Privacy-Enhancing Technologies entwickeln sich von der Compliance-Theorie zur Dateninfrastruktur
Die Landschaft des Datenschutzes durchläuft einen tiefgreifenden Wandel, der sich von einer theoretischen Compliance-Übung zu einem grundlegenden architektonischen Imperativ entwickelt. Jahrelang wurden Privacy-Enhancing Technologies (PETs) hauptsächlich in juristischen und akademischen Kreisen diskutiert und als fortgeschrittene Konzepte für Nischenanwendungen betrachtet. Ein kritischer Wendepunkt ist jedoch erreicht: Datenschutzsysteme entwickeln sich nun schnell zu einer Mainstream-Dateninfrastruktur, da die Zentralisierung roher, sensibler Daten zu riskant, zu stark reguliert und operativ zu anfällig wird. Diese Entwicklung geht nicht nur darum, strengere Vorschriften wie die DSGVO oder CCPA einzuhalten; es geht darum, die fortgesetzte Datennutzung und Innovation in einem Umfeld zu ermöglichen, in dem Datenlecks kostspielig sind, das öffentliche Vertrauen fragil ist und das regulatorische Netz immer enger wird.
Das traditionelle Modell der Aggregation riesiger Datensätze in zentrale Data Lakes für Analysen, Machine Learning und Business Intelligence ist zunehmend unhaltbar. Das schiere Volumen sensibler Informationen schafft ein unwiderstehliches Ziel für böswillige Akteure und eine erhebliche Haftung für Organisationen. Folglich hat sich der Fokus von der bloßen Sicherung von Daten im Ruhezustand (at rest) und während der Übertragung (in transit) auf die Sicherung von Daten während der Nutzung und die Ermöglichung kollaborativer Analysen ohne direkte Datenexposition verlagert. Dieser Paradigmenwechsel erfordert die Einführung von PETs nicht als optionale Sicherheitsebene, sondern als integrale Bestandteile moderner Datenpipelines und Governance-Frameworks, die es Organisationen ermöglichen, Erkenntnisse zu gewinnen und Modelle aus sensiblen Informationen zu erstellen, während die Exposition minimiert und die Datenschutzgarantien maximiert werden.
Der operative Imperativ: Warum PETs jetzt Kerninfrastruktur sind
Die Verlagerung hin zu PETs als Kerninfrastruktur wird durch mehrere konvergierende Faktoren vorangetrieben. Erstens zwingen die eskalierenden Kosten von Datenlecks, sowohl finanziell als auch reputativ, zu einer proaktiven Haltung beim Datenschutz. Zweitens macht das Patchwork globaler Datensouveränitätsgesetze und Datenschutzbestimmungen den grenzüberschreitenden Datenaustausch und die -verarbeitung unglaublich komplex. Organisationen stehen vor einem Dilemma: Daten für Wettbewerbsvorteile nutzen oder das Risiko der Nichteinhaltung und des Reputationsschadens eingehen. PETs bieten einen entscheidenden dritten Weg, der die Datennutzung ohne Beeinträchtigung der Privatsphäre oder Verletzung von Gerichtsbarkeitsmandaten ermöglicht. Drittens erfordert der Aufstieg von AI- und Machine Learning (ML)-Modellen, die oft große Mengen unterschiedlicher Daten benötigen, neue Wege für den Zugriff und die Verarbeitung sensibler Informationen, ohne neue Datenschutzlücken zu schaffen. PETs bieten die technischen Mittel, um Modelle auf verteilten, sensiblen Datensätzen zu trainieren, ohne die zugrunde liegenden Rohdaten jemals offenzulegen.
Confidential Computing: Daten während der Nutzung sichern
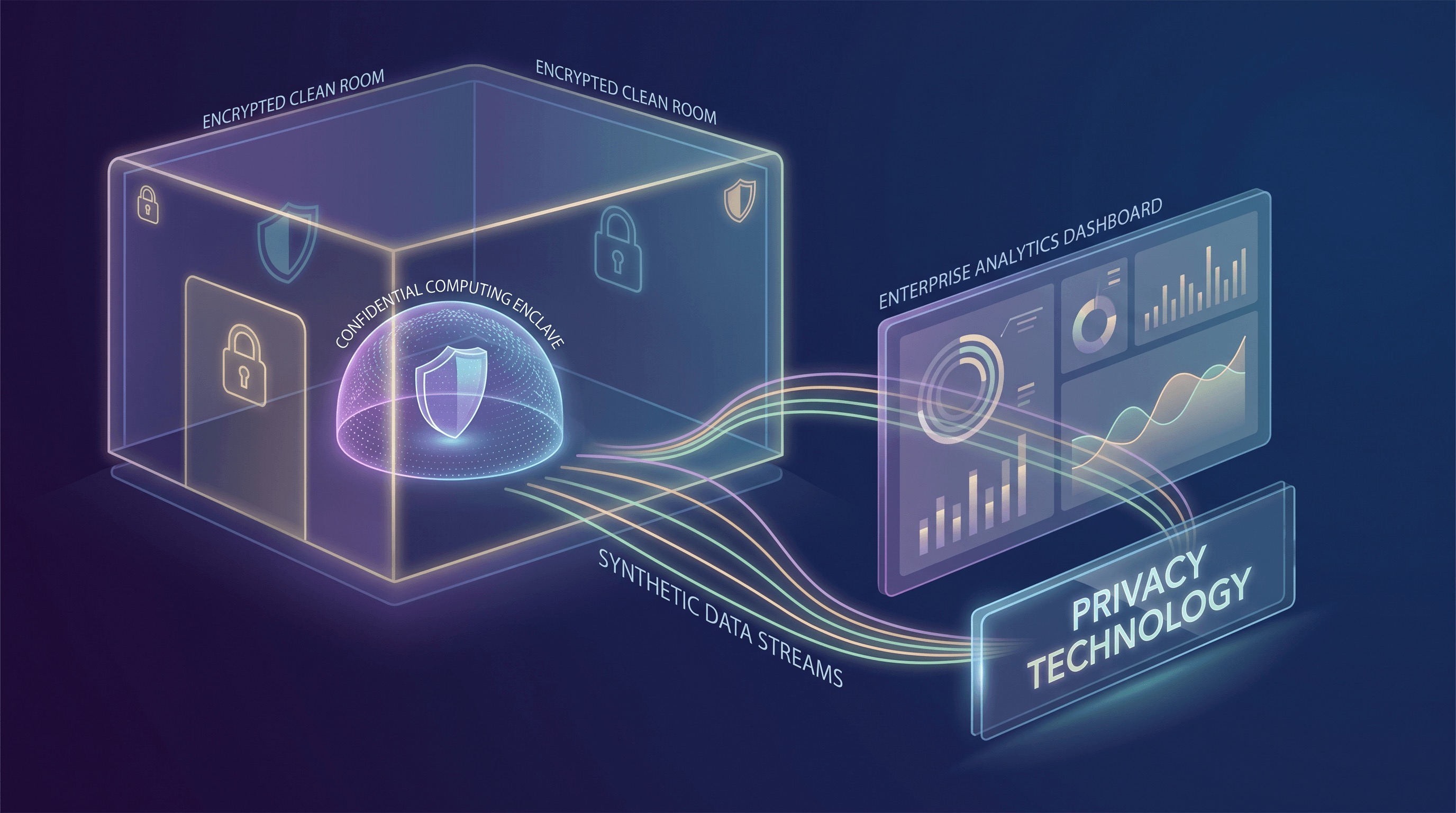
Eine der bedeutendsten Fortschritte bei PETs ist Confidential Computing. Traditionell konzentrierte sich die Datensicherheit auf die Verschlüsselung im Ruhezustand (Speicherung) und während der Übertragung (Netzwerk). Confidential Computing vervollständigt diese Triade, indem es Daten während der Nutzung schützt – während sie von der CPU und dem Speicher verarbeitet werden. Dies wird durch hardwarebasierte Trusted Execution Environments (TEEs) erreicht, die oft als Enklaven bezeichnet werden. Diese TEEs schaffen eine sichere, isolierte Umgebung innerhalb einer CPU, in der Daten und Code mit starken Integritäts- und Vertraulichkeitsgarantien verarbeitet werden können, selbst vor dem Cloud-Anbieter oder anderer privilegierter Software auf derselben Maschine.
Google Cloud definiert Confidential Computing beispielsweise als eine Technologie, die Daten im Speicher und während der Berechnung verschlüsselt und sicherstellt, dass die Daten für die zugrunde liegende Infrastruktur, einschließlich des Cloud-Betreibers, unzugänglich bleiben. Diese Fähigkeit ist transformativ. Sie bedeutet, dass sensible Berechnungen, wie die Verarbeitung von persönlich identifizierbaren Informationen (PII) oder proprietären Algorithmen, in der Cloud mit beispielloser Sicherheit durchgeführt werden können. Die Marktbewegung um Confidential Computing ist robust, mit Angeboten, die jetzt Confidential VMs, Confidential Spaces für containerisierte Workloads, Hardware-Attestierungsdienste und spezialisierte Lösungen für Analytics- und AI/ML-Anwendungsfälle umfassen. Diese breite Akzeptanz signalisiert den Übergang von einem Nischen-Sicherheitskonzept zu einem nutzbaren, skalierbaren Cloud-Infrastruktur-Primitiv, das Szenarien ermöglicht, die zuvor für öffentliche Cloud-Umgebungen als zu riskant galten.
Data Clean Rooms: Kollaborative Analysen mit Datenschutz
Eine weitere leistungsstarke PET, die an Bedeutung gewinnt, ist der Data Clean Room. Clean Rooms bieten eine sichere, kontrollierte Umgebung, in der mehrere Parteien bei der Analyse sensibler, oft überlappender Datensätze zusammenarbeiten können, ohne ihre Rohdaten direkt miteinander zu teilen. Dies ist besonders wertvoll für die Werbemessung, Betrugserkennung und Lieferkettenoptimierung, wo Erkenntnisse die Kombination von Daten aus verschiedenen Organisationen erfordern. Das Kernprinzip ist, dass nur aggregierte, datenschutzfreundliche Erkenntnisse geteilt werden, niemals die Rohdaten auf individueller Ebene.
AWS Clean Rooms veranschaulicht diesen Trend und bietet einen Dienst an, der es Kunden ermöglicht, ihre kombinierten Datensätze sicher zu analysieren und daran zusammenzuarbeiten, ohne zugrunde liegende Daten zu teilen oder offenzulegen. Ein bemerkenswertes Merkmal ist die Einführung der datenschutzfreundlichen Generierung synthetischer Datensätze (Synthetic Dataset Generation) für das ML-Training innerhalb dieser Clean Rooms. Diese Fähigkeit ist entscheidend: Sie ermöglicht es Organisationen, statistisch repräsentative synthetische Versionen ihrer sensiblen Daten zu erstellen. Diese synthetischen Datensätze bewahren die wesentlichen statistischen Muster und Beziehungen, die in den Originaldaten gefunden werden, wodurch sie für das Training von ML-Modellen geeignet sind, während das Risiko der Re-Identifizierung und der Mitgliedschaftsinferenz erheblich reduziert wird. AWS bietet Genauigkeits- und Datenschutzmetriken, um Benutzern zu helfen, die Kompromisse zu verstehen und sicherzustellen, dass die synthetischen Daten ihren Nutzungs- und Datenschutzanforderungen entsprechen. Diese Innovation adressiert direkt die Herausforderung, leistungsstarke AI-Modelle zu entwickeln, die umfangreiche Daten erfordern, ohne die vollständigen Datenschutzhaftungen des Teilens oder Zentralisierens von Roh-PII einzugehen.
Synthetic Data: Ein vielseitiges Datenschutz-Tool
Über ihre Anwendung in Clean Rooms hinaus entwickeln sich Synthetic Data zu einer eigenständigen, vielseitigen Privacy-Enhancing Technology. Generierte Daten, die reale Daten statistisch nachahmen, aber keine tatsächlichen Einzeldatensätze enthalten, bieten eine leistungsstarke Lösung für Entwicklung, Tests und sogar einige analytische Aufgaben. Die Möglichkeit, hochpräzise synthetische Datensätze zu generieren, ermöglicht es Entwicklern, Anwendungen mit realistischen Daten zu erstellen und zu testen, ohne jemals auf Produktions-PII zugreifen zu müssen. Dies beschleunigt Entwicklungszyklen, reduziert den Compliance-Overhead und minimiert die Angriffsfläche, die mit der Handhabung sensibler Informationen in Nicht-Produktionsumgebungen verbunden ist.
Die Raffinesse der Synthetic Data-Generierung hat erheblich zugenommen, indem generative AI-Modelle (Generative AI) genutzt werden, um komplexe Korrelationen und Verteilungen in den Originaldaten zu erfassen. Dies stellt sicher, dass Modelle, die mit synthetischen Daten trainiert wurden, ähnlich funktionieren wie solche, die mit realen Daten trainiert wurden, was sie zu einer praktikablen Alternative für viele ML-Workflows macht. Der Schlüssel liegt darin, Nutzen und Datenschutz abzuwägen und sicherzustellen, dass die synthetischen Daten für ihren beabsichtigten Zweck nützlich genug sind, während sie starke Garantien gegen Re-Identifizierung bieten.
Federated Analysis: Lernen ohne Zentralisierung
Federated Analysis, einschließlich ihrer spezifischeren Anwendung im Federated Learning, stellt eine weitere kritische PET für verteilte Datenumgebungen dar. Anstatt Rohdaten aus mehreren Quellen (z. B. verschiedenen Geräten, Organisationen oder geografischen Regionen) an einem Ort für Analysen oder Modelltraining zu zentralisieren, bringen föderierte Methoden die Berechnung zu den Daten. Beim Federated Learning wird beispielsweise ein globales Modell trainiert, indem die Modellparameter an lokale Geräte oder Datensilos gesendet werden. Jede lokale Entität trainiert das Modell mit ihren privaten Daten, und nur die aktualisierten Modellparameter (oder Gradienten) werden an einen zentralen Server zurückgesendet, wo sie aggregiert werden, um das globale Modell zu verbessern. Die Rohdaten verlassen niemals ihren ursprünglichen Speicherort.
Dieser Ansatz ist besonders wertvoll für Szenarien, die hochsensible Daten betreffen, die über viele Endpunkte verteilt sind, wie z. B. Krankenakten in verschiedenen Krankenhäusern oder Benutzerdaten auf einzelnen Mobilgeräten. Er ermöglicht kollaborative Analysen und Modelltraining über verschiedene Datensätze hinweg, ohne die immensen Datenschutz- und logistischen Herausforderungen der Zusammenführung von Rohdaten. Federated Analysis unterstützt von Natur aus die Datensouveränität und minimiert das Risiko groß angelegter Datenlecks, da keine einzelne Entität jemals alle Rohinformationen besitzt.
PETs als neue Grundlage der Datenarchitektur
Die Integration dieser Privacy-Enhancing Technologies bedeutet einen grundlegenden Wandel in der Art und Weise, wie Organisationen Daten-Governance und -Nutzung angehen. Sie sind nicht länger nur „Nice-to-have“-Sicherheitsfunktionen oder komplexe akademische Kuriositäten. Stattdessen werden PETs zur technischen Architektur, die es Unternehmen ermöglicht, sensible Daten unter zunehmend strengen Datenschutz-, Datensouveränitäts- und AI governance-Erwartungen effektiv weiter zu nutzen. Dies bedeutet, dass Datenarchitekten, Ingenieure und Datenschutzbeauftragte zunehmend Lösungen wie Confidential Computing, Data Clean Rooms, Synthetic Data-Generierung und Federated Analysis als Standardkomponenten ihrer Dateninfrastruktur verstehen und implementieren müssen.
Die Zukunft datengesteuerter Innovation hängt von der Fähigkeit ab, aus sensiblen Informationen verantwortungsvoll Wert zu schöpfen. PETs bilden die entscheidende Brücke zwischen Datennutzen und Datenschutz. Da diese Technologien reifen und durch Angebote von Cloud-Anbietern und Open-Source-Initiativen zugänglicher werden, wird ihre Akzeptanz beschleunigt, wodurch die Art und Weise, wie Daten in allen Branchen gesammelt, verarbeitet, geteilt und analysiert werden, grundlegend neu gestaltet wird. Die Ära der Zentralisierung von Rohdaten ohne Konsequenzen neigt sich dem Ende zu; die Ära der intelligenten, datenschutzfreundlichen Dateninfrastruktur beginnt gerade erst.