Warum KI-Agenten Speicher benötigen, nicht nur größere Kontextfenster
Wir schreiben das Jahr 2026, und die KI-Landschaft entwickelt sich in atemberaubendem Tempo. Wir haben gesehen, wie Kontextfenster für große Sprachmodelle (LLMs) von wenigen Tausend Token auf weit über eine Million angewachsen sind, was eine Zukunft verspricht, in der Agenten riesige Informationsmengen in einem einzigen Prompt verarbeiten können. Dies ist zweifellos ein mächtiger Fortschritt, doch für viele, die in der Unternehmens-KI arbeiten, setzt sich eine kritische Erkenntnis durch: Größere Kontextfenster allein sind nicht die Patentlösung für wirklich effektive, langlebige KI-Agenten. Der wahre Unterschied, wie Cloudflare es treffend formulierte, liegt in der Fähigkeit, sich an das zu erinnern, was wichtig ist, ohne ständig das Kontextfenster zu füllen, und so das sehr reale Produktionsproblem des 'Kontextverfalls' anzugehen.
Die Grenzen eines längeren Prompts
Stellen Sie sich vor, Sie versuchen, sich an jedes Detail eines einjährigen Projekts zu erinnern, indem Sie jedes einzelne E-Mail, jedes Besprechungsprotokoll und jedes Dokument von Anfang bis Ende jedes Mal neu lesen, wenn Sie eine Entscheidung treffen müssen. Das ist im Wesentlichen das, was wir von einem KI-Agenten verlangen, wenn wir uns ausschließlich auf ein ständig wachsendes Kontextfenster verlassen. Obwohl beeindruckend, hat dieser Ansatz inhärente Einschränkungen:
- Kosten und Latenz: Die Verarbeitung von Millionen von Token für jede Interaktion ist rechenintensiv und führt zu erheblichen Latenzzeiten, was Echtzeitanwendungen schwierig macht.
- Informationsüberflutung: Genau wie Menschen können auch KI-Modelle Schwierigkeiten haben, die relevantesten Informationen zu identifizieren, wenn ihnen eine überwältigende Datenmenge präsentiert wird. Wichtige Details können untergehen, was zu weniger genauen oder weniger effizienten Antworten führt.
- Episodische Gedächtnislücke: Ein großes Kontextfenster bietet eine Momentaufnahme der aktuellen Interaktion, baut aber nicht von Natur aus ein dauerhaftes Verständnis vergangener Interaktionen, Benutzerpräferenzen oder langfristiger Ziele auf. Jeder neue Prompt ist weitgehend ein Neuanfang, wenn auch mit mehr unmittelbarem Kontext.
Wie Microsoft Learn weise rät, sollte das Ziel immer sein, die Architektur mit der geringsten Komplexität zu verwenden, die zuverlässig funktioniert. Einfach mehr Token auf ein Problem zu werfen, erhöht oft die Komplexität, nicht die eleganten Lösungen.
Warum Speicher der Game Changer ist
Anstatt den Prompt nur zu verlängern, hängt die wahre agentische Intelligenz von dauerhaftem Speicher und intelligenter Kontextorchestrierung ab. Dies ermöglicht es einem KI-Agenten, ein persistentes, sich entwickelndes Verständnis seiner Umgebung, Benutzer und Aufgaben aufzubauen, ähnlich wie ein Mensch es tut. Es geht um selektives Erinnern, nicht um brutales erneutes Lesen.
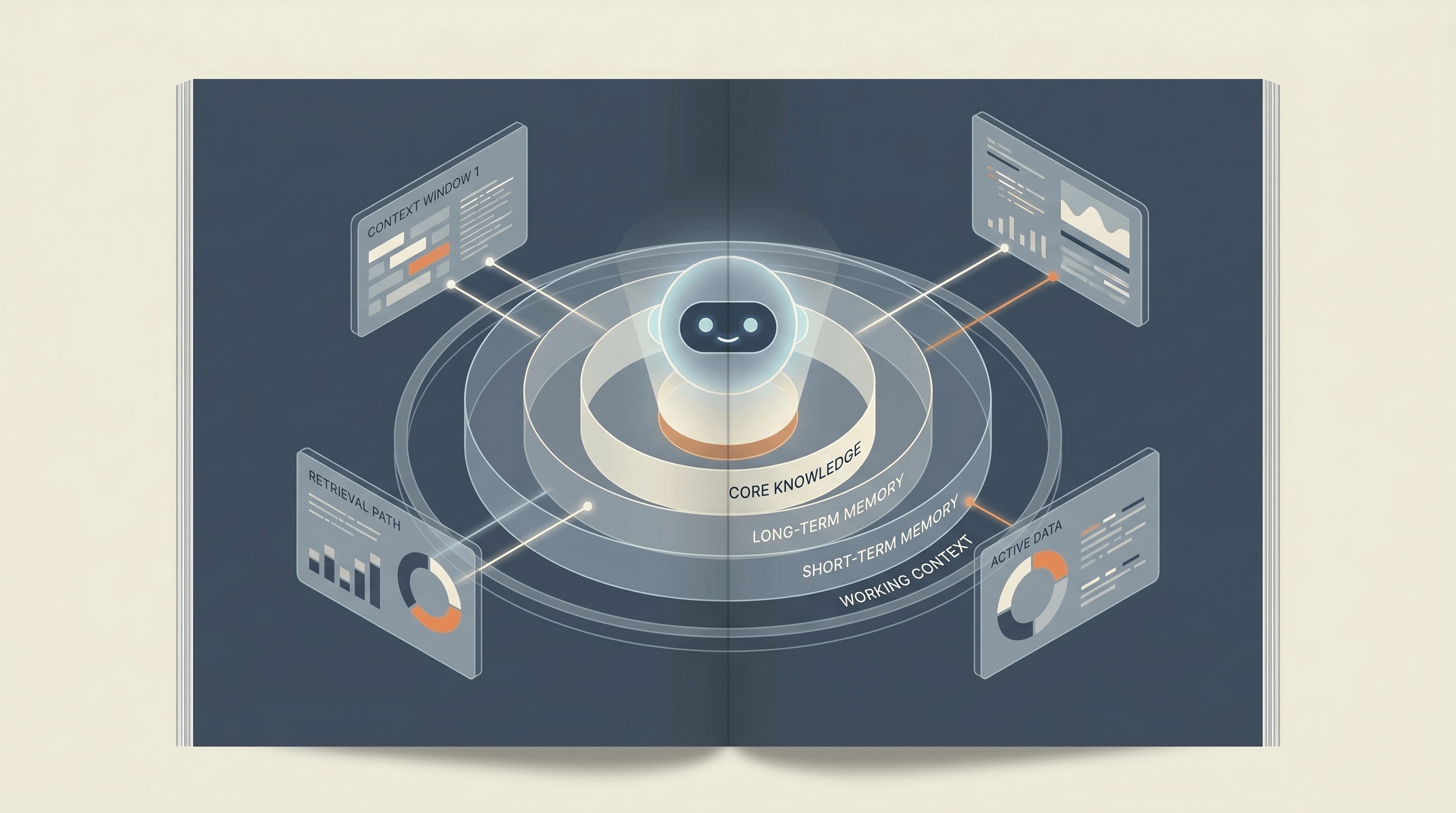
Verschiedene Arten von Agenten-Speicher
Um zu verstehen, wie Speicher KI-Agenten befähigt, ist es hilfreich, ihn in verschiedene Schichten zu unterteilen:
- Arbeitskontext (Kurzzeit): Dies ist der unmittelbare, flüchtige Speicher innerhalb des aktuellen Prompt-Fensters. Er enthält die jüngsten Gesprächsrunden oder die unmittelbar verarbeiteten Daten. Er ist entscheidend für eine kohärente Echtzeit-Interaktion.
- Abgerufene Fakten (Wissensbasis): Oft mittels Retrieval-Augmented Generation (RAG) und Vektordatenbanken implementiert, ermöglicht diese Schicht Agenten den Zugriff auf riesige Mengen externer, faktischer Informationen (Dokumente, Datenbanken, Webinhalte). So weiß ein Agent spezifische Unternehmensrichtlinien oder technische Spezifikationen, ohne sie explizit in seinem Arbeitskontext zu haben.
- Benutzerpräferenzen/Personalisierung: Dieser dauerhafte Speicher speichert langfristige Informationen über die Gewohnheiten, Präferenzen, historischen Interaktionen und demografischen Daten eines bestimmten Benutzers (mit entsprechenden Datenschutzvorkehrungen). Er ermöglicht personalisierte Erlebnisse, indem er sich beispielsweise die bevorzugte Sprache eines Benutzers oder die übliche Bestellhistorie merkt.
- Aufgabenhistorie (Episodisches Gedächtnis): Diese Schicht verfolgt die Abfolge von Aktionen, Entscheidungen und Ergebnissen innerhalb eines bestimmten Workflows oder einer Reihe von Interaktionen über die Zeit. Sie ermöglicht es einem Agenten, sich daran zu erinnern, dass ein Kunde letzte Woche wegen eines ähnlichen Problems angerufen hat oder dass eine bestimmte Aufgabe unterbrochen wurde und fortgesetzt werden muss. Dies ist entscheidend für die Kontinuität in komplexen, mehrstufigen Prozessen.
- Prozedurales Gedächtnis (Fähigkeiten & Werkzeuge): Hier geht es nicht um Fakten, sondern um 'wie man Dinge tut'. Es umfasst die gelernten Muster, Werkzeugnutzungsfähigkeiten und API-Integrationen, die ein Agent nutzen kann, um Ziele zu erreichen. So weiß ein Agent, dass er eine bestimmte API aufrufen muss, um den Lagerbestand zu überprüfen oder einen Bericht zu erstellen.
Praktische Auswirkungen: Anwendungsfälle in Unternehmen
Für Unternehmen sind die Auswirkungen eines robusten Agenten-Speichers tiefgreifend. Er verwandelt KI-Agenten von reaktiven Chatbots in proaktive, intelligente Assistenten, die in der Lage sind, komplexe, langwierige Aufgaben zu bewältigen:
- Langlaufende Support-Workflows: Ein Agent kann die gesamte Support-Historie eines Kunden, frühere Fehlerbehebungsschritte und spezifische Produktkonfigurationen über mehrere Interaktionen hinweg speichern, wodurch der Kunde sich nicht wiederholen muss.
- Code-Agenten: Ein Code-Assistent kann Kenntnisse über die Architektur eines Projekts, Codierungsstandards, bevorzugte Bibliotheken und frühere Refactorings behalten. Er kann den Stil des Entwicklers verstehen und über Tage oder Wochen hinweg kontextuell relevantere Vorschläge machen.
- Forschungsassistenten: Für Analysten oder Forscher kann ein KI-Agent frühere Anfragen, überprüfte Quellen, extrahierte Schlüsselergebnisse und die allgemeinen Forschungsziele verfolgen und so eine kumulative Wissensbasis aufbauen, die sich mit dem Projekt entwickelt.
- Betriebliche Automatisierung: Agenten, die komplexe Systeme überwachen, können aus früheren Vorfällen lernen, sich an spezifische Abhilfemaßnahmen erinnern, die funktioniert haben (oder fehlgeschlagen sind), und den historischen Zustand verschiedener Komponenten verstehen, was zu einer intelligenteren und widerstandsfähigeren Automatisierung führt.
Der verantwortungsvolle Ansatz: Risiken und Überlegungen
Obwohl leistungsstark, ist der Agenten-Speicher nicht ohne Herausforderungen. Ein ausgewogener Ansatz ist entscheidend:
- Veraltete Erinnerungen: Im Speicher gespeicherte Informationen können veraltet sein. Mechanismen zum Aktualisieren, Ungültigmachen oder Auffrischen von Erinnerungen sind unerlässlich, um zu verhindern, dass Agenten auf der Grundlage falscher Daten handeln.
- Schlechter Abruf/Halluzinationen: Wenn der Abrufmechanismus fehlerhaft ist oder die gespeicherten Erinnerungen ungenau sind, könnte der Agent 'halluzinieren' oder auf falschen Annahmen handeln, ähnlich wie ein LLM falsche Informationen generieren kann.
- Datenschutz- und Sicherheitslecks: Das Speichern sensibler Benutzer- oder Unternehmensdaten in Speicherschichten birgt erhebliche Datenschutz- und Sicherheitsrisiken. Robuste Governance, Zugriffskontrollen und Datenanonymisierungstechniken sind von größter Bedeutung. Prompt Injection durch abgerufene Daten ist ebenfalls ein Problem, wenn externe Daten nicht ordnungsgemäß bereinigt werden.
- Überentwicklung: Wie Microsoft Learn warnte, nicht überkomplizieren. Multi-Agenten-Orchestrierung und komplexe Speicherarchitekturen erhöhen den Koordinationsaufwand, die Latenz und die Kosten. Für einfache, einmalige Aufgaben könnte ein größeres Kontextfenster tatsächlich ausreichen. Der Schlüssel ist architektonische Disziplin – das richtige Werkzeug für die Aufgabe wählen.
- Governance: Wem gehören die Erinnerungen? Wie werden sie auditiert? Wie stellen Sie die Einhaltung der Datenaufbewahrungsrichtlinien sicher? Diese Fragen werden entscheidend, wenn Speichersysteme reifen.
Fazit
Im Jahr 2026 hat sich die Diskussion um KI-Agenten über die bloße Größe ihrer sprachlichen Verarbeitungskapazität hinaus entwickelt. Während immer größere Kontextfenster ein wertvolles Werkzeug sind, sind sie kein Ersatz für intelligente Speichersysteme. Für reale, unternehmenstaugliche KI-Agenten, die über einen längeren Zeitraum effektiv arbeiten müssen, sind dauerhafter Speicher und durchdachte Kontextorchestrierung von größter Bedeutung. Es geht darum, Systeme zu bauen, die Informationen nicht nur verarbeiten, sondern wirklich verstehen, sich anpassen und aus ihren Erfahrungen lernen. Durch die sorgfältige Gestaltung von Speicherschichten und das Verständnis ihrer Kompromisse können wir KI-Agenten bauen, die nicht nur leistungsstark, sondern auch zuverlässig, effizient und wirklich nützlich sind und Unternehmen dabei helfen, komplexe Herausforderungen ohne unnötigen architektonischen Overhead zu bewältigen.