Warum datenschutzfreundliche KI zur Unternehmensdateninfrastruktur wird
In der sich schnell entwickelnden Landschaft der künstlichen Intelligenz kollidiert das Versprechen transformativer Erkenntnisse oft mit dem Gebot des Datenschutzes. Unternehmen weltweit ringen damit, wie sie die Leistungsfähigkeit der KI nutzen können, ohne sensible Informationen zu gefährden, strenge Vorschriften zu verletzen oder sich katastrophalen Datenlecks auszusetzen. Jahrelang bestand das dominante Paradigma darin, riesige Datensätze in monolithischen Data Lakes zu zentralisieren, eine Praxis, die zwar für das Modelltraining effizient war, aber immense Risiken barg. Heute findet ein grundlegender Wandel statt: Datenschutzfreundliche KI (PPAI) entwickelt sich über die akademische Neugier und Nischenanwendungen hinaus zu einem grundlegenden Bestandteil der Unternehmensdateninfrastruktur.
Das Dilemma der Datenzentralisierung und der Aufstieg von PPAI
Der traditionelle Ansatz zur KI-Entwicklung basiert stark auf der Aggregation von Daten. Ob es sich um Kundendaten, Finanztransaktionen oder medizinische Historien handelt, je mehr Daten ein KI-Modell zur Verfügung hat, desto besser ist in der Regel seine Leistung. Diese Zentralisierung schafft jedoch ein einziges, äußerst attraktives Ziel für Cyberkriminelle und einen Compliance-Albtraum für Organisationen. Vorschriften wie DSGVO, HIPAA, CCPA und unzählige andere legen strenge Regeln fest, wie persönliche und sensible Daten gesammelt, gespeichert, verarbeitet und geteilt werden dürfen. Die Nichteinhaltung zieht nicht nur hohe Geldstrafen nach sich, sondern auch erhebliche Reputationsschäden.
Dieses Dilemma hat die Entwicklung und Einführung von PPAI-Technologien vorangetrieben. PPAI umfasst eine Reihe von Methoden, die es KI-Modellen ermöglichen, aus Daten zu lernen, ohne direkt auf die rohen, sensiblen Informationen zuzugreifen oder diese offenzulegen. Es geht darum, Zusammenarbeit und Erkenntnisgewinn zu ermöglichen, während gleichzeitig höchste Standards für Datenschutz und Sicherheit eingehalten werden. Dies ist nicht nur eine ethische Überlegung; es ist eine strategische Notwendigkeit für jedes Unternehmen, das mit sensiblen Daten arbeitet.
Föderiertes Lernen: Das Modell zu den Daten bringen
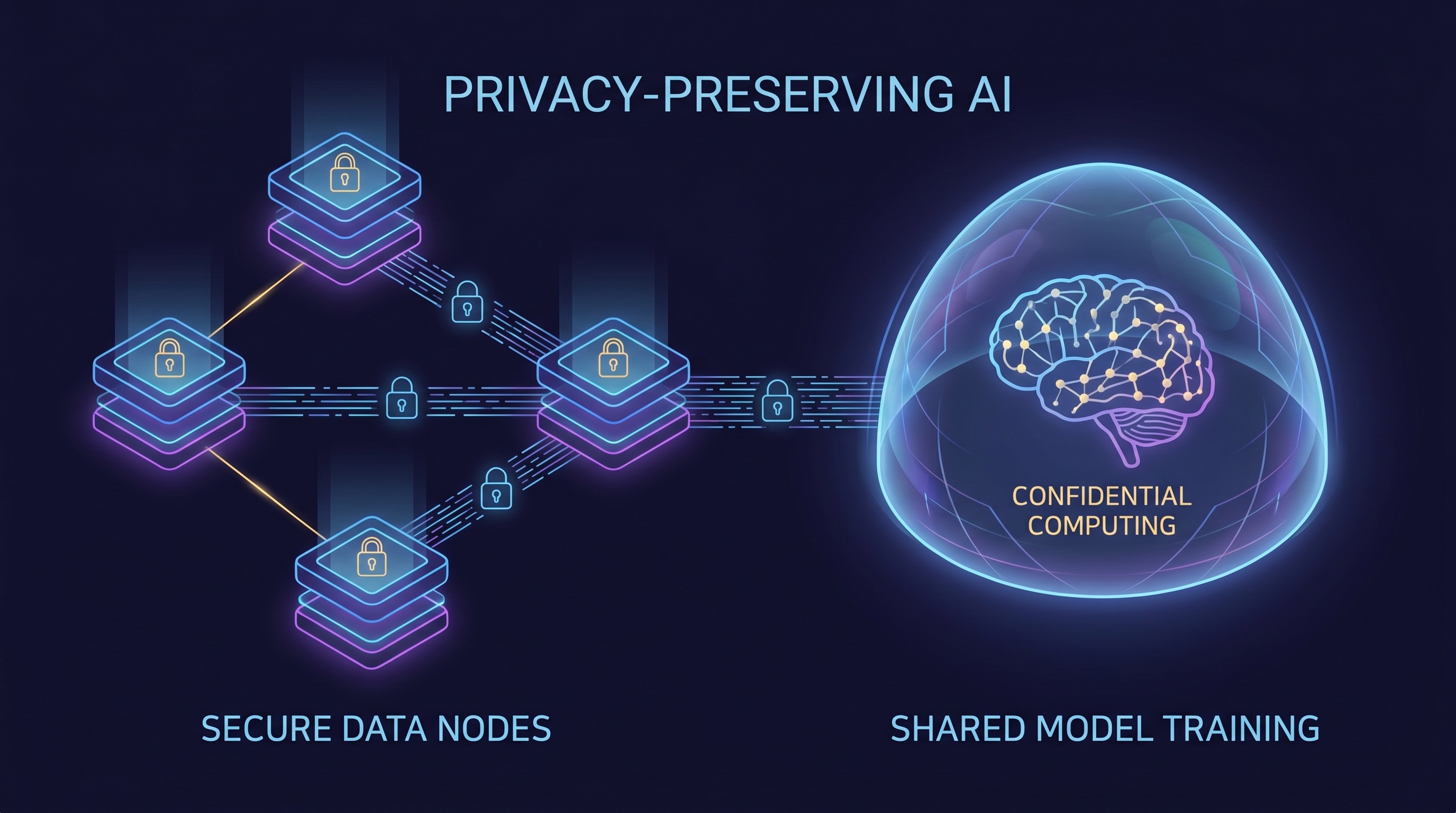
Eine der prominentesten Säulen von PPAI ist das föderierte Lernen (FL). Wie Google Cloud treffend erklärt, dreht FL das traditionelle Modell auf den Kopf: Anstatt Rohdaten zu zentralisieren, senden Sie das Modell zu den Daten. In einer föderierten Lernumgebung trainieren einzelne Datenbesitzer (z. B. Krankenhäuser, Banken, mobile Geräte) ein lokales KI-Modell auf ihren eigenen Datensätzen. Nur die Updates dieser lokalen Modelle – nicht die Rohdaten selbst – werden dann zur Aggregation an einen zentralen Server gesendet. Dieses aggregierte Modell-Update wird dann an die lokalen Teilnehmer zurückverteilt, wodurch deren Modelle verbessert werden, ohne die zugrunde liegenden sensiblen Daten jemals offenzulegen.
Diese Architektur ist besonders revolutionär für regulierte Sektoren. BizTech und IDC heben in ihrer Einschätzung vom April 2026 das föderierte Lernen als wachsende Unternehmensarchitektur hervor, insbesondere für das Gesundheitswesen und den Finanzsektor. Stellen Sie sich vor, mehrere Krankenhäuser arbeiten zusammen, um eine genauere diagnostische KI zu trainieren, ohne jemals Patientenakten auszutauschen. Oder Banken, die ausgeklügelte Betrugsmuster über Institutionen hinweg erkennen, ohne Kundentransaktionshistorien zusammenzuführen. FL ermöglicht diese leistungsstarken Kooperationen und erschließt Erkenntnisse aus zuvor isolierten und unzugänglichen Daten, alles unter Einhaltung strenger Datenschutz- und Compliance-Vorschriften.
Vertrauliches Computing: Schutz von Daten während der Nutzung
Während föderiertes Lernen den Datenschutz von Daten im Ruhezustand und während der Übertragung (durch Nichtverschieben von Rohdaten) adressiert, schützt es Daten während der Nutzung – d.h. während sie von den lokalen Modellen verarbeitet oder auf dem zentralen Server aggregiert werden – nicht von Natur aus. Hier kommt vertrauliches Computing (CC) als entscheidende ergänzende Technologie ins Spiel. Vertrauliches Computing verwendet hardwarebasierte Trusted Execution Environments (TEEs), um sichere Enklaven zu schaffen. Innerhalb dieser Enklaven sind Daten und Code vor unbefugtem Zugriff geschützt, selbst vor dem Cloud-Anbieter, dem Betriebssystem oder anderen Anwendungen, die auf derselben Hardware ausgeführt werden.
In Kombination mit föderiertem Lernen bietet vertrauliches Computing eine End-to-End-Datenschutzlösung. FL stellt sicher, dass Rohdaten niemals ihre Quelle verlassen, und CC gewährleistet, dass selbst die Modellaktualisierungen und Aggregationsprozesse in einer sicheren, überprüfbaren Umgebung stattfinden. Dieser zweischichtige Schutz mindert das Risiko der Datenexposition in jeder Phase des KI-Lebenszyklus erheblich und bietet Unternehmen einen robusten Rahmen für den Umgang mit ihren sensibelsten Informationen.
Jenseits von Schlagworten: PPAI als architektonisches Gebot
Die Kernthese ist klar: Datenschutzfreundliche KI ist keine Forschungsneuheit oder Nischenlösung mehr; sie wird schnell zu einem architektonischen Gebot für Unternehmen. Der Antrieb entspringt dem grundlegenden Wunsch, das volle Potenzial der KI zu nutzen und effektiv zusammenzuarbeiten, ohne die inhärenten Risiken, die mit der Zentralisierung von allem in einem massiven, anfälligen Datenpool verbunden sind. Es stellt einen Wandel von einer "alles sammeln, dann sichern"-Mentalität zu einem "sicher durch Design, standardmäßig verteilt"-Ansatz dar.
Dieser architektonische Wandel wird durch mehrere Faktoren vorangetrieben:
- Regulierungsdruck: Die globale Regulierungslandschaft wird immer strenger, was PPAI zu einer proaktiven Compliance-Strategie macht.
- Wettbewerbsvorteil: Organisationen, die sicher zusammenarbeiten und Erkenntnisse aus sensiblen Daten gewinnen können, erzielen einen erheblichen Vorteil.
- Ethische Verantwortung: Vertrauen bei Kunden und Partnern aufzubauen, erfordert ein nachweisbares Engagement für den Datenschutz.
- Datenzugänglichkeit: PPAI erschließt Daten, die sonst zu sensibel oder rechtlich eingeschränkt wären, um für das KI-Training verwendet zu werden.
Vorteile und Kompromisse
Die Einführung von PPAI als Unternehmensdateninfrastruktur bietet überzeugende Vorteile:
- Verbesserter Datenschutz & Sicherheit: Minimiert die Exposition roher sensibler Daten, reduziert die Angriffsfläche und das Risiko von Verstößen.
- Regulatorische Compliance: Vereinfacht die Einhaltung komplexer Datenschutzgesetze durch Design.
- Sichere Zusammenarbeit: Ermöglicht mehreren Parteien, Modelle gemeinsam zu trainieren, ohne proprietäre oder sensible Informationen auszutauschen.
- Zugriff auf ungenutzte Daten: Erschließt Erkenntnisse aus zuvor unzugänglichen, isolierten oder stark regulierten Datensätzen.
- Reduziertes Zentralisierungsrisiko: Vermeidet die Schaffung großer, attraktiver Ziele für Cyberangriffe.
Es ist jedoch entscheidend, die Kompromisse und Komplexitäten anzuerkennen:
- Implementierungskomplexität: Die Bereitstellung und Verwaltung von föderierten Lern- und vertraulichen Computing-Umgebungen erfordert spezialisiertes Fachwissen, robuste Infrastruktur und eine sorgfältige Integration in bestehende Systeme.
- Leistungsüberlegungen: Obwohl sie sich schnell verbessern, können PPAI-Methoden manchmal Overhead in der Trainingszeit verursachen oder eine sorgfältige Abstimmung erfordern, um eine vergleichbare Modellgenauigkeit wie zentralisierte Ansätze zu erreichen.
- Governance-Herausforderungen: Die Verwaltung verteilter Modelle, die Sicherstellung der Datenqualität an der Quelle, die Festlegung klarer Datennutzungsrichtlinien und die Prüfung von Modellaktualisierungen über mehrere Teilnehmer hinweg führen zu neuen Governance-Komplexitäten.
- Sich entwickelnde Standards: Das PPAI-Ökosystem reift noch, wobei sich Standards und Best Practices ständig weiterentwickeln, was von Organisationen verlangt, agil und informiert zu bleiben.
Die Zukunft der Unternehmensdateninfrastruktur
Datenschutzfreundliche KI ist nicht nur ein Trend; sie ist ein grundlegendes Element für die Zukunft der Unternehmensdatenstrategie. Sie befähigt Organisationen, intelligentere Systeme aufzubauen, eine sichere Datenzusammenarbeit zu fördern und neue Geschäftsmodelle zu erschließen, die zuvor aufgrund von Datenschutzbedenken unmöglich waren. Durch die Einbettung von PPAI in ihre Kern-Dateninfrastruktur können Unternehmen über die bloße Reaktion auf Datenschutzbestimmungen hinausgehen und stattdessen proaktiv Vertrauen aufbauen, verantwortungsvoll innovieren und den maximalen Wert aus ihren sensibelsten Vermögenswerten ziehen.
Der Weg von der Forschungsneuheit zur Infrastrukturwahl unterstreicht eine kritische Erkenntnis: In einer KI-gesteuerten Welt schließen sich Datennutzen und Datenschutz nicht gegenseitig aus. Mit PPAI werden sie untrennbar miteinander verbunden und ebnen den Weg für eine sicherere, kollaborativere und intelligentere Zukunft.