Los Rastreadores de IA Están Convirtiendo los Sitios Web Abiertos en Objetivos de Infraestructura
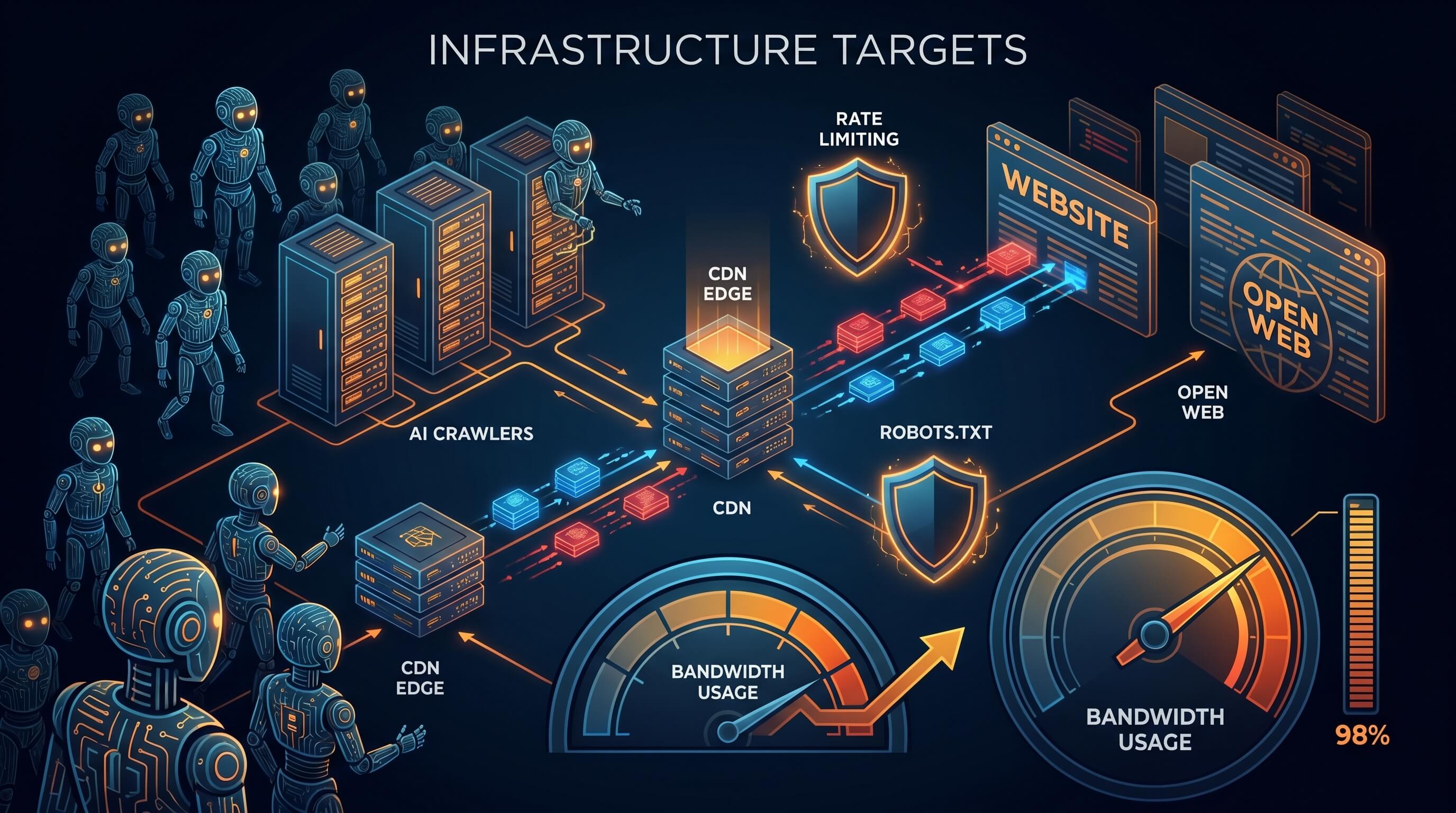
Durante años, operar un sitio público implicaba un acuerdo básico: publicabas contenido, los buscadores lo indexaban y los lectores llegaban a través de enlaces y descubrimiento. Ese modelo está cambiando. Los rastreadores de IA están visitando sitios abiertos a escala de máquina y muchas veces consumen muchos más recursos de los que devuelven en visitas humanas.
La consecuencia práctica es clara: más sitios están siendo tratados como objetivos de infraestructura en lugar de simples publicaciones. Suben las facturas de CDN, aumenta la presión sobre el servidor de origen y robots.txt empieza a parecer una sugerencia más que un control efectivo.
Por qué el rastreo de IA se siente distinto al rastreo tradicional
El rastreo clásico de buscadores nunca fue gratis, pero sí tenía una lógica comprensible. Los editores aceptaban el coste porque la indexación podía traer tráfico y audiencia. Con la IA, esa relación se debilita. Un proveedor puede rastrear para entrenamiento, recuperación o sistemas de respuesta sin enviar visitas proporcionales al sitio fuente.
Eso cambia los incentivos. Si un bot consume mucho tráfico y casi no genera referidos, se comporta más como un extractor que como un socio de descubrimiento.
La factura del CDN se convierte en un problema editorial
Cuando sube el tráfico de bots, la infraestructura deja de ser un asunto de fondo. Empieza a influir en las decisiones de publicación. Un blog especializado, una comunidad o una base de conocimiento pública puede tener poco tráfico humano pero miles de páginas atractivas para el raspado automatizado.
Así, el sitio se vuelve más caro de operar sin volverse más valioso para su propia audiencia. Eso empuja a muchos operadores a considerar muros de acceso, desafíos automáticos y políticas de bloqueo más duras.
robots.txt está perdiendo su viejo contrato social
robots.txt siempre fue voluntario, no una frontera de seguridad. Aun así funcionó durante años porque los grandes rastreadores tenían incentivos para comportarse de forma predecible. Ese supuesto se está debilitando.
Hoy muchos operadores asumen que algunos agentes ignorarán robots.txt, volverán con nuevos identificadores o cumplirán solo de forma parcial. Incluso cuando hay cumplimiento, eso no garantiza compensación ni atribución suficiente.
La limitación de tasa se vuelve postura por defecto
Muchos sitios usaban el rate limiting solo para abuso o protección de acceso. Ahora se está convirtiendo en un control básico de publicación. Se limitan endpoints públicos, se puntúan bots y se frena tráfico sospechoso antes de que llegue al origen.
Esto tiene costes y riesgos. Límites demasiado agresivos pueden afectar a automatizaciones legítimas, investigadores, accesibilidad e incluso a buscadores útiles. La meta no es bloquearlo todo, sino volver predecible el coste del rastreo.
El problema real es la asimetría
Las grandes empresas de IA pueden repartir el coste del rastreo entre plataformas enormes y tratarlo como un insumo estratégico. Un editor pequeño no puede repartir así el coste defensivo. Cada terabyte extra, cada ajuste del WAF y cada hora de ingeniería recaen directamente sobre el operador.
Por eso la web abierta corre el riesgo de convertirse en una capa subvencionada para sistemas de IA. El contenido sigue siendo público, pero el coste de mantenerlo público lo asume el editor mientras el valor aguas abajo se concentra en otros actores.
Qué deberían hacer ahora los operadores web
Medir el coste de los bots por separado
Separe ancho de banda, volumen de solicitudes, fallos de caché y carga de origen por clase de bot cuando sea posible.
Reducir superficies de rastreo costosas
Revise archivos, navegación facetada, búsquedas internas, variantes de feeds y URL duplicadas.
Llevar las protecciones al edge
Use controles de CDN y WAF para absorber tráfico repetitivo antes de que toque el servidor de origen.
Definir niveles explícitos de acceso
No todo debe ser abierto o cerrado. El acceso masivo puede requerir API keys, cuotas o condiciones comerciales.
Documentar la política
Publique una política clara de rastreo y licencias junto a robots.txt para reforzar la base de aplicación y negociación.
La web abierta ahora necesita defensas económicas
Los rastreadores de IA no son una molestia pasajera. Están cambiando el modelo de costes de la publicación pública. La conclusión práctica es actuar ya: medir la carga de bots, reducir superficies innecesarias, aplicar límites en el edge y reservar el acceso de alto volumen para términos explícitos.
La próxima etapa de la web no se definirá solo por lo que se publica, sino también por quién puede permitirse seguir abierto.