Why Privacy-Preserving AI Is Becoming Enterprise Data Infrastructure
In the rapidly evolving landscape of artificial intelligence, the promise of transformative insights often collides with the imperative of data privacy. Enterprises globally are grappling with how to harness the power of AI without compromising sensitive information, violating stringent regulations, or exposing themselves to catastrophic data breaches. For years, the dominant paradigm involved centralizing vast datasets into monolithic data lakes, a practice that, while efficient for model training, created immense risk. Today, a fundamental shift is underway: Privacy-Preserving AI (PPAI) is moving beyond academic curiosity and niche applications to become a foundational component of enterprise data infrastructure.
The Data Centralization Dilemma and the Rise of PPAI
The traditional approach to AI development relies heavily on aggregating data. Whether it's customer records, financial transactions, or medical histories, the more data an AI model has access to, the better it typically performs. However, this centralization creates a single, highly attractive target for cybercriminals and a compliance nightmare for organizations. Regulations like GDPR, HIPAA, CCPA, and countless others impose strict rules on how personal and sensitive data can be collected, stored, processed, and shared. Non-compliance carries not only hefty fines but also severe reputational damage.
This dilemma has spurred the development and adoption of PPAI technologies. PPAI encompasses a suite of methods designed to allow AI models to learn from data without directly accessing or exposing the raw, sensitive information. It's about enabling collaboration and insight generation while maintaining the highest standards of privacy and security. This isn't merely an ethical consideration; it's a strategic necessity for any enterprise operating with sensitive data.
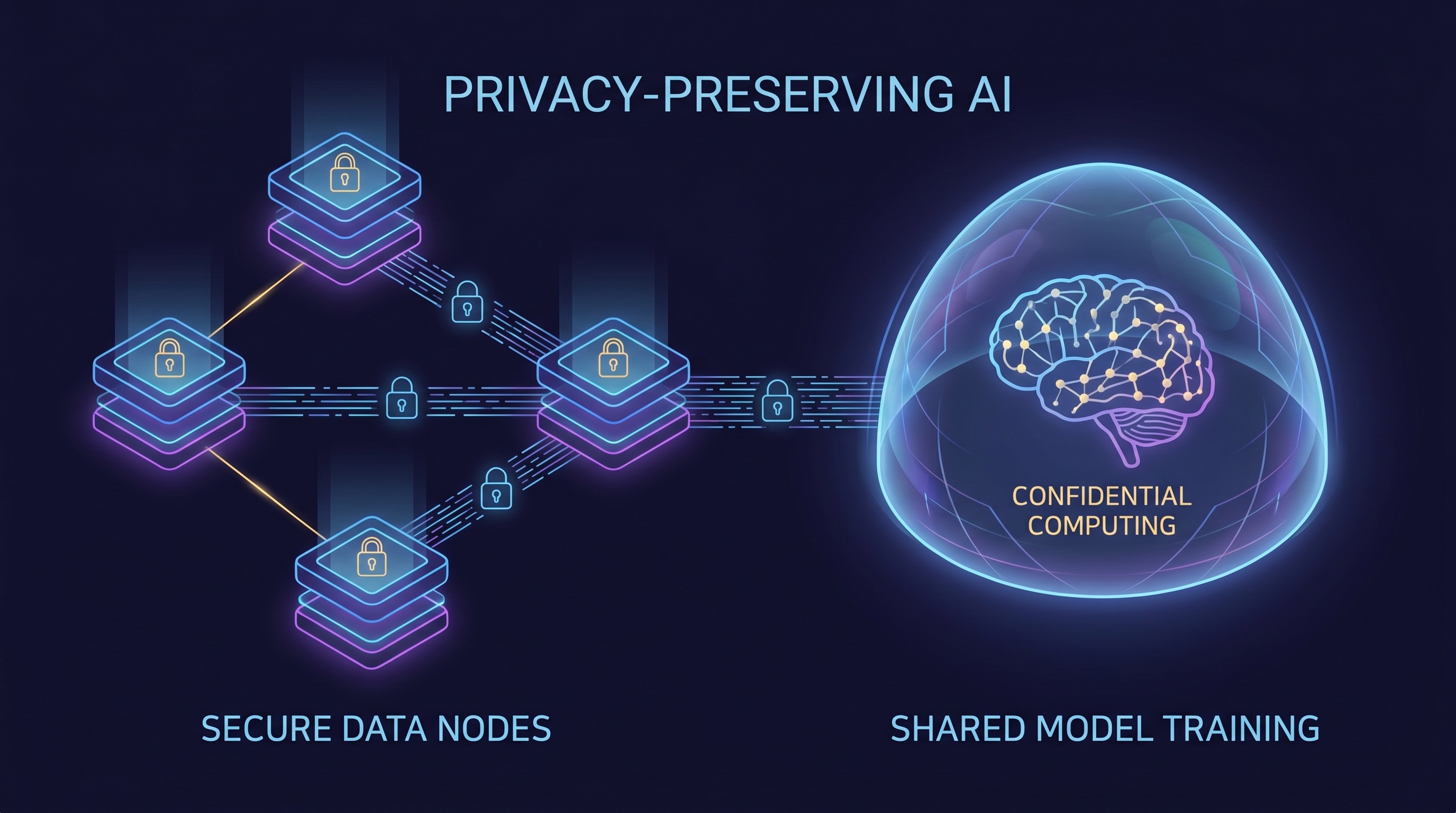
Federated Learning: Bringing the Model to the Data
One of the most prominent pillars of PPAI is federated learning (FL). As Google Cloud aptly explains, FL flips the traditional model on its head: instead of centralizing raw data, you send the model to the data. In a federated learning setup, individual data owners (e.g., hospitals, banks, mobile devices) train a local AI model on their own datasets. Only the updates to these local models—not the raw data itself—are then sent back to a central server for aggregation. This aggregated model update is then distributed back to the local participants, improving their models without ever exposing the underlying sensitive data.
This architecture is particularly revolutionary for regulated sectors. BizTech and IDC, in their April 2026 framing, highlight federated learning as a growing enterprise architecture, especially for healthcare and finance. Imagine multiple hospitals collaborating to train a more accurate diagnostic AI without ever sharing patient records. Or banks detecting sophisticated fraud patterns across institutions without pooling customer transaction histories. FL enables these powerful collaborations, unlocking insights from previously siloed and inaccessible data, all while maintaining strict privacy and compliance.
Confidential Computing: Protecting Data in Use
While federated learning addresses the privacy of data at rest and in transit (by not moving raw data), it doesn't inherently protect data in use—that is, while it's being processed by the local models or aggregated on the central server. This is where confidential computing (CC) enters the picture as a crucial complementary technology. Confidential computing uses hardware-based trusted execution environments (TEEs) to create secure enclaves. Within these enclaves, data and code are isolated and protected from unauthorized access, even from the cloud provider, operating system, or other applications running on the same hardware.
When combined with federated learning, confidential computing provides an end-to-end privacy solution. FL ensures raw data never leaves its source, and CC ensures that even the model updates and aggregation processes occur within a secure, verifiable environment. This dual-layer protection significantly mitigates the risk of data exposure during any stage of the AI lifecycle, offering enterprises a robust framework for handling their most sensitive information.
Beyond Buzzwords: PPAI as Architectural Imperative
The core thesis is clear: Privacy-Preserving AI is no longer a research novelty or a niche solution; it is rapidly becoming an architectural imperative for enterprises. The drive stems from a fundamental desire to leverage the full potential of AI and collaborate effectively, without the inherent risks associated with centralizing everything into one massive, vulnerable data pool. It represents a shift from a "collect everything, then secure it" mindset to a "secure by design, distribute by default" approach.
This architectural shift is driven by several factors:
- Regulatory Pressure: The global regulatory landscape is only becoming stricter, making PPAI a proactive compliance strategy.
- Competitive Advantage: Organizations that can securely collaborate and extract insights from sensitive data gain a significant edge.
- Ethical Responsibility: Building trust with customers and partners requires a demonstrable commitment to data privacy.
- Data Accessibility: PPAI unlocks data that would otherwise be too sensitive or legally restricted to use for AI training.
Benefits and Trade-offs
Adopting PPAI as enterprise data infrastructure offers compelling benefits:
- Enhanced Privacy & Security: Minimizes exposure of raw sensitive data, reducing the attack surface and breach risk.
- Regulatory Compliance: Simplifies adherence to complex data privacy laws by design.
- Secure Collaboration: Enables multiple parties to jointly train models without sharing proprietary or sensitive information.
- Access to Untapped Data: Unlocks insights from previously inaccessible, siloed, or highly regulated datasets.
- Reduced Centralization Risk: Avoids creating large, attractive targets for cyberattacks.
However, it's crucial to acknowledge the trade-offs and complexities:
- Implementation Complexity: Deploying and managing federated learning and confidential computing environments requires specialized expertise, robust infrastructure, and careful integration with existing systems.
- Performance Considerations: While improving rapidly, PPAI methods can sometimes introduce overheads in training time or may require careful tuning to achieve comparable model accuracy to centralized approaches.
- Governance Challenges: Managing distributed models, ensuring data quality at the source, establishing clear data usage policies, and auditing model updates across multiple participants introduce new governance complexities.
- Evolving Standards: The PPAI ecosystem is still maturing, with standards and best practices continually evolving, requiring organizations to stay agile and informed.
The Future of Enterprise Data Infrastructure
Privacy-Preserving AI is not just a trend; it is a foundational element for the future of enterprise data strategy. It empowers organizations to build more intelligent systems, foster secure data collaboration, and unlock new business models that were previously impossible due to privacy concerns. By embedding PPAI into their core data infrastructure, enterprises can move beyond merely reacting to privacy regulations and instead proactively build trust, innovate responsibly, and derive maximum value from their most sensitive assets.
The journey from research novelty to infrastructure choice underscores a critical realization: in an AI-driven world, data utility and data privacy are not mutually exclusive. With PPAI, they are becoming inextricably linked, paving the way for a more secure, collaborative, and intelligent future.