Privacy-Enhancing Technologies Are Moving From Compliance Theory to Data Infrastructure
The landscape of data privacy is undergoing a profound transformation, shifting from a theoretical compliance exercise to a foundational architectural imperative. For years, Privacy-Enhancing Technologies (PETs) were largely discussed in legal and academic circles, seen as advanced concepts for niche applications. However, a critical inflection point has arrived: privacy-preserving systems are now rapidly turning into mainstream data infrastructure because centralizing raw, sensitive data is becoming too risky, too regulated, and too operationally brittle. This evolution is not merely about adhering to stricter regulations like GDPR or CCPA; it's about enabling continued data utility and innovation in an environment where data breaches are costly, public trust is fragile, and the regulatory net is ever-widening.
The traditional model of aggregating vast datasets into central data lakes for analytics, machine learning, and business intelligence is increasingly untenable. The sheer volume of sensitive information creates an irresistible target for malicious actors and a significant liability for organizations. Consequently, the focus has shifted from merely securing data at rest and in transit to securing data in use and enabling collaborative analysis without direct data exposure. This paradigm shift mandates the adoption of PETs not as an optional security layer, but as integral components of modern data pipelines and governance frameworks, allowing organizations to derive insights and build models from sensitive information while minimizing exposure and maximizing privacy guarantees.
The Operational Imperative: Why PETs are Now Core Infrastructure
The move towards PETs as core infrastructure is driven by several converging factors. Firstly, the escalating cost of data breaches, both financial and reputational, forces a proactive stance on data protection. Secondly, the patchwork of global data sovereignty laws and privacy regulations makes cross-border data sharing and processing incredibly complex. Organizations face a dilemma: leverage data for competitive advantage or risk non-compliance and reputational damage. PETs offer a crucial third path, allowing data utility without compromising privacy or violating jurisdictional mandates. Thirdly, the rise of AI and Machine Learning (ML) models, which often require vast amounts of diverse data, necessitates new ways to access and process sensitive information without creating new privacy vulnerabilities. PETs provide the technical means to train models on distributed, sensitive datasets without ever exposing the underlying raw data.
Confidential Computing: Securing Data in Use
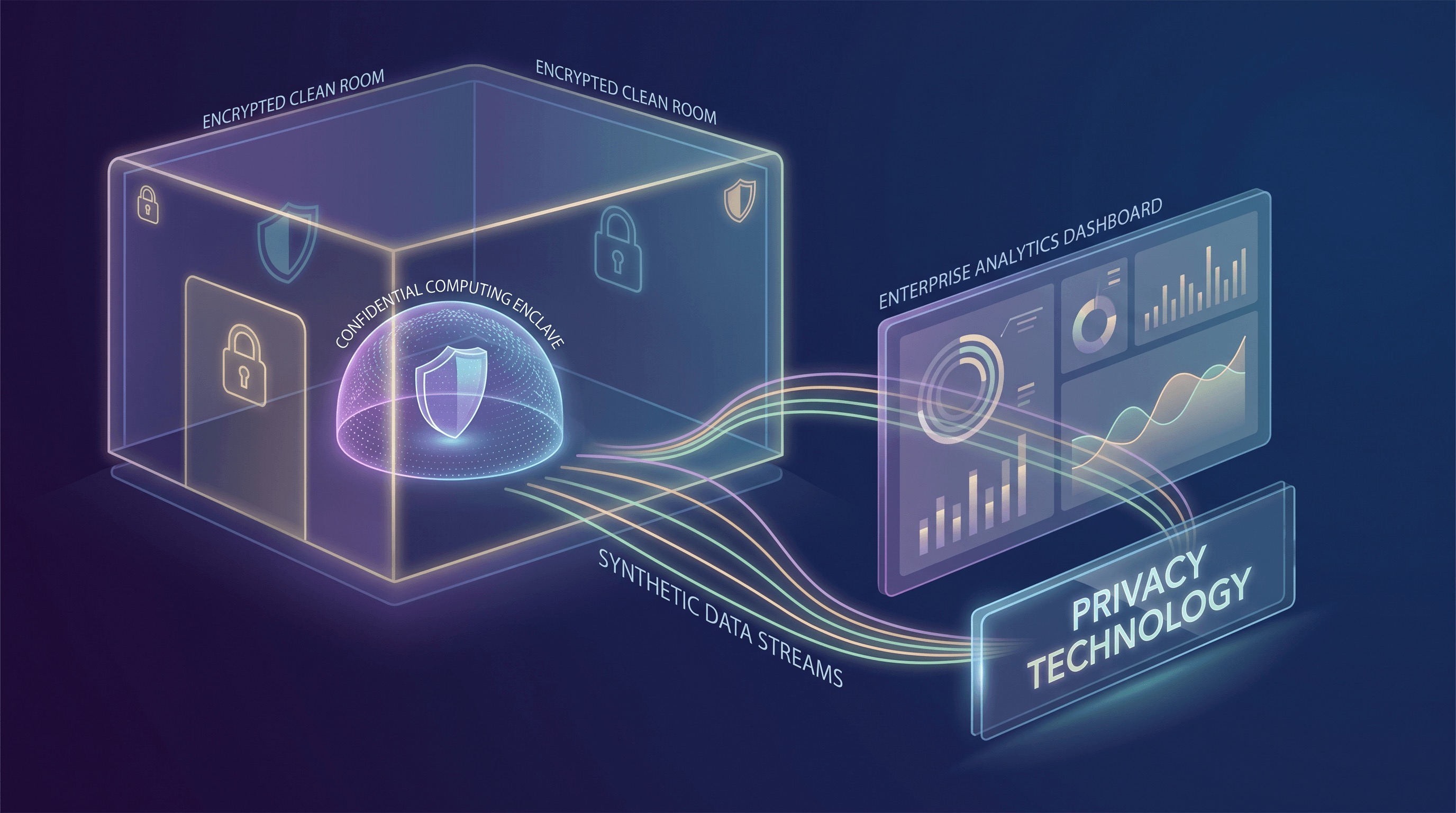
One of the most significant advancements in PETs is Confidential Computing. Traditionally, data security focused on encryption at rest (storage) and in transit (network). Confidential Computing completes this triad by protecting data in use – while it is being processed by the CPU and memory. This is achieved through hardware-based Trusted Execution Environments (TEEs), often referred to as enclaves. These TEEs create a secure, isolated environment within a CPU where data and code can be processed with strong integrity and confidentiality guarantees, even from the cloud provider or other privileged software on the same machine.
Google Cloud, for instance, defines Confidential Computing as a technology that encrypts data in memory and during computation, ensuring that the data remains inaccessible to the underlying infrastructure, including the cloud operator. This capability is transformative. It means that sensitive computations, such as processing personally identifiable information (PII) or proprietary algorithms, can be performed in the cloud with unprecedented levels of assurance. The market movement around Confidential Computing is robust, with offerings now spanning Confidential VMs, Confidential Spaces for containerized workloads, hardware attestation services, and specialized solutions for analytics and AI/ML use cases. This broad adoption signifies its transition from a niche security concept to a usable, scalable cloud infrastructure primitive, enabling scenarios previously deemed too risky for public cloud environments.
Data Clean Rooms: Collaborative Analytics with Privacy
Another powerful PET gaining traction is the Data Clean Room. Clean rooms provide a secure, controlled environment where multiple parties can collaborate on analyzing sensitive, often overlapping, datasets without directly exposing their raw data to each other. This is particularly valuable for advertising measurement, fraud detection, and supply chain optimization, where insights require combining data from different organizations. The core principle is that only aggregated, privacy-preserving insights are shared, never the individual-level raw data.
AWS Clean Rooms exemplifies this trend, offering a service that allows customers to securely analyze and collaborate on their combined datasets without sharing or revealing underlying data. A notable feature is the introduction of privacy-enhancing synthetic dataset generation for ML training within these clean rooms. This capability is crucial: it allows organizations to create statistically representative synthetic versions of their sensitive data. These synthetic datasets preserve the essential statistical patterns and relationships found in the original data, making them suitable for training ML models, while significantly reducing the risk of re-identification and membership inference. AWS provides fidelity and privacy metrics to help users understand the trade-offs and ensure the synthetic data meets their utility and privacy requirements. This innovation directly addresses the challenge of building powerful AI models that require extensive data without incurring the full privacy liabilities of sharing or centralizing raw PII.
Synthetic Data: A Versatile Privacy Tool
Beyond its application in clean rooms, synthetic data is emerging as a standalone, versatile Privacy-Enhancing Technology. Generated data that statistically mimics real data but contains no actual individual records offers a powerful solution for development, testing, and even some analytical tasks. The ability to generate high-fidelity synthetic datasets allows developers to build and test applications using realistic data without ever touching production PII. This accelerates development cycles, reduces compliance overhead, and minimizes the attack surface associated with handling sensitive information in non-production environments.
The sophistication of synthetic data generation has advanced considerably, leveraging generative AI models to capture complex correlations and distributions present in the original data. This ensures that models trained on synthetic data perform similarly to those trained on real data, making it a viable alternative for many ML workflows. The key is to balance utility and privacy, ensuring the synthetic data is useful enough for its intended purpose while providing strong guarantees against re-identification.
Federated Analysis: Learning Without Centralization
Federated Analysis, including its more specific application in Federated Learning, represents another critical PET for distributed data environments. Instead of centralizing raw data from multiple sources (e.g., different devices, organizations, or geographical regions) into one location for analysis or model training, federated methods bring the computation to the data. In Federated Learning, for example, a global model is trained by sending the model parameters to local devices or data silos. Each local entity trains the model on its private data, and only the updated model parameters (or gradients) are sent back to a central server, where they are aggregated to improve the global model. The raw data never leaves its original location.
This approach is particularly valuable for scenarios involving highly sensitive data distributed across many endpoints, such as medical records in different hospitals or user data on individual mobile devices. It allows for collaborative analytics and model training across diverse datasets without the immense privacy and logistical challenges of pooling raw data. Federated analysis inherently supports data sovereignty and minimizes the risk of large-scale data breaches, as no single entity ever holds all the raw information.
PETs as the New Data Architecture Foundation
The integration of these Privacy-Enhancing Technologies signifies a fundamental shift in how organizations approach data governance and utilization. They are no longer merely "nice-to-have" security features or complex academic curiosities. Instead, PETs are becoming the technical architecture that enables companies to continue leveraging sensitive data effectively under increasingly stringent privacy, data sovereignty, and AI governance expectations. This means that data architects, engineers, and privacy officers must increasingly understand and implement solutions like Confidential Computing, Data Clean Rooms, synthetic data generation, and federated analysis as standard components of their data infrastructure.
The future of data-driven innovation hinges on the ability to extract value from sensitive information responsibly. PETs provide the crucial bridge between data utility and privacy protection. As these technologies mature and become more accessible through cloud provider offerings and open-source initiatives, their adoption will accelerate, fundamentally reshaping how data is collected, processed, shared, and analyzed across industries. The era of centralizing raw data without consequence is drawing to a close; the era of intelligent, privacy-preserving data infrastructure is just beginning.