتراک گذاشتن سوابق بیمار با یکدیگر همکاری میکنند. یا بانکها الگوهای پیچیده کلاهبرداری را در سراسر موسسات بدون جمعآوری تاریخچه تراکنشهای مشتری شناسایی میکنند. FL این همکاریهای قدرتمند را امکانپذیر میسازد و بینشهایی را از دادههای قبلاً جدا شده و غیرقابل دسترس، با حفظ حریم خصوصی و انطباق دقیق، باز میکند.
محاسبات محرمانه: حفاظت از دادهها در حال استفاده
در حالی که یادگیری فدرال به حریم خصوصی دادهها در حالت سکون و در حال انتقال (با عدم جابجایی دادههای خام) میپردازد، ذاتاً از دادهها در حال استفاده – یعنی در حین پردازش توسط مدلهای محلی یا تجمیع در سرور مرکزی – محافظت نمیکند. اینجاست که محاسبات محرمانه (CC) به عنوان یک فناوری مکمل حیاتی وارد عمل میشود. محاسبات محرمانه از محیطهای اجرای قابل اعتماد مبتنی بر سختافزار (TEEs) برای ایجاد محفظههای امن استفاده میکند. در داخل این محفظهها، دادهها و کد از دسترسی غیرمجاز محافظت میشوند، حتی از ارائهدهنده ابر، سیستم عامل یا سایر برنامههای در حال اجرا بر روی همان سختافزار.
هنگامی که با یادگیری فدرال ترکیب میشود، محاسبات محرمانه یک راهحل حریم خصوصی سرتاسری ارائه میدهد. FL تضمین میکند که دادههای خام هرگز منبع خود را ترک نمیکنند، و CC تضمین میکند که حتی بهروزرسانیهای مدل و فرآیندهای تجمیع در یک محیط امن و قابل تأیید اتفاق میافتند. این حفاظت دو لایه به طور قابل توجهی خطر افشای دادهها را در هر مرحله از چرخه عمر هوش مصنوعی کاهش میدهد و چارچوبی قوی برای شرکتها برای مدیریت حساسترین اطلاعاتشان ارائه میدهد.
فراتر از کلمات کلیدی: PPAI به عنوان یک ضرورت معماری
پایاننامه اصلی روشن است: هوش مصنوعی حفظکننده حریم خصوصی دیگر یک نوآوری تحقیقاتی یا یک راهحل خاص نیست؛ بلکه به سرعت در حال تبدیل شدن به یک ضرورت معماری برای شرکتها است. این حرکت ناشی از تمایل اساسی برای استفاده از پتانسیل کامل هوش مصنوعی و همکاری مؤثر، بدون خطرات ذاتی مرتبط با متمرکز کردن همه چیز در یک مجموعه داده عظیم و آسیبپذیر است. این نشاندهنده تغییر از ذهنیت "همه چیز را جمعآوری کن، سپس آن را ایمن کن" به رویکرد "امنیت از طریق طراحی، توزیع پیشفرض" است.
این تغییر معماری توسط چندین عامل هدایت میشود:
- فشار نظارتی: چشمانداز نظارتی جهانی فقط سختتر میشود و PPAI را به یک استراتژی انطباق پیشگیرانه تبدیل میکند.
- مزیت رقابتی: سازمانهایی که میتوانند به طور ایمن همکاری کنند و بینشهایی را از دادههای حساس استخراج کنند، مزیت قابل توجهی به دست میآورند.
- مسئولیت اخلاقی: ایجاد اعتماد با مشتریان و شرکا مستلزم تعهد قابل اثبات به حریم خصوصی دادهها است.
- دسترسی به دادهها: PPAI دادههایی را که در غیر این صورت برای آموزش هوش مصنوعی بسیار حساس یا از نظر قانونی محدود بودند، باز میکند.
مزایا و معایب
پذیرش PPAI به عنوان زیرساخت داده سازمانی مزایای قانعکنندهای را ارائه میدهد:
- حریم خصوصی و امنیت پیشرفته: قرار گرفتن در معرض دادههای حساس خام را به حداقل میرساند و سطح حمله و خطر نقض را کاهش میدهد.
- انطباق با مقررات: پایبندی به قوانین پیچیده حریم خصوصی دادهها را از طریق طراحی ساده میکند.
- همکاری امن: چندین طرف را قادر میسازد تا مدلها را به طور مشترک بدون به اشتراک گذاشتن اطلاعات اختصاصی یا حساس آموزش دهند.
- دسترسی به دادههای استفاده نشده: بینشهایی را از مجموعههای دادهای که قبلاً غیرقابل دسترس، جدا شده یا بسیار تنظیم شده بودند، باز میکند.
- کاهش خطر تمرکز: از ایجاد اهداف بزرگ و جذاب برای حملات سایبری جلوگیری میکند.
با این حال، اذعان به معاوضهها و پیچیدگیها ضروری است:
- پیچیدگی پیادهسازی: استقرار و مدیریت محیطهای یادگیری فدرال و محاسبات محرمانه به تخصص تخصصی، زیرساخت قوی و ادغام دقیق با سیستمهای موجود نیاز دارد.
- ملاحظات عملکرد: در حالی که به سرعت در حال بهبود است، روشهای PPAI گاهی اوقات میتوانند سربار در زمان آموزش ایجاد کنند یا ممکن است برای دستیابی به دقت مدل قابل مقایسه با رویکردهای متمرکز، نیاز به تنظیم دقیق داشته باشند.
- چالشهای حاکمیتی: مدیریت مدلهای توزیع شده، اطمینان از کیفیت دادهها در منبع، ایجاد سیاستهای روشن استفاده از دادهها و حسابرسی بهروزرسانیهای مدل در بین چندین شرکتکننده، پیچیدگیهای حاکمیتی جدیدی را معرفی میکند.
- استانداردهای در حال تحول: اکوسیستم PPAI هنوز در حال بلوغ است، با استانداردها و بهترین شیوهها که به طور مداوم در حال تکامل هستند و سازمانها را ملزم به چابکی و آگاهی میکند.
آینده زیرساخت داده سازمانی
هوش مصنوعی حفظکننده حریم خصوصی فقط یک روند نیست؛ بلکه یک عنصر اساسی برای آینده استراتژی داده سازمانی است. این به سازمانها قدرت میدهد تا سیستمهای هوشمندتر بسازند، همکاری امن دادهها را تقویت کنند و مدلهای تجاری جدیدی را باز کنند که قبلاً به دلیل نگرانیهای حریم خصوصی غیرممکن بودند. با جاسازی PPAI در زیرساخت داده اصلی خود، شرکتها میتوانند فراتر از صرفاً واکنش به مقررات حریم خصوصی حرکت کنند و در عوض به طور فعال اعتماد ایجاد کنند، مسئولانه نوآوری کنند و حداکثر ارزش را از حساسترین داراییهای خود به دست آورند.
سفر از نوآوری تحقیقاتی به انتخاب زیرساخت، یک درک حیاتی را برجسته میکند: در دنیای مبتنی بر هوش مصنوعی، کاربرد داده و حریم خصوصی دادهها متقابلاً منحصر به فرد نیستند. با PPAI، آنها به طور جداییناپذیری به هم مرتبط میشوند و راه را برای آیندهای امنتر، مشارکتیتر و هوشمندتر هموار میکنند.