Denkmodelle vs. Standard-LLMs: Was sich ändert, wenn eine KI vor der Antwort nachdenkt
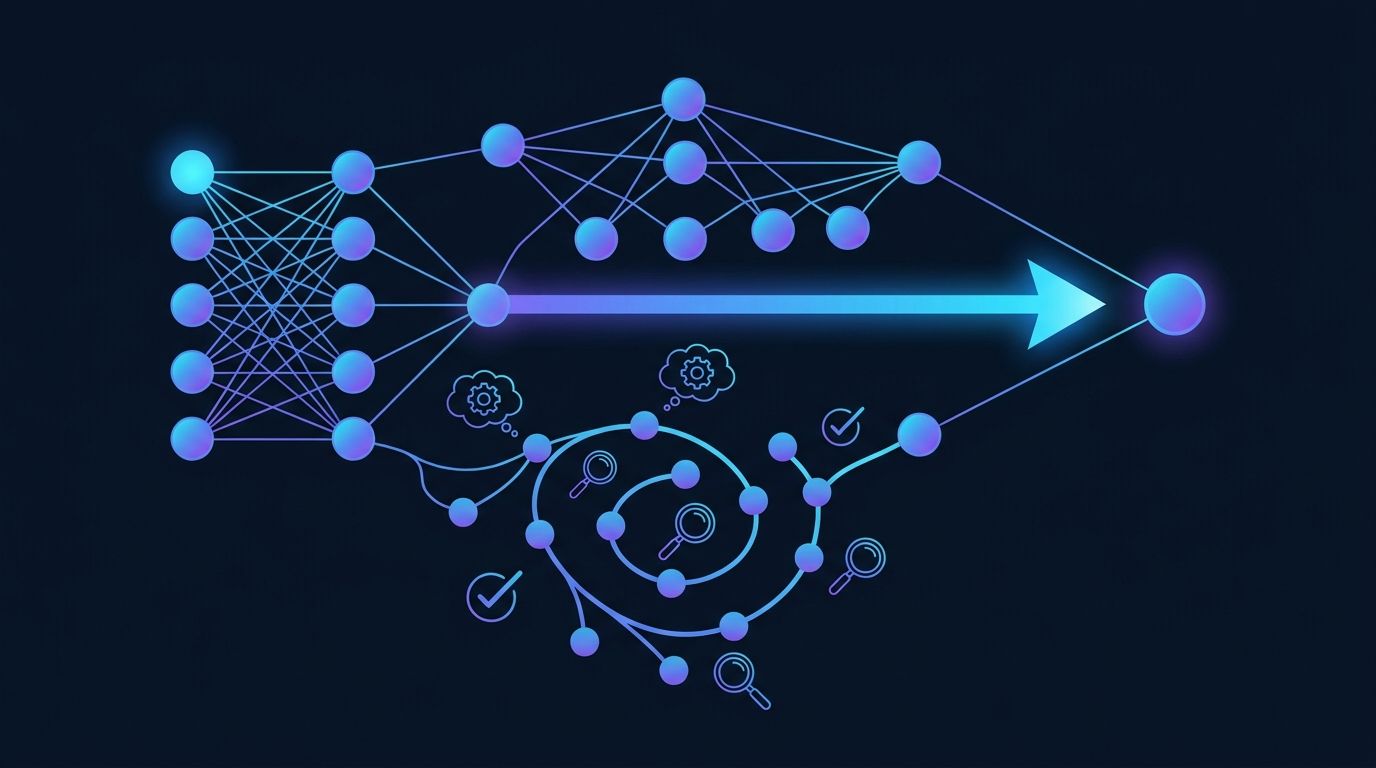
Der grundlegende Unterschied liegt darin, wo die Arbeit stattfindet
Standard-Sprachmodelle — GPT-4o, Claude Sonnet, Gemini Flash — kodieren Denkmuster während des Trainings und wenden sie bei der Inferenz in einem einzigen Vorwärtsdurchlauf an. Reasoning-Modelle wie OpenAI o3, o4-mini, Claude claude-opus-4-8 und Gemini 2.5 Pro weisen zusätzliche Rechenleistung zur Inferenzzeit zu — Test-Time Compute. Bei AIME 2024 erzielt GPT-4o etwa 13% und OpenAI o3 über 96%. Beim ARC-AGI-Benchmark erreichte o3 87,5% während GPT-4o unter 10% blieb.
GPT-4o bleibt die Standardwahl für hochvolumige, latenzsensitive Anwendungen. O4-mini übertrifft GPT-4o bei Competitive-Programming-Benchmarks um mehr als 30 Prozentpunkte. DeepSeek R2 ist die Option zur Evaluierung wenn man Reasoning-Fähigkeit zu niedrigeren Kosten braucht. Asynchrone Pipelines bauen wenn man Reasoning-Modelle in der Produktion einsetzt.