Las Tecnologías de Mejora de la Privacidad Pasan de la Teoría de Cumplimiento a la Infraestructura de Datos
El panorama de la privacidad de los datos está experimentando una profunda transformación, pasando de un ejercicio de cumplimiento teórico a un imperativo arquitectónico fundamental. Durante años, las Tecnologías de Mejora de la Privacidad (PETs) se discutieron en gran medida en círculos legales y académicos, vistas como conceptos avanzados para aplicaciones de nicho. Sin embargo, ha llegado un punto de inflexión crítico: los sistemas de preservación de la privacidad se están convirtiendo rápidamente en infraestructura de datos principal porque centralizar datos crudos y sensibles se está volviendo demasiado arriesgado, demasiado regulado y demasiado frágil operativamente. Esta evolución no se trata meramente de adherirse a regulaciones más estrictas como GDPR o CCPA; se trata de habilitar la utilidad continua de los datos y la innovación en un entorno donde las filtraciones de datos son costosas, la confianza pública es frágil y la red regulatoria se está expandiendo constantemente.
El modelo tradicional de agregar vastos conjuntos de datos en lagos de datos centrales para análisis, Machine Learning e inteligencia empresarial es cada vez más insostenible. El gran volumen de información sensible crea un objetivo irresistible para los actores maliciosos y una responsabilidad significativa para las organizaciones. En consecuencia, el enfoque ha cambiado de simplemente asegurar los datos en reposo (at rest) y en tránsito (in transit) a asegurar los datos en uso y habilitar el análisis colaborativo sin exposición directa de los datos. Este cambio de paradigma exige la adopción de PETs no como una capa de seguridad opcional, sino como componentes integrales de las tuberías de datos modernas y los marcos de gobernanza, permitiendo a las organizaciones obtener información y construir modelos a partir de información sensible, minimizando la exposición y maximizando las garantías de privacidad.
El Imperativo Operacional: Por qué las PETs son Ahora Infraestructura Central
El movimiento hacia las PETs como infraestructura central está impulsado por varios factores convergentes. En primer lugar, el costo creciente de las filtraciones de datos, tanto financieras como reputacionales, obliga a una postura proactiva en la protección de datos. En segundo lugar, el mosaico de leyes globales de soberanía de datos y regulaciones de privacidad hace que el intercambio y procesamiento de datos transfronterizos sea increíblemente complejo. Las organizaciones se enfrentan a un dilema: aprovechar los datos para obtener una ventaja competitiva o arriesgarse al incumplimiento y al daño reputacional. Las PETs ofrecen un tercer camino crucial, permitiendo la utilidad de los datos sin comprometer la privacidad o violar los mandatos jurisdiccionales. En tercer lugar, el auge de los modelos de AI y Machine Learning (ML), que a menudo requieren grandes cantidades de datos diversos, necesita nuevas formas de acceder y procesar información sensible sin crear nuevas vulnerabilidades de privacidad. Las PETs proporcionan los medios técnicos para entrenar modelos en conjuntos de datos distribuidos y sensibles sin exponer nunca los datos crudos subyacentes.
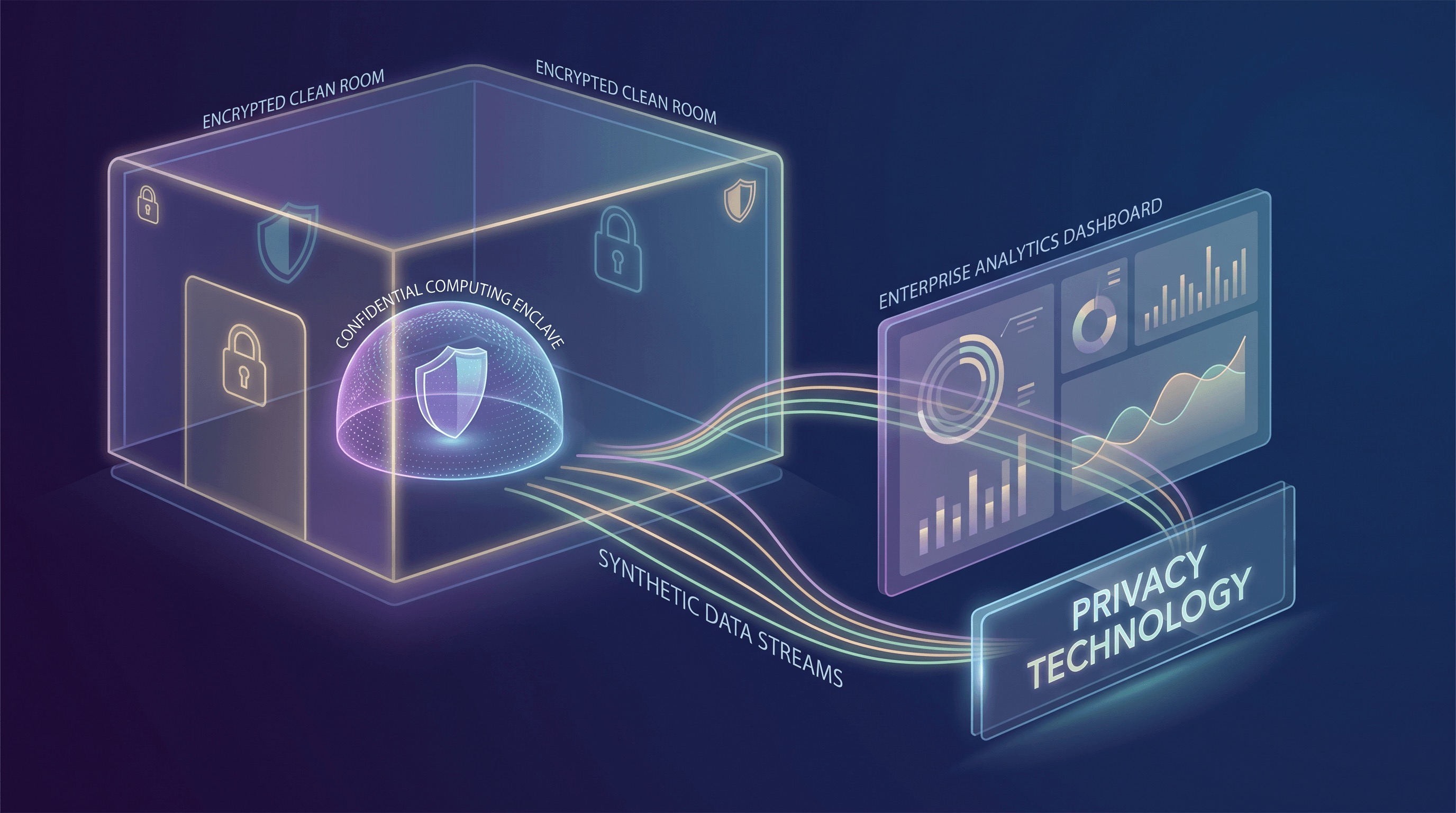
Confidential Computing: Asegurando Datos en Uso
Uno de los avances más significativos en las PETs es Confidential Computing. Tradicionalmente, la seguridad de los datos se centraba en el cifrado en reposo (almacenamiento) y en tránsito (red). Confidential Computing completa esta tríada al proteger los datos en uso, mientras son procesados por la CPU y la memoria. Esto se logra a través de Trusted Execution Environments (TEEs) basados en hardware, a menudo denominados enclaves. Estos TEEs crean un entorno seguro y aislado dentro de una CPU donde los datos y el código pueden procesarse con fuertes garantías de integridad y confidencialidad, incluso del proveedor de la nube u otro software privilegiado en la misma máquina.
Google Cloud, por ejemplo, define Confidential Computing como una tecnología que cifra los datos en la memoria y durante la computación, asegurando que los datos permanezcan inaccesibles para la infraestructura subyacente, incluido el operador de la nube. Esta capacidad es transformadora. Significa que las computaciones sensibles, como el procesamiento de información de identificación personal (PII) o algoritmos propietarios, pueden realizarse en la nube con niveles de seguridad sin precedentes. El movimiento del mercado alrededor de Confidential Computing es robusto, con ofertas que ahora abarcan Confidential VMs, Confidential Spaces para cargas de trabajo en contenedores, servicios de atestación de hardware y soluciones especializadas para casos de uso de Analytics y AI/ML. Esta amplia adopción significa su transición de un concepto de seguridad de nicho a una primitiva de infraestructura en la nube utilizable y escalable, que permite escenarios previamente considerados demasiado arriesgados para entornos de nube pública.
Data Clean Rooms: Análisis Colaborativo con Privacidad
Otra PET poderosa que está ganando terreno es la Data Clean Room. Las Clean Rooms proporcionan un entorno seguro y controlado donde múltiples partes pueden colaborar en el análisis de conjuntos de datos sensibles, a menudo superpuestos, sin exponer directamente sus datos crudos entre sí. Esto es particularmente valioso para la medición de publicidad, la detección de fraudes y la optimización de la cadena de suministro, donde las ideas requieren combinar datos de diferentes organizaciones. El principio central es que solo se comparten ideas agregadas que preservan la privacidad, nunca los datos crudos a nivel individual.
AWS Clean Rooms ejemplifica esta tendencia, ofreciendo un servicio que permite a los clientes analizar y colaborar de forma segura en sus conjuntos de datos combinados sin compartir ni revelar los datos subyacentes. Una característica notable es la introducción de la generación de conjuntos de datos sintéticos (Synthetic Dataset Generation) que mejoran la privacidad para el entrenamiento de ML dentro de estas Clean Rooms. Esta capacidad es crucial: permite a las organizaciones crear versiones sintéticas estadísticamente representativas de sus datos sensibles. Estos conjuntos de datos sintéticos preservan los patrones y relaciones estadísticas esenciales que se encuentran en los datos originales, lo que los hace adecuados para entrenar modelos de ML, al tiempo que reducen significativamente el riesgo de reidentificación e inferencia de membresía. AWS proporciona métricas de fidelidad y privacidad para ayudar a los usuarios a comprender las compensaciones y garantizar que los datos sintéticos cumplan con sus requisitos de utilidad y privacidad. Esta innovación aborda directamente el desafío de construir potentes modelos de AI que requieren datos extensos sin incurrir en todas las responsabilidades de privacidad de compartir o centralizar PII cruda.
Synthetic Data: Una Herramienta de Privacidad Versátil
Más allá de su aplicación en Clean Rooms, los Synthetic Data están emergiendo como una Tecnología de Mejora de la Privacidad versátil e independiente. Los datos generados que imitan estadísticamente los datos reales pero que no contienen registros individuales reales ofrecen una solución poderosa para el desarrollo, las pruebas e incluso algunas tareas analíticas. La capacidad de generar conjuntos de datos sintéticos de alta fidelidad permite a los desarrolladores construir y probar aplicaciones utilizando datos realistas sin tocar nunca la PII de producción. Esto acelera los ciclos de desarrollo, reduce la sobrecarga de cumplimiento y minimiza la superficie de ataque asociada con el manejo de información sensible en entornos que no son de producción.
La sofisticación de la generación de Synthetic Data ha avanzado considerablemente, aprovechando los modelos de Generative AI para capturar correlaciones y distribuciones complejas presentes en los datos originales. Esto asegura que los modelos entrenados con datos sintéticos se desempeñen de manera similar a los entrenados con datos reales, lo que los convierte en una alternativa viable para muchos flujos de trabajo de ML. La clave es equilibrar la utilidad y la privacidad, asegurando que los datos sintéticos sean lo suficientemente útiles para su propósito previsto mientras brindan fuertes garantías contra la reidentificación.
Federated Analysis: Aprendizaje sin Centralización
Federated Analysis, incluida su aplicación más específica en Federated Learning, representa otra PET crítica para entornos de datos distribuidos. En lugar de centralizar datos crudos de múltiples fuentes (por ejemplo, diferentes dispositivos, organizaciones o regiones geográficas) en una ubicación para análisis o entrenamiento de modelos, los métodos federados llevan la computación a los datos. En Federated Learning, por ejemplo, un modelo global se entrena enviando los parámetros del modelo a dispositivos locales o silos de datos. Cada entidad local entrena el modelo con sus datos privados, y solo los parámetros del modelo actualizados (o gradientes) se envían de vuelta a un servidor central, donde se agregan para mejorar el modelo global. Los datos crudos nunca abandonan su ubicación original.
Este enfoque es particularmente valioso para escenarios que involucran datos altamente sensibles distribuidos en muchos puntos finales, como registros médicos en diferentes hospitales o datos de usuarios en dispositivos móviles individuales. Permite análisis colaborativos y entrenamiento de modelos en diversos conjuntos de datos sin los inmensos desafíos de privacidad y logísticos de agrupar datos crudos. Federated Analysis apoya inherentemente la soberanía de los datos y minimiza el riesgo de filtraciones de datos a gran escala, ya que ninguna entidad individual posee nunca toda la información cruda.
Las PETs como la Nueva Base de la Arquitectura de Datos
La integración de estas Tecnologías de Mejora de la Privacidad significa un cambio fundamental en cómo las organizaciones abordan la gobernanza y la utilización de los datos. Ya no son meramente características de seguridad "agradables de tener" o curiosidades académicas complejas. En cambio, las PETs se están convirtiendo en la arquitectura técnica que permite a las empresas seguir aprovechando los datos sensibles de manera efectiva bajo expectativas cada vez más estrictas de privacidad, soberanía de datos y AI governance. Esto significa que los arquitectos de datos, ingenieros y oficiales de privacidad deben comprender e implementar cada vez más soluciones como Confidential Computing, Data Clean Rooms, generación de Synthetic Data y Federated Analysis como componentes estándar de su infraestructura de datos.
El futuro de la innovación impulsada por datos depende de la capacidad de extraer valor de la información sensible de manera responsable. Las PETs proporcionan el puente crucial entre la utilidad de los datos y la protección de la privacidad. A medida que estas tecnologías maduran y se vuelven más accesibles a través de las ofertas de los proveedores de la nube y las iniciativas de código abierto (open-source), su adopción se acelerará, remodelando fundamentalmente cómo se recopilan, procesan, comparten y analizan los datos en todas las industrias. La era de centralizar datos crudos sin consecuencias está llegando a su fin; la era de la infraestructura de datos inteligente y que preserva la privacidad apenas está comenzando.