Why Privacy-Preserving AI Is Becoming a Real Product Strategy
For years, privacy-preserving AI often sounded like a side conversation attached to the real work of building models. Teams would talk about performance, training data scale, deployment cost, or GPU access first, then mention privacy as a compliance constraint that had to be managed somewhere in the stack. That order is starting to reverse in some important parts of the market.
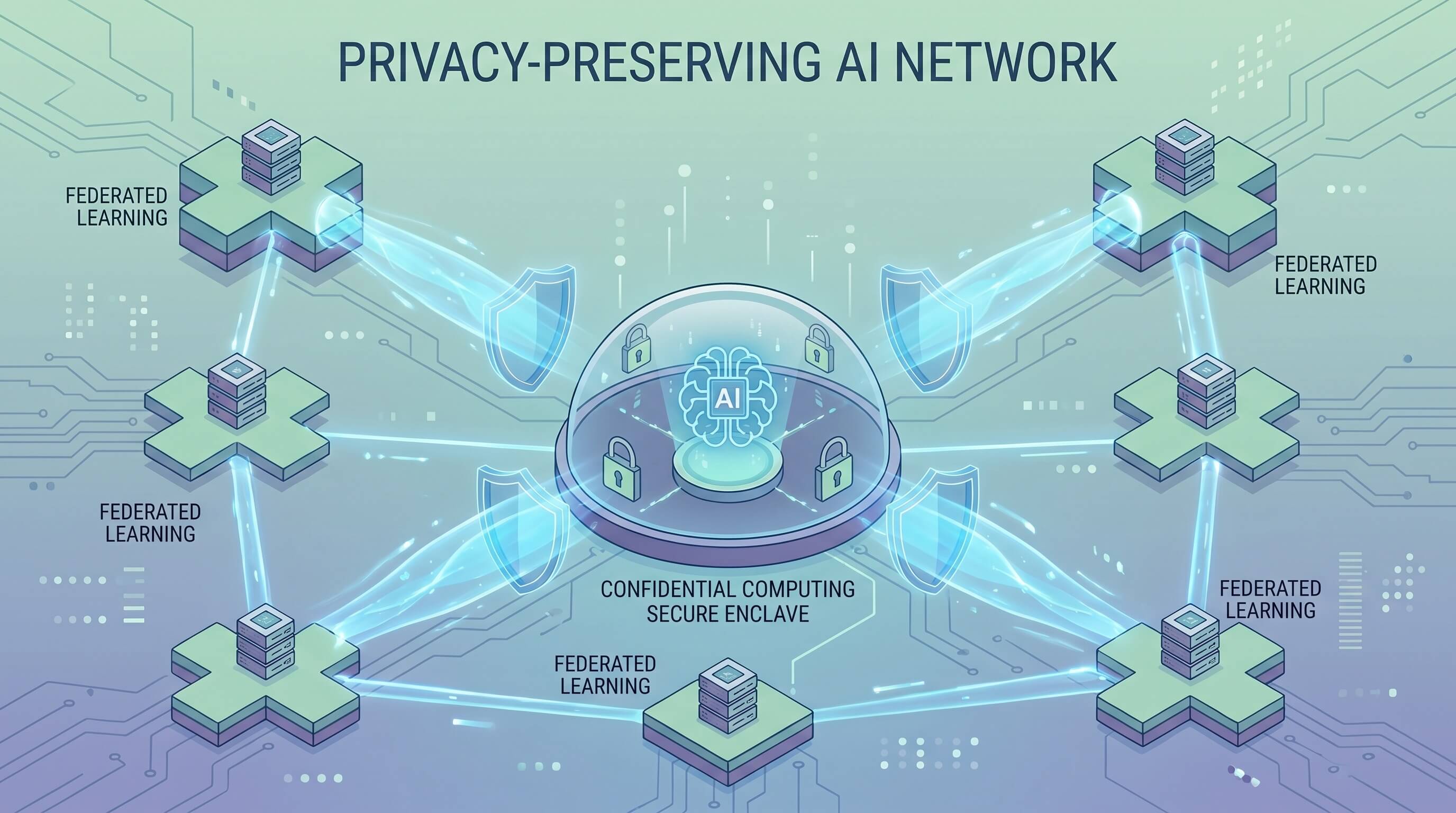
Privacy is becoming a product requirement, not just a legal requirement. In healthcare, finance, enterprise software, and consumer devices, organizations increasingly want AI systems that can learn from sensitive data, generate useful predictions, and still minimize exposure of raw information. That is why techniques such as federated learning, confidential computing, and on-device inference are getting more attention. They are not perfect, and they do not solve every data governance problem, but they are becoming practical design choices instead of purely academic concepts.
Why the timing changed
The shift is partly about trust. Users and enterprise buyers are more alert to the idea that AI value is often built from data they consider sensitive or proprietary. At the same time, regulators and internal risk teams are asking harder questions about where data moves, who can inspect it, and how training or inference environments are secured. That creates pressure for architectures that reduce unnecessary exposure rather than simply promising good intentions.
The shift is also about deployment reality. Many organizations have useful data they do not want, or are not allowed, to centralize. Hospitals may want model improvements without pooling raw patient records. Banks may want fraud signals without broadly sharing customer-level data. Device makers may want personalized features without shipping every interaction back to a cloud service. Privacy-preserving approaches become attractive in exactly these cases because they try to preserve utility while limiting raw data movement.
Federated learning is really about where learning happens
Federated learning is often described in a narrow way: train across many devices or institutions without moving all the underlying data to one place. That is directionally right, but the more important idea is architectural. It changes where learning happens and what leaves the environment. Instead of centralizing every record, a system can distribute training work and aggregate updates. That does not eliminate risk, and it still requires careful engineering around robustness, privacy leakage, and coordination, but it can align better with how sensitive data is actually governed.
Confidential computing is really about trusted execution
Confidential computing addresses a different part of the problem. The goal is to protect data while it is actively being processed, often by using hardware-based trusted execution environments. For AI teams, that can matter in model serving, cross-organization collaboration, or regulated enterprise workflows where the question is not only where data is stored, but who can access it during computation. It is one more way to reduce the trust surface around sensitive workloads.
Why this is turning into product strategy
What makes the current moment interesting is that these techniques are no longer discussed only by research teams. They are showing up in roadmap decisions. A company that can say, credibly, that user data stays on device, that training happens in a distributed way, or that sensitive inference runs inside protected environments has a clearer story for buyers, regulators, and partners. Privacy becomes part of the product promise.
That promise has limits. Privacy-preserving AI is not a magic label. Poor implementation, weak governance, or sloppy telemetry can undercut the whole claim. Some techniques also introduce performance tradeoffs, hardware constraints, or operational complexity. But the market significance is still real. The winners in AI will not only be the teams with the biggest models or the cheapest tokens. They may also be the teams that can prove they can deliver useful intelligence while exposing less sensitive data along the way.
That is a meaningful change. It suggests privacy is moving from a defensive posture to a competitive design principle. And once that happens, the conversation is no longer about whether privacy slows AI down. It is about which architectures make trustworthy AI more deployable at scale.