Platform Engineering ersetzt DevOps — Was das 2026 tatsächlich bedeutet
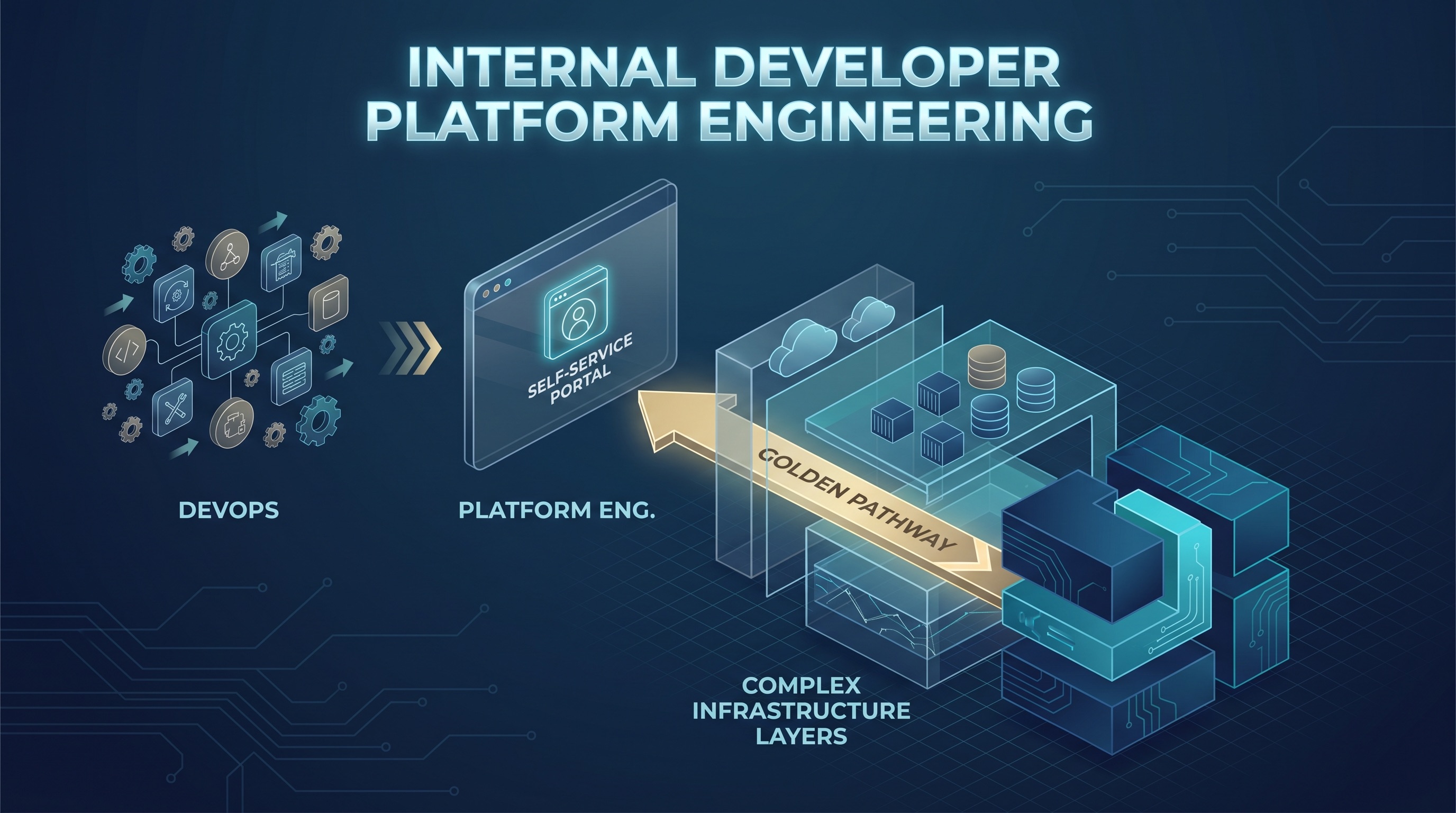
Als Unternehmen vor einem Jahrzehnt DevOps einführten, war das Versprechen kultureller Natur: Entwickler und Betriebsingenieure sollten zusammenarbeiten und die Mauer zwischen „wir schreiben es“ und „du betreibst es“ einreißen. Was viele Organisationen stattdessen bekamen, war jeder Entwickler, der zum Teilzeit-Infrastrukturingenieur wurde – Bereitschaftsdienste, Kubernetes-Debugging um Mitternacht, Verwalten von Terraform-State-Drift, wenn sie eigentlich Features ausliefern wollten. Die Mühe, die DevOps versprach zu beseitigen, wanderte von den Ops-Teams zu den Entwicklungsteams.
Platform Engineering ist die Korrektur. Anstatt jedem Entwickler zuzumuten, Infrastruktur zu verstehen, baut Platform Engineering ein dediziertes internes Team, dessen einzige Aufgabe es ist, die Infrastrukturabstraktionen, Tools und Workflows zu schaffen, die andere Entwickler als Service konsumieren. Das Ziel ist ein Self-Service-System, das so gut konzipiert ist, dass Anwendungsentwickler ihre Dienste bereitstellen, skalieren und überwachen können, ohne verstehen zu müssen, was darunter läuft. Der Unterschied klingt subtil, aber die organisatorischen Konsequenzen sind signifikant.
Was eine Internal Developer Platform eigentlich ist
Eine Internal Developer Platform (IDP) ist das Produkt, das Platform-Engineering-Teams bauen. Es ist kein einzelnes Tool – es ist eine kuratierte Schicht aus Abstraktionen, automatisierten Workflows und Self-Service-Schnittstellen, die zwischen den Entwicklern und der zugrunde liegenden Infrastruktur (Cloud-Provider, Kubernetes-Cluster, Datenbanken, Sicherheitskontrollen, Monitoring-Systeme) sitzt.
Eine ausgereifte IDP bietet typischerweise:
- Service Templates / Scaffolding: Meinungsstarke Startpunkte für neue Services (Microservice-Template, ML-Model-Serving-Template, Daten-Pipeline-Template) mit sinnvollen Standardeinstellungen für CI/CD, Logging, Monitoring und Sicherheit, die bereits eingebunden sind
- Self-Service-Umgebungen: Entwickler können Dev-/Staging-Umgebungen provisionieren, ohne Tickets einzureichen oder auf Ops-Freigabe zu warten – die Plattform erzwingt automatisch Guardrails
- Deployment-Workflows: Ein „In Produktion deployen“-Button, der automatisierte Tests ausführt, Sicherheitsrichtlinien prüft, Canary- oder Blue/Green-Traffic-Splitting anwendet und zurückrollt, wenn die Fehlerraten ansteigen – ohne dass der Entwickler etwas davon verwalten muss
- Service Catalog: Ein durchsuchbares Inventar aller Services, ihrer Besitzer, ihrer Abhängigkeiten, ihrer SLAs und ihrer Runbooks – das Problem des informellen Wissens wird reduziert
- Observability out of the box: Jeder neue Service sendet automatisch Standard-Metriken, Logs und Traces; Entwickler instrumentieren nicht von Grund auf
Das entscheidende Konzept ist der Golden Path: der empfohlene Weg, um die häufige Aufgabe (einen Service deployen, eine Datenbank hinzufügen, einen Cron-Job einrichten) zu erledigen. Der Golden Path ist meinungsstark und automatisiert. Entwickler, die ihm folgen, müssen die Details nicht verstehen – die Plattform erledigt das. Entwickler, die abweichen müssen, können das tun, aber sie verlassen dann das automatisierte Sicherheitsnetz.
Backstage: Die Open-Source-Grundlage
Spotify hat Backstage 2020 als Open Source veröffentlicht, nachdem es intern genutzt wurde, um das Service-Catalog- und Developer-Portal-Problem in großem Maßstab zu lösen. Es ist jetzt ein CNCF-Inkubationsprojekt und ist zur De-facto-Grundlage für IDPs in großen Unternehmen geworden: Schätzungsweise 80 % der Fortune-100-Unternehmen haben damit experimentiert, und mehrere hundert Unternehmen haben Produktionsinstanzen bereitgestellt.
Backstage bietet ein plugin-basiertes Developer Portal mit einem Software Catalog im Kern. Es katalogisiert sofort einsatzbereit Services, APIs, Dokumentation, Teams und Infrastrukturkomponenten. Plugins erweitern es, um sich in Kubernetes, CI/CD-Systeme, Cloud-Provider, Incident-Management-Tools und Dutzende anderer Systeme zu integrieren. Das Ergebnis ist eine Single Pane of Glass, in der ein Entwickler jeden Service finden, dessen Besitzer verstehen, auf dessen Dokumentation zugreifen, seine Gesundheit überprüfen und Deployments auslösen kann – ohne zwischen 12 verschiedenen Tools hin- und herwechseln zu müssen.
Die Schwäche von Backstage ist, dass es im Grunde ein Frontend und ein Catalog ist. Es stellt keine Infrastruktur bereit oder orchestriert Deployments von selbst – diese Fähigkeiten erfordern Integrationen mit zugrunde liegenden Systemen (Terraform, Crossplane, Argo CD, GitHub Actions) und die Expertise, sie miteinander zu verbinden. Deshalb ist ein sekundärer Markt von Backstage-as-a-Service-Anbietern entstanden: Roadie, Port und Cortex bieten alle gehostete oder erweiterte Versionen des IDP-Konzepts an, die auf Teams abzielen, die die Vorteile ohne den Backstage-Wartungsaufwand nutzen möchten.
Team Topologies und warum diese Reorganisation wichtig ist
Das Organisationsmodell hinter Platform Engineering verdankt viel dem Buch Team Topologies von Matthew Skelton und Manuel Pais (2019), das einen Rahmen für Teamstrukturen in Softwareorganisationen einführte. Die hier relevante zentrale Einsicht ist die Unterscheidung zwischen stream-aligned teams (Teams, die direkt Nutzern Mehrwert liefern, organisiert nach Geschäftsdomänen) und platform teams (Teams, die die kognitive Last für stream-aligned Teams reduzieren, indem sie zuverlässige interne Dienste bereitstellen).
Traditionelles DevOps integrierte Infrastrukturwissen in jedes Team. Platform Engineering extrahiert dieses Wissen in ein dediziertes Team, das über klar definierte APIs und Self-Service-Tools mit anderen Teams interagiert – nicht über Ad-hoc-Anfragen und Besprechungen. Stream-aligned Teams erhalten schnelleren und zuverlässigeren Infrastrukturzugang. Platform Teams bauen etwas mit Hebelwirkung – eine Fähigkeit, die ein Team aufbaut und von der zehn andere profitieren.
Der organisatorische Wandel ist wichtig, weil er Anreize verändert. Das Erfolgsmaß eines Platform Teams ist die Developer Experience und die Akzeptanz, nicht die Schließung von Tickets. Sie bauen für interne Kunden. Das führt zu besser designten Tools als bei Betriebsteams, deren Anreiz die Verfügbarkeit bestimmter Systeme ist.
Was die Daten zeigen
Die CNCF Platform Engineering Survey 2025 ergab, dass 78 % der Organisationen mit mehr als 500 Ingenieuren Platform Engineering entweder übernommen hatten oder aktiv implementierten. Die DORA (DevOps Research and Assessment)-Metriken, die die Leistung der Softwareauslieferung messen, zeigen durchweg, dass Organisationen mit ausgereiften internen Plattformen ihre Mitbewerber in Bezug auf Deployment-Frequenz (wie oft Code ausgeliefert wird), Durchlaufzeit für Änderungen (wie lange vom Commit bis zur Produktion), Änderungsfehlerrate und mittlere Wiederherstellungszeit übertreffen.
Spezifische Fallstudiendaten sind zum Zeitpunkt der Veröffentlichung schwerer zu finden, da die meisten Organisationen ihre Plattform als Wettbewerbsvorteil betrachten, aber Shopify, Lyft, Airbnb und Stripe haben alle öffentlich über die Produktivitätsgewinne durch Investitionen in interne Plattformen berichtet. Shopifys Platform Engineering-Investitionen in den Jahren 2022–2023 wurden als Schlüsselfaktor für eine 33%ige Verbesserung des Entwickler-Deployment-Durchsatzes genannt. Lyft reduzierte die Zeit für das Onboarding neuer Services von Wochen auf unter einen Tag.
Die Cloud-Abstraktionsschicht
Moderne IDPs abstrahieren zunehmend die Besonderheiten der Cloud-Provider. Ein Entwickler, der einen neuen Service deployt, sollte nicht wissen müssen, welche Cloud-Region sein Unternehmen verwendet, wie man VPCs konfiguriert oder welche IAM-Rolle zugewiesen werden muss. Plattformen, die auf Crossplane (einem Kubernetes-nativen Tool zur deklarativen Verwaltung von Cloud-Ressourcen) oder Terraform-Abstraktionen basieren, können eine einfache Schnittstelle bereitstellen – „Gib mir eine Postgres-Datenbank mit diesen Spezifikationen“ – während die Plattform die eigentliche Cloud-Ressource provisioniert, Sicherheitsrichtlinien anwendet, Monitoring hinzufügt und die Abhängigkeit im Catalog aufzeichnet.
Diese Abstraktion hat einen strategischen Vorteil, der über die Developer Experience hinausgeht: Sie reduziert die Cloud-Lock-in auf der Anwendungsebene. Wenn Entwickler über eine IDP-Schnittstelle statt direkt über AWS-APIs interagieren, ist die Migration der zugrunde liegenden Infrastruktur ein Problem des Platform Teams und keine unternehmensweite Neuschreibung. Organisationen, die auf Plattformabstraktionen aufbauten, stellten fest, dass ihre Cloud-Migrationen zur Kostensenkung während der Pandemie signifikant einfacher waren als diejenigen, die dies nicht taten.
Wann Platform Engineering Sinn ergibt – und wann nicht
Platform Engineering hat Einrichtungskosten. Das Bauen und Betreiben einer IDP ist echte Produktentwicklungsarbeit, und die Kapitalrendite erfordert genügend Teams, die die Plattform nutzen, um die Investition zu rechtfertigen. Der Wendepunkt, ab dem Platform Engineering finanziell sinnvoll wird, wird allgemein bei 50–100 Ingenieuren angesetzt, obwohl stark fragmentierte Tech-Stacks es auch früher rechtfertigen können.
Unterhalb dieser Schwelle überwiegt der Aufwand für das Bauen und Betreiben einer IDP wahrscheinlich die Produktivitätsgewinne. Ein 10-köpfiges Startup sollte verwaltete Cloud-Dienste und Standard-CI/CD-Tooling nutzen, nicht interne Abstraktionen bauen. Der Fehler, den viele wachsende Unternehmen machen, ist zu langes Warten – sie versuchen, Platform Engineering einzuführen, wenn sie bereits 300 Ingenieure haben, ein Jahrzehnt an angehäufter heterogener Tooling-Landschaft und tief verwurzelte „Frag einfach das Infra-Team“-Gewohnheiten.
Handlungsempfehlungen
- Beginnen Sie mit dem Service Catalog, nicht mit der Deployment-Pipeline: Der schnellste Gewinn für die meisten Organisationen ist, Entwicklern ein durchsuchbares, aktuelles Inventar davon zu geben, was existiert und wer es besitzt. Backstage, nur mit dem Catalog-Plugin bereitgestellt, liefert sofortigen Mehrwert und baut die Grundlage für alles andere.
- Goldene Pfade schlagen Vorschriften: Entwickler zur Standardisierung zu zwingen, erzeugt Widerstand. Den Standardpfad wirklich einfacher zu machen als Alternativen schafft Akzeptanz. Bauen Sie zuerst den Happy Path, dann verbessern Sie ihn basierend darauf, wo Entwickler abweichen.
- Messen Sie die Developer Experience explizit: SPACE-Metriken (Satisfaction, Performance, Activity, Communication, Efficiency) oder ähnliche Frameworks geben Platform Teams eine Feedback-Schleife. Zählen Sie nicht nur Ticket-Schließungen.
- Bauen Sie nicht, was Sie kaufen können: Das Backstage-SaaS-Ökosystem (Roadie, Port, Cortex) ist deutlich gereift. Für Teams ohne dedizierte Platform Engineers ist eine verwaltete Lösung wahrscheinlich schneller und billiger als das Self-Hosting von Backstage und das Erstellen von Plugins von Grund auf.
- Das Platform Team braucht Produktinstinkte: Der häufigste Fehlermodus ist ein Platform Team, das baut, was es denkt, dass Entwickler brauchen, anstatt was Entwickler tatsächlich wollen. Behandeln Sie interne Entwickler als Kunden. Führen Sie User Research durch. Priorisieren Sie Akzeptanzmetriken.