فناوریهای افزایشدهنده حریم خصوصی: از نظریه انطباق تا زیرساخت داده
چشمانداز حریم خصوصی دادهها در حال تحولی عمیق است، از یک تمرین نظری انطباق به یک الزام معماری بنیادی تغییر میکند. سالها، فناوریهای افزایشدهنده حریم خصوصی (PETs) عمدتاً در محافل حقوقی و آکادمیک مورد بحث قرار میگرفتند و به عنوان مفاهیم پیشرفته برای کاربردهای خاص دیده میشدند. با این حال، یک نقطه عطف حیاتی فرا رسیده است: سیستمهای حفظ حریم خصوصی اکنون به سرعت در حال تبدیل شدن به زیرساخت اصلی دادهها هستند زیرا متمرکز کردن دادههای خام و حساس بیش از حد پرخطر، بیش از حد تحت نظارت و از نظر عملیاتی بیش از حد شکننده شده است. این تکامل تنها به معنای پایبندی به مقررات سختگیرانهتر مانند GDPR یا CCPA نیست؛ بلکه به معنای امکانپذیر ساختن ادامه کارایی دادهها و نوآوری در محیطی است که نقض دادهها پرهزینه است، اعتماد عمومی شکننده است و شبکه نظارتی دائماً در حال گسترش است.
مدل سنتی جمعآوری مجموعههای داده بزرگ در دریاچههای داده مرکزی برای تحلیل، یادگیری ماشین (Machine Learning) و هوش تجاری به طور فزایندهای غیرقابل دفاع است. حجم بالای اطلاعات حساس یک هدف غیرقابل مقاومت برای عاملان مخرب و یک مسئولیت قابل توجه برای سازمانها ایجاد میکند. در نتیجه، تمرکز از صرفاً ایمنسازی دادهها در حالت سکون (at rest) و در حال انتقال (in transit) به ایمنسازی دادهها در حال استفاده و امکان تحلیل مشارکتی بدون افشای مستقیم دادهها تغییر کرده است. این تغییر پارادایم، پذیرش PETs را نه به عنوان یک لایه امنیتی اختیاری، بلکه به عنوان اجزای جداییناپذیر خطوط لوله داده مدرن و چارچوبهای حاکمیتی الزامی میکند و به سازمانها اجازه میدهد تا از اطلاعات حساس بینش کسب کنند و مدل بسازند، در حالی که حداقل افشاگری و حداکثر تضمینهای حریم خصوصی را فراهم میکنند.
ضرورت عملیاتی: چرا PETs اکنون زیرساخت اصلی هستند
حرکت به سمت PETs به عنوان زیرساخت اصلی توسط چندین عامل همگرا هدایت میشود. اولاً، هزینه فزاینده نقض دادهها، هم مالی و هم اعتباری، یک رویکرد پیشگیرانه در حفاظت از دادهها را الزامی میکند. ثانیاً، مجموعه قوانین پراکنده حاکمیت دادهها و مقررات حریم خصوصی جهانی، اشتراکگذاری و پردازش دادهها بین مرزها را به شدت پیچیده میکند. سازمانها با یک دوراهی روبرو هستند: از دادهها برای مزیت رقابتی استفاده کنند یا خطر عدم انطباق و آسیب به اعتبار را بپذیرند. PETs یک مسیر سوم حیاتی را ارائه میدهند که امکان استفاده از دادهها را بدون به خطر انداختن حریم خصوصی یا نقض الزامات قضایی فراهم میکند. ثالثاً، ظهور مدلهای هوش مصنوعی (AI) و یادگیری ماشین (ML) که اغلب به مقادیر زیادی از دادههای متنوع نیاز دارند، روشهای جدیدی برای دسترسی و پردازش اطلاعات حساس بدون ایجاد آسیبپذیریهای جدید حریم خصوصی را ضروری میسازد. PETs ابزارهای فنی را برای آموزش مدلها بر روی مجموعههای داده توزیعشده و حساس بدون افشای دادههای خام زیربنایی فراهم میکنند.
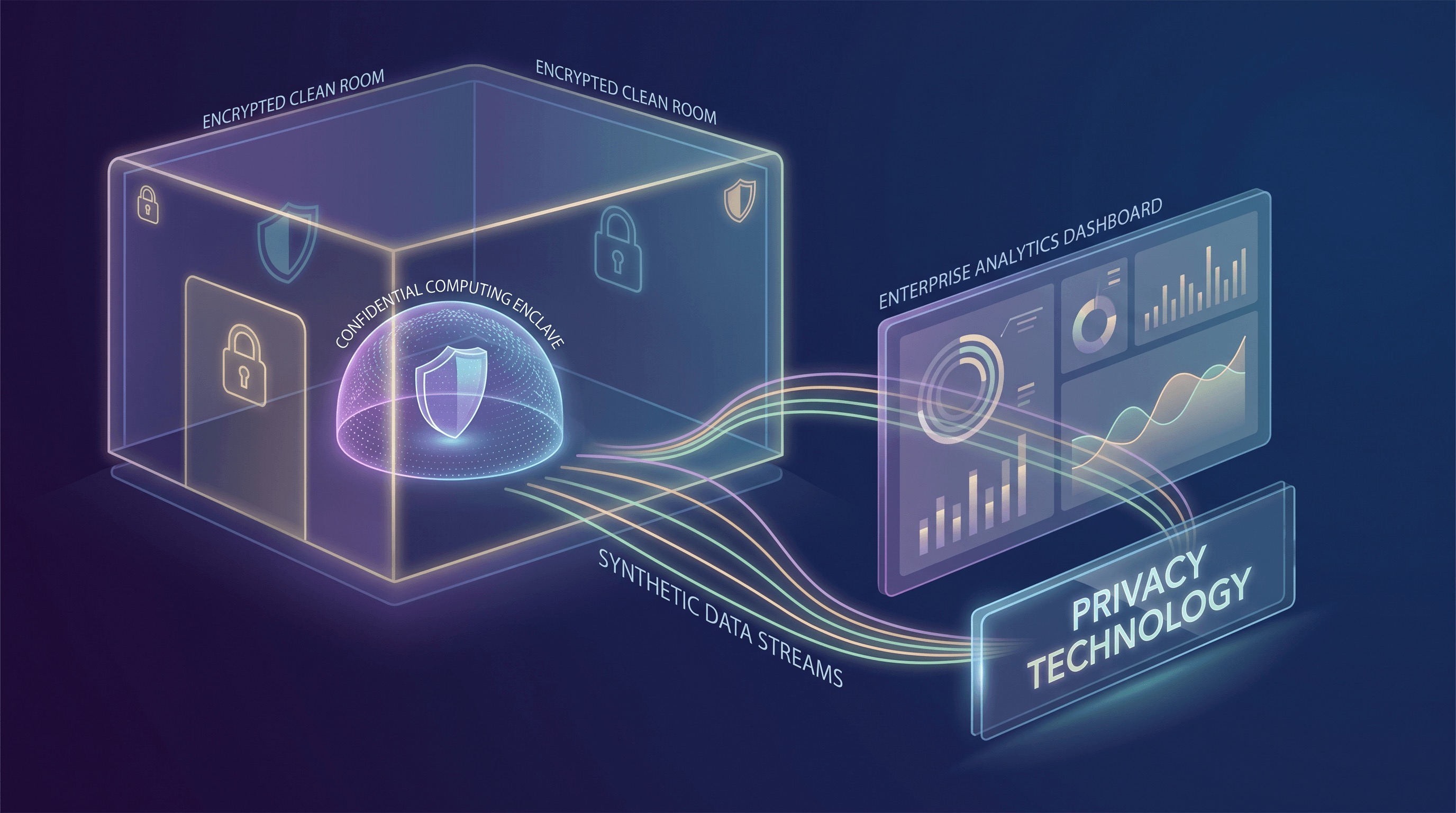
Confidential Computing: ایمنسازی دادهها در حال استفاده
یکی از مهمترین پیشرفتها در PETs، Confidential Computing است. به طور سنتی، امنیت دادهها بر رمزنگاری در حالت سکون (ذخیرهسازی) و در حال انتقال (شبکه) متمرکز بود. Confidential Computing این سهگانه را با حفاظت از دادهها در حال استفاده – در حالی که توسط CPU و حافظه پردازش میشوند – تکمیل میکند. این امر از طریق Trusted Execution Environments (TEEs) مبتنی بر سختافزار، که اغلب به عنوان Enclaves شناخته میشوند، محقق میشود. این TEEها یک محیط امن و ایزوله در داخل CPU ایجاد میکنند که در آن دادهها و کد میتوانند با تضمینهای قوی یکپارچگی و محرمانگی پردازش شوند، حتی از ارائهدهنده ابر یا سایر نرمافزارهای دارای امتیاز در همان دستگاه.
برای مثال، Google Cloud، Confidential Computing را به عنوان فناوری تعریف میکند که دادهها را در حافظه و در طول محاسبات رمزنگاری میکند و تضمین میکند که دادهها برای زیرساختهای زیرین، از جمله اپراتور ابر، غیرقابل دسترس باقی میمانند. این قابلیت تحولآفرین است. به این معنی که محاسبات حساس، مانند پردازش اطلاعات شناسایی شخصی (PII) یا الگوریتمهای اختصاصی، میتوانند در ابر با سطوح بیسابقهای از اطمینان انجام شوند. حرکت بازار حول Confidential Computing قوی است، با ارائههایی که اکنون شامل Confidential VMs، Confidential Spaces برای بارهای کاری کانتینری، خدمات گواهی سختافزاری و راهحلهای تخصصی برای موارد استفاده Analytics و AI/ML میشود. این پذیرش گسترده نشاندهنده انتقال آن از یک مفهوم امنیتی خاص به یک پریمیتو زیرساخت ابری قابل استفاده و مقیاسپذیر است که سناریوهایی را امکانپذیر میسازد که قبلاً برای محیطهای ابر عمومی بیش از حد پرخطر تلقی میشدند.
Data Clean Rooms: تحلیل مشارکتی با حریم خصوصی
یکی دیگر از PETهای قدرتمند که در حال گسترش است، Data Clean Room است. Clean Rooms یک محیط امن و کنترلشده را فراهم میکنند که در آن چندین طرف میتوانند بر روی تحلیل مجموعههای داده حساس و اغلب همپوشان، بدون افشای مستقیم دادههای خام خود به یکدیگر، همکاری کنند. این امر به ویژه برای اندازهگیری تبلیغات، تشخیص تقلب و بهینهسازی زنجیره تامین ارزشمند است، جایی که بینشها نیاز به ترکیب دادهها از سازمانهای مختلف دارند. اصل اصلی این است که فقط بینشهای جمعآوریشده و حفظکننده حریم خصوصی به اشتراک گذاشته میشوند، نه هرگز دادههای خام در سطح فردی.
AWS Clean Rooms این روند را به خوبی نشان میدهد و سرویسی را ارائه میدهد که به مشتریان امکان میدهد تا مجموعههای داده ترکیبی خود را به طور ایمن تحلیل کرده و در مورد آنها همکاری کنند، بدون اشتراکگذاری یا افشای دادههای زیربنایی. یک ویژگی قابل توجه، معرفی تولید مجموعه دادههای مصنوعی (Synthetic Dataset Generation) افزایشدهنده حریم خصوصی برای آموزش ML در داخل این Clean Rooms است. این قابلیت حیاتی است: به سازمانها اجازه میدهد تا نسخههای مصنوعی از دادههای حساس خود را که از نظر آماری نماینده هستند، ایجاد کنند. این مجموعههای داده مصنوعی الگوها و روابط آماری ضروری موجود در دادههای اصلی را حفظ میکنند و آنها را برای آموزش مدلهای ML مناسب میسازند، در حالی که خطر شناسایی مجدد (re-identification) و استنتاج عضویت (membership inference) را به طور قابل توجهی کاهش میدهند. AWS معیارهای وفاداری و حریم خصوصی را برای کمک به کاربران در درک مبادلات و اطمینان از اینکه دادههای مصنوعی نیازهای کارایی و حریم خصوصی آنها را برآورده میکنند، ارائه میدهد. این نوآوری مستقیماً به چالش ساخت مدلهای قدرتمند AI که به دادههای گسترده نیاز دارند، بدون تحمل کامل مسئولیتهای حریم خصوصی ناشی از اشتراکگذاری یا متمرکز کردن PII خام، میپردازد.
Synthetic Data: یک ابزار حریم خصوصی چندمنظوره
فراتر از کاربرد آن در Clean Rooms، Synthetic Data به عنوان یک فناوری افزایشدهنده حریم خصوصی مستقل و چندمنظوره در حال ظهور است. دادههای تولیدشدهای که از نظر آماری دادههای واقعی را تقلید میکنند اما حاوی هیچ رکورد فردی واقعی نیستند، یک راهحل قدرتمند برای توسعه، آزمایش و حتی برخی وظایف تحلیلی ارائه میدهند. توانایی تولید مجموعههای داده مصنوعی با وفاداری بالا به توسعهدهندگان اجازه میدهد تا برنامهها را با استفاده از دادههای واقعی بدون دست زدن به PII تولیدی، بسازند و آزمایش کنند. این امر چرخههای توسعه را تسریع میکند، سربار انطباق را کاهش میدهد و سطح حمله مرتبط با رسیدگی به اطلاعات حساس در محیطهای غیرتولیدی را به حداقل میرساند.
پیچیدگی تولید Synthetic Data به طور قابل توجهی پیشرفت کرده است و از مدلهای Generative AI برای ثبت همبستگیها و توزیعهای پیچیده موجود در دادههای اصلی استفاده میکند. این امر تضمین میکند که مدلهای آموزشدیده بر روی دادههای مصنوعی عملکردی مشابه با مدلهای آموزشدیده بر روی دادههای واقعی دارند و آن را به یک جایگزین قابل قبول برای بسیاری از گردشهای کاری ML تبدیل میکند. نکته کلیدی، تعادل بین کارایی و حریم خصوصی است، اطمینان از اینکه دادههای مصنوعی برای هدف مورد نظر به اندازه کافی مفید هستند، در حالی که تضمینهای قوی در برابر شناسایی مجدد را فراهم میکنند.
Federated Analysis: یادگیری بدون تمرکز
Federated Analysis، از جمله کاربرد خاصتر آن در Federated Learning، یکی دیگر از PETهای حیاتی برای محیطهای داده توزیعشده است. به جای متمرکز کردن دادههای خام از چندین منبع (مثلاً دستگاههای مختلف، سازمانها یا مناطق جغرافیایی) در یک مکان برای تحلیل یا آموزش مدل، روشهای فدرال محاسبات را به سمت دادهها میآورند. به عنوان مثال، در Federated Learning، یک مدل جهانی با ارسال پارامترهای مدل به دستگاههای محلی یا سیلوهای داده آموزش داده میشود. هر نهاد محلی مدل را بر روی دادههای خصوصی خود آموزش میدهد و تنها پارامترهای مدل بهروز شده (یا گرادیانها) به یک سرور مرکزی بازگردانده میشوند، جایی که برای بهبود مدل جهانی جمعآوری میشوند. دادههای خام هرگز مکان اصلی خود را ترک نمیکنند.
این رویکرد به ویژه برای سناریوهایی که شامل دادههای بسیار حساس توزیعشده در بسیاری از نقاط پایانی هستند، مانند سوابق پزشکی در بیمارستانهای مختلف یا دادههای کاربر در دستگاههای تلفن همراه فردی، ارزشمند است. این امکان را برای تحلیل مشارکتی و آموزش مدل در سراسر مجموعههای داده متنوع بدون چالشهای عظیم حریم خصوصی و لجستیکی جمعآوری دادههای خام فراهم میکند. Federated Analysis ذاتاً از حاکمیت دادهها پشتیبانی میکند و خطر نقض دادهها در مقیاس بزرگ را به حداقل میرساند، زیرا هیچ نهاد واحدی هرگز تمام اطلاعات خام را در اختیار ندارد.
PETs به عنوان پایه و اساس جدید معماری داده
ادغام این فناوریهای افزایشدهنده حریم خصوصی نشاندهنده یک تغییر اساسی در رویکرد سازمانها به حاکمیت و استفاده از دادهها است. آنها دیگر صرفاً ویژگیهای امنیتی "خوب است که داشته باشیم" یا کنجکاویهای آکادمیک پیچیده نیستند. در عوض، PETs در حال تبدیل شدن به معماری فنی هستند که شرکتها را قادر میسازد تا به طور مؤثر از دادههای حساس تحت انتظارات فزاینده سختگیرانه حریم خصوصی، حاکمیت دادهها و AI governance استفاده کنند. این بدان معناست که معماران داده، مهندسان و مسئولان حریم خصوصی باید به طور فزایندهای راهحلهایی مانند Confidential Computing، Data Clean Rooms، تولید Synthetic Data و Federated Analysis را به عنوان اجزای استاندارد زیرساخت دادههای خود درک و پیادهسازی کنند.
آینده نوآوری مبتنی بر داده به توانایی استخراج ارزش از اطلاعات حساس به طور مسئولانه بستگی دارد. PETs پل حیاتی بین کارایی دادهها و حفاظت از حریم خصوصی را فراهم میکنند. همانطور که این فناوریها بالغ میشوند و از طریق ارائههای ارائهدهندگان ابر و ابتکارات منبع باز (open-source) قابل دسترستر میشوند، پذیرش آنها سرعت خواهد گرفت و اساساً نحوه جمعآوری، پردازش، اشتراکگذاری و تحلیل دادهها را در صنایع مختلف تغییر خواهد داد. دوران متمرکز کردن دادههای خام بدون عواقب در حال پایان است؛ دوران زیرساخت داده هوشمند و حفظکننده حریم خصوصی تازه آغاز شده است.