KI-Crawler Verwandeln Offene Websites in Infrastrukturziele
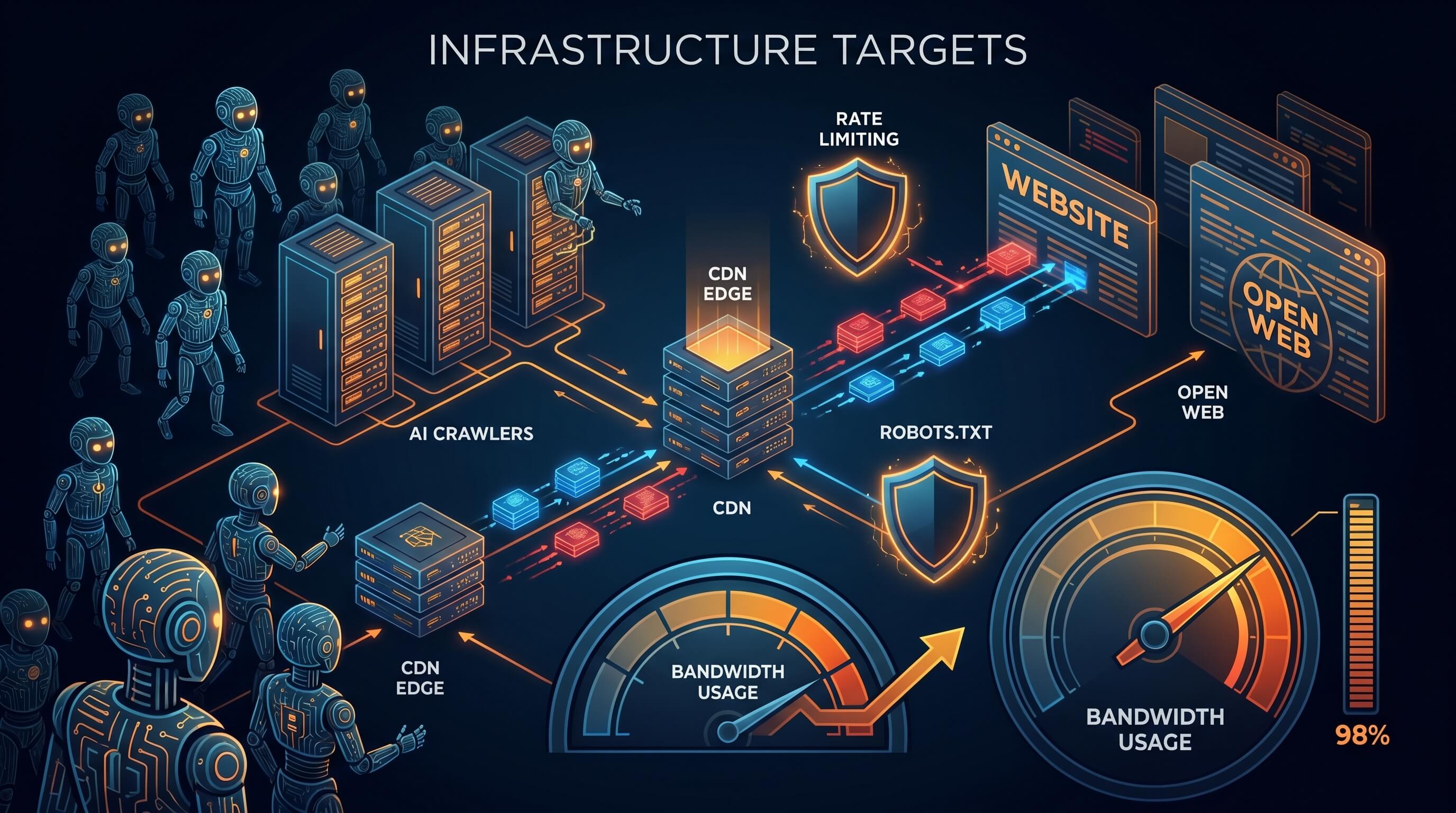
Lange Zeit beruhte das offene Web auf einem einfachen Tausch. Man veröffentlichte Inhalte öffentlich, Suchmaschinen indexierten sie, und menschliche Besucher kamen über Suche, Links und Empfehlungen. Dieses Modell gerät unter Druck. KI-Crawler greifen offene Websites heute in maschineller Größenordnung an und verbrauchen dabei oft deutlich mehr Infrastruktur, als sie an menschlichem Traffic zurückbringen.
Die praktische Folge ist, dass viele Websites zunehmend wie Infrastrukturziele behandelt werden, nicht nur wie Publikationen. CDN-Rechnungen steigen, Origin-Server werden stärker belastet, und robots.txt wirkt immer häufiger wie eine höfliche Bitte statt wie ein wirksames Steuerungsinstrument.
Warum sich KI-Crawling anders anfühlt als klassisches Such-Crawling
Klassisches Suchmaschinen-Crawling war nie kostenlos, aber die Gegenleistung war nachvollziehbar. Indexierung brachte Sichtbarkeit und potenziellen Traffic. Bei KI-Crawlern wird diese Beziehung schwächer. Anbieter crawlen für Training, Retrieval oder Antwortsysteme, ohne proportionalen Besucherstrom zur Quelle zurückzuschicken.
Wenn ein Bot große Datenmengen verbraucht und kaum Referrals erzeugt, verhält er sich eher wie ein Extraktor als wie ein Discovery-Partner.
CDN-Kosten werden zum redaktionellen Problem
Steigt der Bot-Traffic, ist Infrastruktur kein reines Backend-Thema mehr. Sie beeinflusst Veröffentlichungsentscheidungen. Ein Fachblog, Forum oder öffentliches Wissensarchiv kann nur ein kleines menschliches Publikum haben, aber sehr viele crawlbare Seiten bereitstellen.
Dadurch wird die Seite teurer im Betrieb, ohne für ihre eigentliche Leserschaft wertvoller zu werden. Das kann Betreiber in Richtung Loginschranken, Challenge-Seiten oder schärferer Blockierregeln drängen.
robots.txt verliert seinen alten gesellschaftlichen Vertrag
robots.txt war immer freiwillig und nie eine echte Sicherheitsgrenze. Trotzdem funktionierte es erstaunlich gut, weil große Crawler ein Interesse an berechenbarem Verhalten hatten. Diese Erwartung erodiert.
Viele Betreiber gehen inzwischen davon aus, dass einige Agenten robots.txt ignorieren, mit neuen Kennungen zurückkehren oder die Regeln nur eng auslegen. Selbst formale Compliance garantiert weder wirtschaftliche Gegenleistung noch sinnvolle Attribution.
Rate Limiting wird zur Standardhaltung
Viele Websites nutzten Rate Limiting früher nur bei Missbrauch oder zum Schutz von Login-Systemen. Jetzt wird es zu einer grundlegenden Steuerung für öffentliche Inhalte. Teams begrenzen offene Endpunkte stärker, bewerten Bots genauer und stoppen verdächtige Muster vor dem Origin.
Das hat Nebenwirkungen. Zu harte Grenzen können legitime Automatisierung, Forschung, Barrierefreiheit und sogar nützliche Suchmaschinen beeinträchtigen. Ziel ist deshalb nicht pauschales Blockieren, sondern ökonomisch planbares Crawling.
Das eigentliche Problem ist Asymmetrie
Große KI-Unternehmen können Crawling-Kosten über riesige Plattformen verteilen und als strategischen Input behandeln. Kleine Publisher können Verteidigungskosten nicht in gleicher Weise verteilen. Jedes zusätzliche Terabyte, jede WAF-Anpassung und jede Engineering-Stunde trifft sie direkt.
Deshalb droht das offene Web zu einer Subventionsschicht für KI-Systeme zu werden. Die Inhalte bleiben öffentlich, aber die Kosten der Offenheit tragen die Publisher, während ein wachsender Anteil des nachgelagerten Werts anderswo anfällt.
Was Website-Betreiber jetzt tun sollten
Bot-Kosten getrennt messen
Erfassen Sie Bandbreite, Request-Volumen, Cache-Misses und Origin-Last nach Bot-Klassen, soweit möglich.
Teure Crawl-Flächen reduzieren
Prüfen Sie Archive, interne Suche, URL-Dubletten, Paginierung und wenig wertvolle Pfade.
Schutz näher an den Edge verlagern
Nutzen Sie CDN- und WAF-Kontrollen, um wiederholten Traffic abzufangen, bevor er den Origin erreicht.
Explizite Zugriffsstufen definieren
Nicht alles muss nur offen oder geschlossen sein. Zugriff mit hohem Volumen kann API-Schlüssel, Quoten oder kommerzielle Bedingungen verlangen.
Die Richtlinie dokumentieren
Veröffentlichen Sie neben robots.txt eine klare Crawl- und Lizenzpolitik, um Durchsetzung und Verhandlung besser zu stützen.
Das offene Web braucht jetzt ökonomische Verteidigung
KI-Crawler sind keine vorübergehende Störung. Sie verändern das Kostenmodell öffentlichen Publizierens. Die praktische Konsequenz lautet: Bot-Last messen, unnötige Crawl-Flächen reduzieren, Limits am Edge durchsetzen und volumenstarken Zugriff an klare Bedingungen knüpfen.
Die nächste Phase des Webs wird nicht nur davon geprägt sein, was veröffentlicht wird, sondern auch davon, wer es sich leisten kann, offen zu bleiben.