خزنده های هوش مصنوعی وب سایت های باز را به اهداف زیرساختی تبدیل می کنند
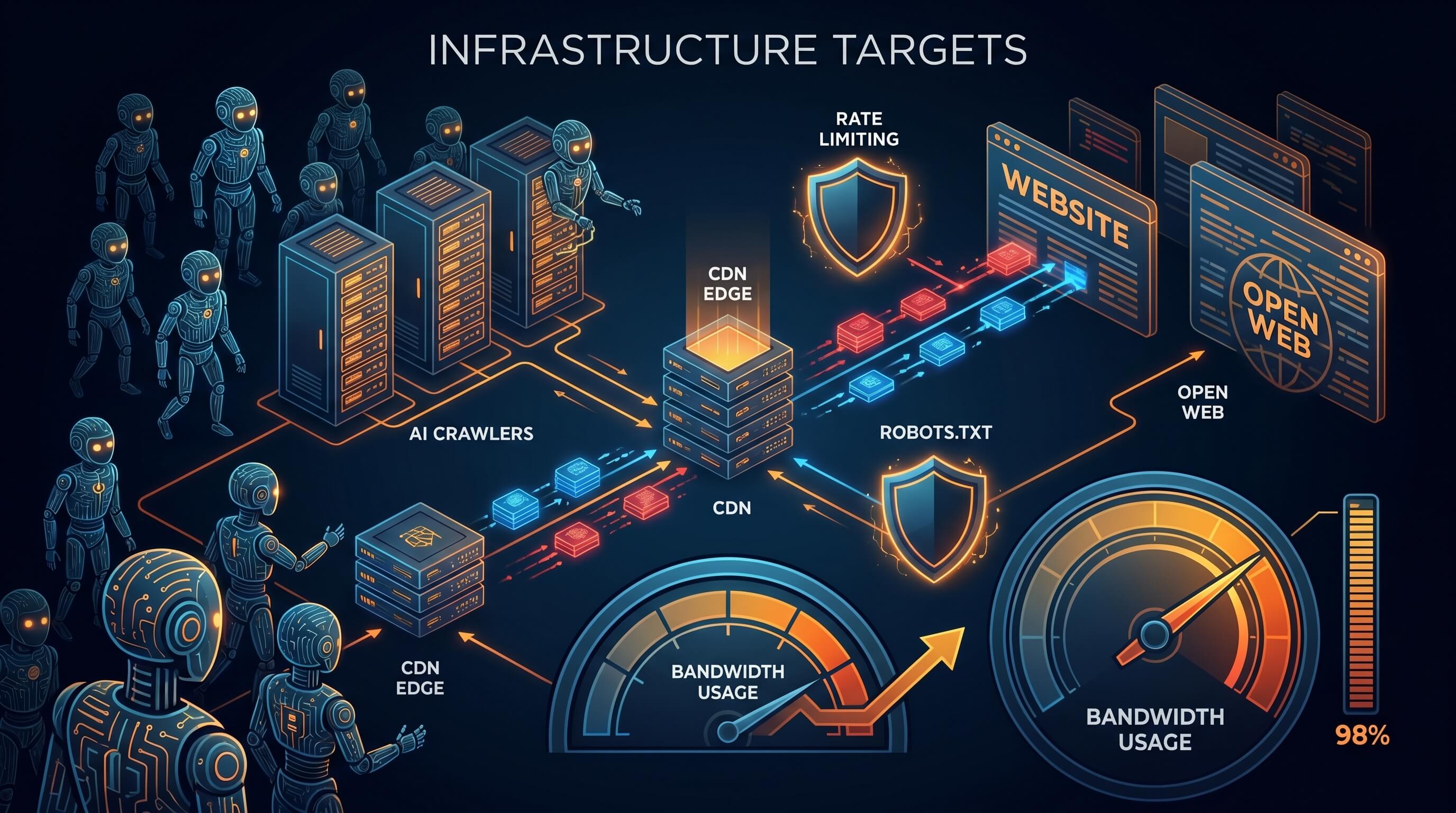
وب سایت های باز در گذشته بیشتر برای مخاطبان انسانی و ایندکس شدن توسط موتورهای جستجو طراحی می شدند. امروز خزنده های هوش مصنوعی با مقیاسی ماشینی همان سایت ها را هدف می گیرند و اغلب بدون بازگرداندن ترافیک انسانی متناسب، هزینه زیرساخت را بالا می برند.
در عمل، این یعنی بسیاری از وب سایت ها دیگر فقط رسانه یا مرجع عمومی نیستند، بلکه مانند اهداف زیرساختی با آن ها رفتار می شود. هزینه پهنای باند و CDN بالا می رود، نیاز به محدودسازی نرخ بیشتر می شود و robots.txt دیگر مانند گذشته یک ابزار مؤثر به نظر نمی رسد.
چرا ترافیک خزنده های هوش مصنوعی با خزیدن سنتی فرق دارد
در مدل قدیمی، ایندکس شدن هزینه داشت اما در ازای آن بازدید و کشف محتوا هم ایجاد می شد. اکنون بسیاری از خزنده های هوش مصنوعی برای آموزش مدل، بازیابی محتوا یا ساخت پاسخ های خلاصه به سراغ سایت ها می آیند، بی آنکه ارجاع معناداری برگردانند.
این وضعیت رابطه ارزش را مبهم می کند. صاحب سایت اغلب نمی داند کدام خزنده برای آموزش مدل آمده، کدام برای retrieval، کدام robots.txt را رعایت می کند و کدام هویت خود را پنهان می کند.
هزینه CDN به مسئله ای محتوایی تبدیل می شود
وقتی ترافیک بات ها بالا می رود، هزینه زیرساخت دیگر فقط یک موضوع فنی یا مالی نیست. این هزینه می تواند بر تصمیم های انتشار محتوا اثر بگذارد. یک وبلاگ تخصصی، انجمن کوچک یا پایگاه دانش عمومی ممکن است مخاطب انسانی محدودی داشته باشد، اما برای خزنده ها سطح حمله بزرگی بسازد.
در چنین شرایطی، یک سایت بدون آنکه برای مخاطبانش مفیدتر شده باشد، فقط گران تر اداره می شود. همین فشار می تواند سایت ها را به سمت دیوار ورود، چالش های امنیتی، یا محدودیت های شدیدتر سوق دهد.
قرارداد اجتماعی قدیمی robots.txt در حال فرسایش است
robots.txt همیشه داوطلبانه بود، نه یک مرز امنیتی واقعی. اما چون خزنده های بزرگ انگیزه رعایت داشتند، این سازوکار تا حدی خوب کار می کرد. امروز این فرض در حال ضعیف شدن است.
در محیط جدید، برخی عامل ها ممکن است robots.txt را نادیده بگیرند، با شناسه های تازه برگردند یا برداشت محدودی از آن داشته باشند. حتی رعایت آن هم الزاماً به معنی جبران اقتصادی یا ارجاع واقعی نیست.
محدودسازی نرخ به وضعیت پیش فرض تبدیل می شود
بسیاری از سایت ها قبلاً rate limiting را فقط برای حملات یا حفاظت از ورود کاربران به کار می بردند. حالا این کار به یک کنترل پایه برای انتشار عمومی تبدیل شده است. مسیرهای عمومی بیشتر محدود می شوند، امتیازدهی بات ها جدی تر می شود و ترافیک مشکوک پیش از رسیدن به origin متوقف می شود.
البته این رویکرد هزینه دارد. محدودیت شدید می تواند به ابزارهای مفید، پژوهشگران، دسترس پذیری و حتی موتورهای جستجوی قانونی هم آسیب بزند. بنابراین مسئله فقط مسدودسازی نیست، بلکه قابل پیش بینی کردن هزینه crawling است.
مسئله اصلی، عدم تقارن اقتصادی است
شرکت های بزرگ هوش مصنوعی می توانند هزینه خزیدن را روی پلتفرم های عظیم خود پخش کنند و آن را ورودی استراتژیک بدانند. اما یک ناشر کوچک نمی تواند هزینه دفاع را به همان شکل توزیع کند. هر ترابایت اضافه، هر چرخه تنظیم WAF و هر ساعت مهندسی مستقیماً بر دوش اپراتور سایت می افتد.
به همین دلیل، وب باز در خطر تبدیل شدن به لایه یارانه ای برای سامانه های هوش مصنوعی است. محتوا عمومی می ماند، اما هزینه عمومی ماندن آن را ناشر می پردازد و بخش بیشتری از ارزش نهایی جای دیگری جمع می شود.
اقدام های عملی برای اپراتورهای وب
هزینه بات ها را جداگانه اندازه بگیرید
پهنای باند، نرخ درخواست، cache miss و فشار بر origin را تا حد ممکن بر اساس نوع بات تفکیک کنید.
سطح خزیدن پرهزینه را کاهش دهید
آرشیوها، صفحه بندی ها، جستجوی داخلی، URLهای تکراری و مسیرهای کم ارزش را بازبینی کنید.
دفاع را به لبه شبکه منتقل کنید
از CDN و WAF برای متوقف کردن ترافیک تکراری پیش از رسیدن به سرور اصلی استفاده کنید.
سطوح دسترسی روشن تعریف کنید
به جای دوگانه باز یا بسته، برای دسترسی حجیم یا پرتکرار از کلید API، سهمیه یا شرایط تجاری استفاده کنید.
سیاست خزیدن را مستند کنید
در کنار robots.txt یک سیاست روشن برای crawling و licensing منتشر کنید تا مبنای بهتری برای اجرا و مذاکره داشته باشید.
وب باز اکنون به دفاع اقتصادی نیاز دارد
خزنده های هوش مصنوعی یک مزاحمت موقت نیستند. آن ها مدل هزینه انتشار عمومی را تغییر می دهند. نتیجه عملی این است که صاحبان سایت باید بار بات ها را دقیق اندازه بگیرند، سطح حمله را کوچک کنند، محدودسازی نرخ را در لبه اجرا کنند و دسترسی حجیم را به شروط مشخص گره بزنند.
دوران بعدی وب فقط با آنچه منتشر می شود تعریف نخواهد شد، بلکه با این هم تعریف می شود که چه کسی توان مالی باز ماندن را دارد.